







今日内容
- 线程池
- Executor
- ExecutorService
- Executors
- 死锁
- 线程的状态
- wait()等待
- notify()唤醒
- 定时器Timer
- Lambda表达式
- Stream
- 单列集合获取流
- 双列集合获取流
- forEach
- filter
- Count
- Linit
- skip
- concat
- Map
- 收集到数组、集合
第一章 线程池方法
1.思想
我们之前使用多线程每次使用线程时都会创建一个新的线程,然后使用该线程去执行任务,这个线程执行完任务后就会销毁(退出)。这样频繁创建以及销毁线程对性能的影响是非常大的。
如果要解决这个问题,我们可以预先创建很多线程然后将这些线程放到一个容器中,如果以后要使用线程,直接从这个容器中获取线程,然后使用。如果用完了这个线程,那么就再把这个线程给放回去。以后再使用线程,直接从这个容器中拿即可。这样就避免了频察创建以及销级线程带来的性能问题。
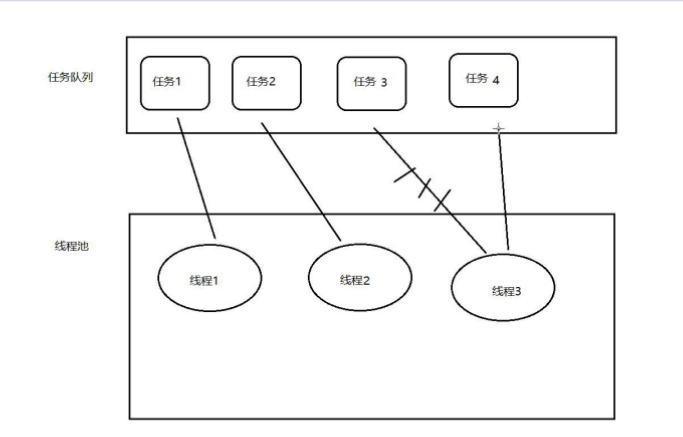
这个容器java已经为我们提供,就是线程池。线程池就是一个容器,里面已经创建好许多线程,如果我们要使用,直接通过线程池去使用即可。
2.概念
其实就是一个容纳多个线程的容器,其中的线程可以反复使用,省去了频繁创建线程对象的操作, 无需反复创建线程而消耗过多资源。
线程池就是一个容器,里面有很多线程,里面的每一个线程都可以去多次执行任务。
线程池相关API
Executor:接口,该接收是线程池的根接口。这个接口中提供了提交线程任务的方法。
ExecutorService:是Executor的子接口,也表示线程池。里面除了提供了执行线程任务的方法,还提供了管理线程池的方法
Executors:线程的工具类。里面提供获取线程池的方法。
注意:线程池不是我们自己创建的。而是通过Execcutors进行获取的。
Executors获取线程池的方法:
static ExecutorService newFixedThreadpool(int nThreads):创建一个定长的线程池,参数表示线程池的长度。
ExecutorService表示线程池,里面有一些方法。
submit(Runnable task):提交线程任务并执行.
shutdown():销毁线程池.
