







我们知道postgresql数据库通过数据多版本实现mvcc,pg又没有undo段,老版本的数据元组直接存放在数据页面中,这样带来的问题就是旧元组需要不断地进行清理以释放空间,这也是数据库膨胀的根本原因。
本文简单介绍一下postgresql数据库的元组、页面的结构以及索引查找流程。
元组结构
元组,也叫tuple,这个叫法是很学术的叫法,但是现在数据库中一般叫行或者记录。下面是元组的结构:
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */
#define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
#define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};

t_xmin:代表插入此元组的事务xid;
t_xmax:代表更新或者删除此元组的事务xid,如果该元组插入后未进行更新或者删除,t_xmax=0;
t_cid:command id,代表在当前事务中,已经执行过多少条sql,例如执行第一条sql时cid=0,执行第二条sql时cid=1;
t_ctid:保存着指向自身或者新元组的元组标识(tid),由两个数字组成,第一个数字代表物理块号,或者叫页面号,第二个数字代表元组号。在元组更新后tid指向新版本的元组,否则指向自己,这样其实就形成了新旧元组之间的“元组链”,这个链在元组查找和定位上起着重要作用。
了解了元组结构,再简单了解下元组更新和删除过程。
更新过程

上图中左边是一条新插入的元组,可以看到元组是xid=100的事务插入的,没有进行更新,所以t_xmax=0,同时t_ctid指向自己,0号页面的第一号元组。
右图是发生xid=101的事务更新该元组后的状态,更新在pg里相当于插入一条新元组,原来的元组的t_xmax变为了更新这条事务的xid=101,同时t_ctid指针指向了新插入的元组(0,2),0号页面第二号元组,第二号元组的t_xmin=101(插入该元组的xid),t_ctid=(0,2),没有发生更新,指向自己。
删除过程

上图代表该元组被xid=102的事务删除,将t_xmax设置为删除事务的xid,t_ctid指向自己。
页面结构
下面再来看看页面的结构
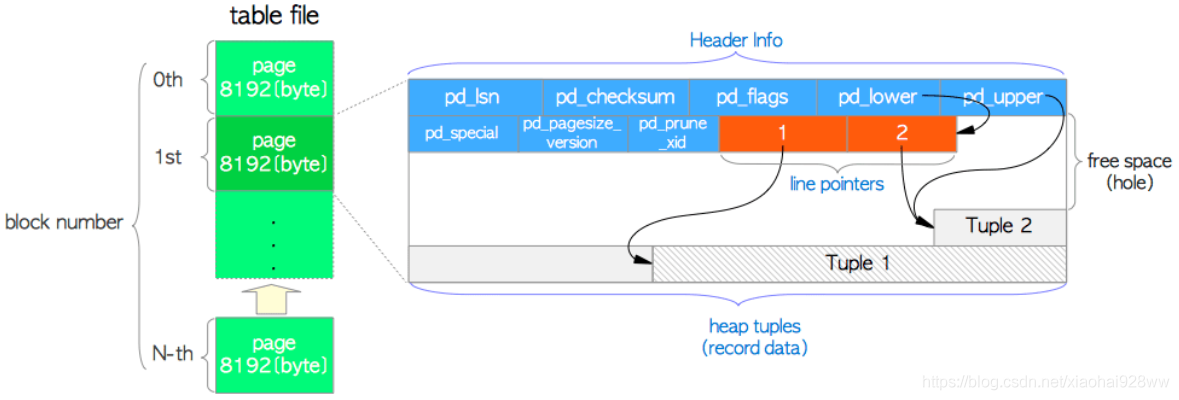
从上图可以看到,页面包括三种类型的数据
1.header data:数据头是page生成的时候随之产生的,由pageHeaderData定义结构,24个字节长,包含了page的相关信息,下面是数据结构:
typedef struct PageHeaderData
{
/* XXX LSN is member of *any* block, not only page-organized ones */
PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog
* record for last change to this page */
uint16 pd_checksum; /* checksum */
uint16 pd_flags; /* flag bits, see below */
LocationIndex pd_lower; /* offset to start of free space */
LocationIndex pd_upper; /* offset to end of free space */
LocationIndex pd_special; /* offset to start of special space */
uint16 pd_pagesize_version;
TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array */
} PageHeaderData;
pd_lsn: 存储最近改变该页面的xlog位置。
pd_checksum:存储页面校验和。
pd_lower,pd_upper:pd_lower指向行指针(line pointer)的尾部,pd_upper指向最后那个元组。
pd_special: 索引页面中使用,它指向特殊空间的开头。
2.line pointer:行指针,四字节,每一条元组会有一个行指针指向真实元组位置。
3.heap tuple:存放真实的元组数据,注意元组是从页面的尾部向前堆积的,元组和行指针之间的是数据页的空闲空间。
索引查找
看了页面和元组结构,再看看索引的结构。

以上图为例,索引的数据包含两部分(key=xxx,TID=(block=xxx,offset=xxx)),key表示真实数据,tid代表指向数据行的指针,具体block代表页面号,offset代表行偏移量,指向数据页面的line pointer,比如执行下面的查询语句
select * from tbl where id=1000;
key=1000,根据key值在索引中找到tid为5号页面的1号元组,再通过一号元组行指针找到元组1,检查元组1的t_ctid字段,发现指向了新的元组2,于是定位到真实元组数据2。














 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









