







本文以天池比赛《车辆贷款违约预测》的数据为例,通过pandas处理数据,构建联邦学习数据,用于FATE框架联邦学习。
通过pandas处理数据
1. 读取数据
下载car_loan_train.csv数据后,用pandas读取数据。
import pandas as pd
data=pd.read_csv("car_loan_train.csv")2. 查看所有列名及数据行数
print(data.columns)
print(data.shape[0])
3. 查看每列数据最大值及最大值所在行
print(data.max())
print(data.idxmax())
4. 查看data的统计信息
包括count、mean、std、max、min等
data.describe()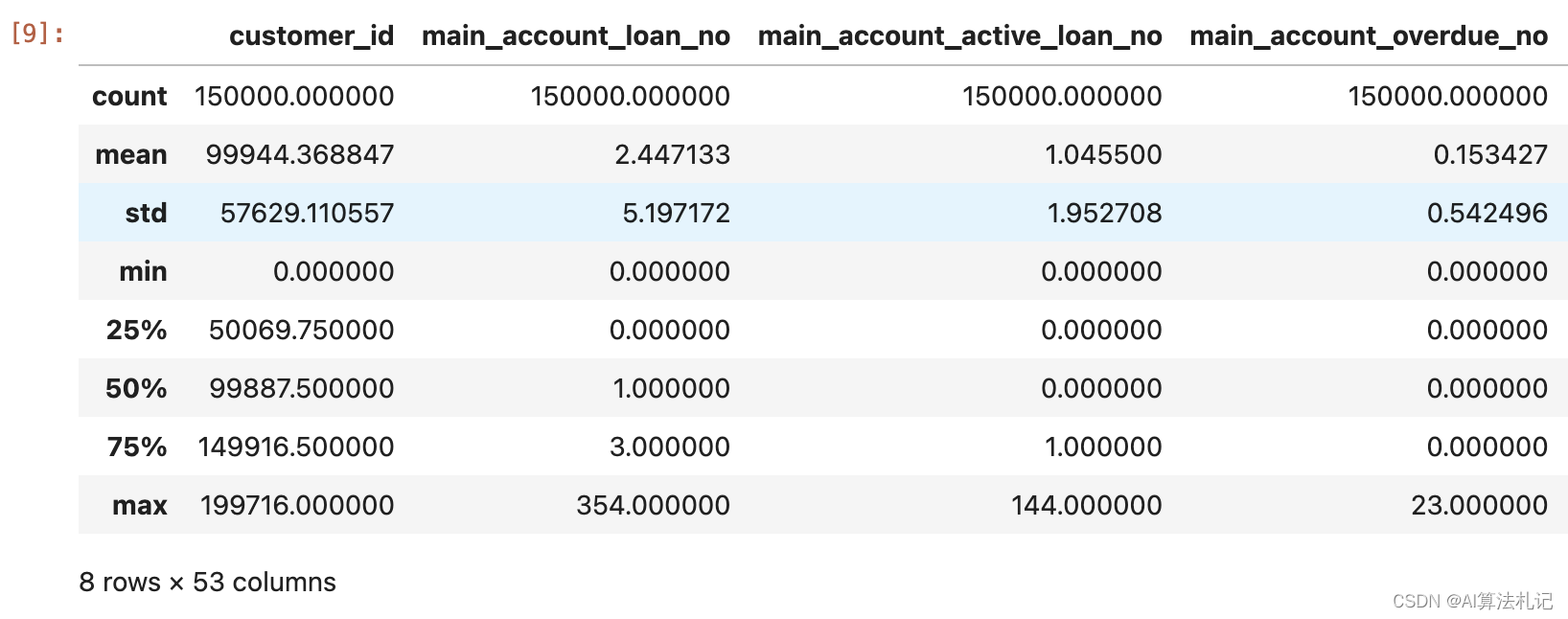
5. 按规则删除特定行
遍历数据的每一列,删除存在>=1e9数据的行。这里先获取值>=1e9所在行的索引,然后根据索引删除行。
for column in data.columns:
print(data.shape[0])
data=data.drop(index=data[str(column)][data[str(column)]>=1e9].index) 6. 删除部分无用的特征
data.drop(labels=["customer_id","disbursed_date","loan_default","mobileno_flag","idcard_flag","outstanding_disburse_ratio"],axis=1)7. 数据归一化
features = ['main_account_loan_no', 'main_account_active_loan_no',
'main_account_overdue_no', 'main_account_outstanding_loan',
'main_account_sanction_loan', 'main_account_disbursed_loan',
'sub_account_loan_no', 'sub_account_active_loan_no',
'sub_account_overdue_no', 'sub_account_outstanding_loan',
'sub_account_sanction_loan', 'sub_account_disbursed_loan',
'disbursed_amount', 'asset_cost', 'branch_id', 'supplier_id',
'manufacturer_id', 'area_id', 'employee_code_id', 'Driving_flag', 'passport_flag', 'credit_score',
'main_account_monthly_payment', 'sub_account_monthly_payment',
'last_six_month_new_loan_no', 'last_six_month_defaulted_no',
'average_age', 'credit_history', 'enquirie_no', 'loan_to_asset_ratio',
'total_account_loan_no', 'sub_account_inactive_loan_no',
'total_inactive_loan_no', 'main_account_inactive_loan_no',
'total_overdue_no', 'total_outstanding_loan', 'total_sanction_loan',
'total_disbursed_loan', 'total_monthly_payment', 'main_account_tenure',
'sub_account_tenure', 'disburse_to_sactioned_ratio',
'active_to_inactive_act_ratio', 'year_of_birth',
'Credit_level', 'employment_type', 'age']
data[features] = (data[features]-data[features].mean())/(data[features].std())8. 创建索引
data['idx']=range(data.shape[0])9. 打乱数据
data=data.sample(frac=1)10.划分训练集、测试集
因为用于联邦学习,将训练数据分为两部分。
train=data.iloc[:int(data.shape[0]*0.2)]
loan_eval=data.iloc[int(data.shape[0]*0.8):]
loan_1_train=train.iloc[:int(train.shape[0]*0.5)]
loan_2_train=train.iloc[int(train.shape[0]*0.5):]
print(train.shape)
print(loan_eval.shape)
print(loan_1_train.shape)
print(loan_2_train.shape)11. 保存数据
loan_1_train.to_csv("loan_1_train.csv",index=False,header=True)
loan_2_train.to_csv("loan_2_train.csv",index=False,header=True)
loan_eval.to_csv("loan_eval.csv",index=False,header=True)参考资料
[1] 车辆贷款违约预测(讯飞A.I算法赛)_数据集-阿里云天池
[2] 轻松入门联邦学习开源框架Fate














 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