3.使用[掌握]
线程池的使用步骤:
1.调用Executors的newFixedThreadPooL方法获取线程池。
2.定义一个Runnable实现类,表示线程任务
3.通过线程池调用submit,传递Runnable接口的实现类对象,执行线程任务。
4.销毁线程池(一般不做,频繁创建销毁对性能影响更大)
线程池创建的线程索引从1开始
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Demo01ThreadPool {
public static void main(String[] args) {
// 调用Executors的newFixedThreadPooL方法获取线程池。
// 长度为2
ExecutorService threadPool = Executors.newFixedThreadPool(2);
// 定义一个Runnable实现类,表示线程任务
Task task = new Task();
// 通过线程池调用submit,传递Runnable接口的实现类对象,执行线程任务。
threadPool.submit(task);
threadPool.submit(task);
threadPool.submit(task);//等线程空闲出来再执行
// 销毁线程池
threadPool.shutdown();
}
}
4.多线程的第三种实现方式(了解)
步骤:
1.定义类,然后实现Callable接口。
2.重写Callable接口中的caLL方法,在caLL方法中定义线程要执行的任务
3.获取一个线程池【该方式完成多线程必须要有线程池】
4.调用线程池的submit方法,传递CaLLabLe接口的实现类对象,执行线程任务。
5.处理结果
线程池的submit方法:
Future submit(Callable task):提交线程任务。返回值Future类型,表示将来线程运行后产出的结果。
Future里面封装了线程执行后的结果:
V get():获取线程执行结果[如果线程没有执行结束,get方法就会等着线程执行完毕]
// 实现接口
import java.util.concurrent.Callable;
public class CallableImpl implements Callable<String> {
// call方法中定义线程要执行的任务,该方法的返回值就是线程执行后产出的结果。
public String call() throws Exception {
for (int i = 0; i < 100; i++) {
System.out.println("helloworld");
}
return "执行完成";
}
}
// 测试类
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Demo01Callable {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 获取一个线程池
ExecutorService threadPool = Executors.newFixedThreadPool(2);
// 调用线程池的submit方法,传递CaLLabLe接口的实现类对象,执行线程任务。
Future<String> future = threadPool.submit(new CallableImpl());
// 调用get方法获取返回值
String s = future.get();
System.out.println(s);
}
}
第二章 死锁
1.介绍
1.1什么是死锁
多个线程各自持有锁且等待其他线程释放锁.
在多线程程序中,使用了多把锁,造成线程之间相互等待,程序不往下走了。
1.2死锁产生的条件
1.有多把锁 2.有多个线程 3.有同步代码块嵌套
2.死锁演示
- 锁类
public class Locks {
// 创建2给对象,表示2个锁
public static Object locka = new Object();
public static Object lockb = new Object();
}
- 进程类
public class MyThreadA extends Thread{
public void run() {
synchronized (Locks.locka){
System.out.println("A进程------a");
synchronized (Locks.lockb){
System.out.println("A进程-----b");}
}
}
}
public class MyThreadB extends Thread{
public void run() {
synchronized (Locks.lockb){
System.out.println("B进程------b");
synchronized (Locks.locka){
System.out.println("B进程-----a");}
}
}
}
- 测试类
public class Demo01Test {
public static void main(String[] args) {
new MyThreadA().start();
new MyThreadB().start();
}
}
// 结果
/*
B进程------b
A进程------a
(程序未结束,且不是每次执行都会出现死锁情况)
*/
第三章 线程状态
1.概述
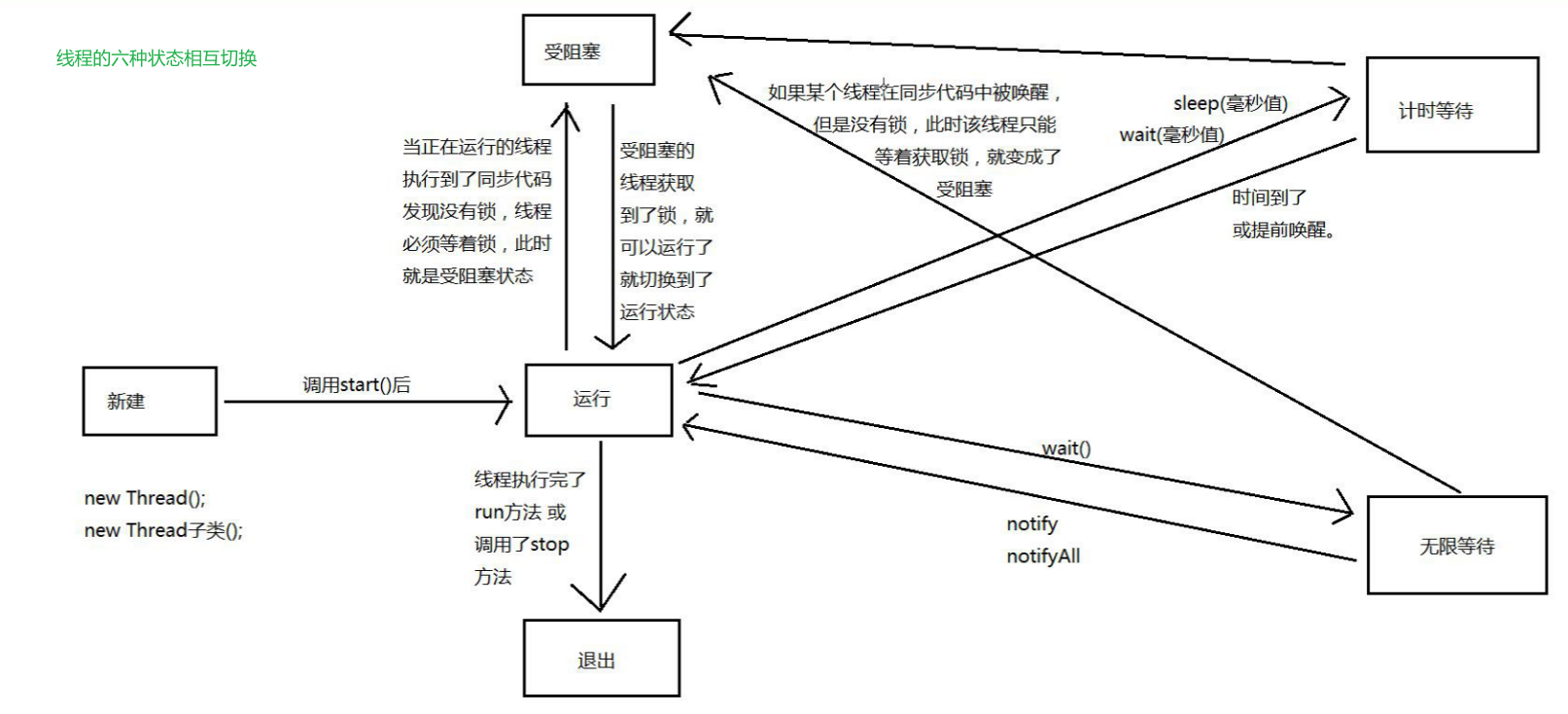
线程由生到死的完整过程:技术素养和面试的要求。 当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态。在线程的生命周期中, 有几种状态呢?在API中 java.lang.Thread.State 这个枚举中给出了六种线程状态:
这里先列出各个线程状态发生的条件,下面将会对每种状态进行详细解析
| 序号 | 线程状态 | 导致状态发生条件 |
|---|---|---|
| 1 | 新建(NEW) | 刚刚创建出来并没有调用start方法启动的线程处于新建状态。 |
| 2 | 运行(RUNNABLE) | 线程调用start方法会处于运行的状态。 |
| 3 | 受阻塞(BLOCKED) | 等待获取锁的线程处于受阻塞的状态。 |
| 4 | 无限等待(WAITING) | 当线程调用wait()方法后,处于无限等待状态【没有时间的等待,别人不叫我,我就一直等】 |
| 5 | 计时等待(TIMED_WAITING) | 当线程调用sleep(毫秒),wait(毫秒值)会进入到计时等待【有时间的等待,到了时间别人不叫我,我也会醒】 |
| 6 | 退出(TERMINATED) | 如果线程执行完了run方法,或者线程调用了stop方法 |
2.等待唤醒机制
在object中,有两种方法可以让线程等待以及喷醒线程。
void wait():让线程等待,直到有其他线程唤醒他。
void wait(long timeout):让线程等待,直到有其他线程唤醒他,或者时间到了也会自己醒。
void notify():唤醒一个等待的线程
void notifyALL():唤醒所有等待的线程。
wait方法用于等待,notify方法用于唤醒,他们一起使用,一般叫做等待唤醒机制,一般用于线程间的通信。
wait notify 是object中的方法
wait notify(同步代码块或同步方法),通过锁对象去调用。
通过哪个锁调用的notify,那么唤醒的就是通过哪个锁调用的wait等待的进程
吃包子案例
定义一个集合,包子铺线程完成生产包子,包子添加到集合中;吃货线程完成购买包子,包子从集合中移除。
当包子没有时(包子状态为false),吃货线程等待。
包子铺线程生产包子(即包子状态为true),并通知吃货线程(解除吃货的等待状态)
/*
包子类
*/
public class BaoZi {
// 属性,包子是否存在
boolean flag = false;
}
// 包子铺
public class BaoZiPu extends Thread {
//铺要使用包子,包子铺使用的包子要和吃货使用的包子是同一个。所以定义Baozi类型的变量,然后通过构造方法的方式传递进来包子对象
private BaoZi baozi;
// 定义构造方法,接收传递进来的包子,把他赋值给baozi
public BaoZiPu(BaoZi baozi) {
this.baozi = baozi;
}
// 定义线程任务
// 对于包子普来说,任务一直生成包子,等着吃货吃
public void run() {
// 死循环代表一直生产包子
while (true){
// 包子铺和吃货都有操作包子,使用线程同步保证线程安全
// 包子是唯一的,所以用作锁
synchronized (baozi){
// 如果有包子,等着吃货吃包子
if (baozi.flag){
// 等待[wait方法通过锁调用]
try {
baozi.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 如果没有包子,包子铺就要生成包子
System.out.println("生产一个大包子");
// 更改标记
baozi.flag=true;
// 叫醒吃货进程,执行吃包子任务
baozi.notify();
}
}
}
}
// 吃货
public class ChiHuo extends Thread {
private BaoZi baoZi;
public ChiHuo(BaoZi baoZi) {
this.baoZi = baoZi;
}
// 定义线程要执行的任务
// 对于本类来说,任务就是chibaoz,等着包子铺蒸包子
public void run() {
// 一直吃,用死循环
while (true){
// 吃货和包子铺操作的是同一个包子
synchronized (baoZi){
// 如果没有包子,吃货要等着生产包子
if (!baoZi.flag){
// 调用wait方法等待
try {
baoZi.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 如果有包子,要吃包子
System.out.println("吃了一个包子");
// 更改标记
baoZi.flag=false;
// 叫醒包子铺进程
baoZi.notify();
}
}
}
}
// 测试类
public class Demo01Test {
public static void main(String[] args) {
// 创建包子
BaoZi baoZi = new BaoZi();
// 创建包子铺和吃货线程
new BaoZiPu(baoZi).start();
new ChiHuo(baoZi).start();
}
}
注意
当线程调用wait方法后会等待,并且释放自己的锁.
wait:会释放自己的锁; sleep:不会释放锁.
第四章 定时器
Timer类,表示定时器,可以只执行一次,也可以周期性的执行
Timer的构造方:
Timer():空参数的构造方法
其他方法:
void schedule(TimerTask task, Long delay):指定毫秒值【deLay】后,执行任务【task】,只执行一次
void schedule(TimerTask task, Long delay,long period):指定毫秒值【deLay】后,执行任务【task】,该方法会周期性执行任务,每隔【period】执行一次.
void schedule(TimerTask task, Date time): 安排定时器在指定时间【time】执行任务【task】
void schedule(TimerTask task, Date time,long period): 安排定时器在指定时间【time】执行任务【task】,该方法会周期性执行任务,每隔【period】执行一次.
import java.util.Calendar;
import java.util.Date;
import java.util.Timer;
import java.util.TimerTask;
public class Demo01Timer {
public static void main(String[] args) {
// 创建定时器对象
Timer t = new Timer();
// 设置定时器,1秒后启动,输出内容
t.schedule(new TimerTask() {
public void run() {
System.out.println("叮咚");
}
},1000);
System.out.println("XXXX");
// 设置定时器,2秒后启动,输出内容,每秒执行一次
t.schedule(new TimerTask() {
public void run() {
System.out.println("biubiubiu");
}
},2000,1000);
// 设置定时器,指定时间执行一次.
Calendar c = Calendar.getInstance();
c.set(Calendar.HOUR_OF_DAY,11);
c.set(Calendar.MINUTE,42);
c.set(Calendar.SECOND,30);
// 转成时间对象
Date date = c.getTime();
// 设置定时,在指定时间执行
t.schedule(new TimerTask() {
public void run() {
System.out.println("指定时间到了");
}
},date);
}
}
第五章 Lambda表达式
1.冗余的匿名内部类
匿名内部类中有很多代码是冗余的
匿名内部类完成多线程的案例中
因为Thread构造方法中需要传递Runnable接口的实现类对象,所以不得不写了new Runnable
因为置名内部类中需要重写方法,重写方法时要求方法的声明部分一模一样,所以不得不写了public void run
整个匿名内部类中最重要的是方法的参数,方法体,返回值.
匿名内部类很多东西都是多余的,所以我们最好的情况就是只关注参数,方法体,返回值这三个关键字。
如果使用Lambda表达式,可以关注最核心的内容(参数,方法体,返回值),解决了匿名内部类的元余。
lambda是匿名内部类的简化写法.
lambda表达式使用的是函数式编程思想
面向对象思想:怎么
函数式编程思想:做什么
public class Demo01Inner {
public static void main(String[] args) {
// 使用匿名内部类的方法创建多线程
new Thread(new Runnable() {
public void run() {
System.out.println(Thread.currentThread().getName() + "执行了");
}
}).start();
// lambda表达式初体验
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
}).start();
}
}
2.Lambda表达式的标准格式
匿名内部类格式:
new 父类或接口(){
重写方法
}
匿名内部类有很多东西是元余的,整个匿名内部类中最核心的东西是方法的参数,方法体,以及方法的返回值。
最好的情况是关注方法的参数,方法体,以及方法的返回值这三点。
如果使用Lambda表达式只需要关注方法参数,方法体,以及返回值。
Lambda标准格式:
(参数类型 参数名) -> {
方法体;
return 返回值;
}
格式解释:
1. 小括号中的参数和之前传统方法参数写法一样,如果有多个参数,使用逗号隔开。
2. ->是一个运算符,表示指向性动作。
3. 大括号中的内容之前传统方法大括号中的内容写法一样的。
Lambda表达式可以省去面向对象中的条条框框,让我们只关注最核心的内容。
Lambda表达式是函数式编程思想,函数式编程思想中,可推导,就是可省略。
因为在Thread的构造方法中需要传递Runnable接口类型的参数,所以可以省略new Runnable。
因为Runnable中只有一个抽象方法叫做run,所以在重写该方法时可以省略public void run
public class Demo02Lambda {
public static void main(String[] args) {
// 使用匿名内部类的方法创建多线程
new Thread(new Runnable() {
public void run() {
System.out.println(Thread.currentThread().getName() + "执行了");
}
}).start();
// 使用lambda标准格式完成多线程
new Thread(()->{
System.out.println(Thread.currentThread().getName() + "执行了");
}).start();
}
}
3.Lambda表达式比较器
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/*
使用比较器排序对Person对象根据年龄排序
*/
public class Demo03Collection {
public static void main(String[] args) {
//创建集合
List<Person> list = new ArrayList<>();
//添加Person对象
list.add(new Person("公孙嘏", 20));
list.add(new Person("郑等待", 18));
list.add(new Person("丁巴寿", 22));
//使用比较器排序(对集合中的Person对象按照年龄从小到大的顺序排序)
//单独定义Comparator实现类,然后创建实现类对象。
Collections.sort(list, new Rule());
//使用匿名内部类完成比较器排序
/*Collections.sort(list, new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
});*/
/*
(参数类型 参数名) -> {
方法体;
return 返回值;
}
*/
//使用Lambda表达式完成比较器排序
Collections.sort(list, (Person o1, Person o2) -> {
return o1.getAge() - o2.getAge();
});
//使用Lambda表达式省略格式完成比较器排序
//Collections.sort(list, (o1, o2) -> o1.getAge() - o2.getAge());
//输出结果
System.out.println(list);
}
}
import java.util.Comparator;
public class Rule implements Comparator<Person> {
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
}
public class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
4.Lambda表达式简化写法
Lambda标准格式:
(参数类型 参数名) -> {
方法体;
return 返回值;
}
省略规则:
1. 小括号中的参数类型可以省略。
2. 如果小括号中只有一个参数,那么可以省略小括号。
3. 如果大括号中只有一条语句,那么可以省略大括号,return,以及分号。
public class Demo04SimpleLambda {
public static void main(String[] args) {
//使用Lambda标准格式完成多线程
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
}).start();
//使用Lambda表达式省略格式完成多线程
new Thread(() -> System.out.println(Thread.currentThread().getName() + "执行了")).start();
}
}
5.Lambda表达式使用前提
Lambda表达式的使用前提
1. 必须要有接口(不能是抽象类),接口中有且仅有一个需要被重写的抽象方法。(比如Runnable或Comparator)
2. 必须支持上下文推导。 要能够推导出来Lambda表达式表示的是哪个接口中的哪个方法。
最常用的上下文推导的方式是使用函数式接口当做方法参数,然后传递Lambda表达式。
注意:
如果一个接口中有且仅有一个需要被重写的抽象方法,那么该接口也叫做函数式接口。
public class Demo05BeforLambda {
public static void main(String[] args) {
//() -> System.out.println(Thread.currentThread().getName() + "执行了");
//因为Thread构造方法需要传递Runnable接口类型的参数,而Runnable接口中只有一个需要被重写的抽象方法叫做run
//所以向Thread构造方法位置传递的Lambda表示必然表示Runnable接口中的run方法。
new Thread(() -> System.out.println(Thread.currentThread().getName() + "执行了")).start();
}
}
第六章 Stream
1.传统方式操作集合的弊端
import java.util.ArrayList;
import java.util.List;
/*操作要求:
1. 首先筛选所有姓张的人;
2. 然后筛选名字有三个字的人;
3. 最后进行对结果进行打印输出。*/
public class Demo01PrintList {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
//1. 首先筛选所有姓张的人;
//定义集合,保存本次筛选后的结果
List<String> zhangList = new ArrayList<>();
//遍历集合,拿到每一个元素,判断是否以张开头
for (String str : list) {
if(str.startsWith("张")) {
zhangList.add(str);
}
}
// 2. 然后筛选名字有三个字的人;
//定义集合,保存本次筛选后的结果
List<String> threeList = new ArrayList<>();
//遍历上次筛选后的结果,拿到里面的每一个元素,判断是否是三个字
for (String str : zhangList) {
if(str.length() == 3) {
threeList.add(str);
}
}
//3. 最后进行对结果进行打印输出。
for (String str : threeList) {
System.out.println(str);
}
System.out.println("===================");
// Stream体验
//list.stream().filter(s->s.startsWith("张")).filter(s->s.length()==3).forEach(s-> System.out.println(s));
list.stream().filter(s->s.startsWith("张")).filter(s->s.length()==3).forEach(System.out::println);
}
}

2.单列集合获取流
Stream<T>是一个接口,该接口表示流。
获取流的两种方式
1. 通过Collection集合(单列集合)调用stream()方法获取。【根据单列集合获取】
2. 通过Stream中的静态方法根据数组获取流。【根据数组获取】
Collection中获取流的方法:
Stream<E> stream():获取集合对应的流。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
public class Demo02CollectionGetStream {
public static void main(String[] args) {
// 创建集合
List<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
list.add("java");
// 通过集合获取流
Stream<String> stream = list.stream();
// 输出
// 将流转成数组,用数组的工具类将数组转成字符串,并使用println输出
System.out.println(Arrays.toString(stream.toArray()));
}
}
3.根据数组获取流
在Stream中有一个静态方法,可以根据数组获取流。
Stream中根据数组获取流的方法:
static <T> Stream<T> of(T... values):根据数组或多个元素获取Stream流。
使用引用类型数据类型.
import java.util.Arrays;
import java.util.stream.Stream;
public class Demo02ArrayGetStream {
public static void main(String[] args) {
// 创建数组
// String[] strArr = {"aa","bb","cc"};
// 根据数组获取流
// Stream<String> stream = Stream.of(strArr);
//of方法不仅可以根据数组获取流,也可以根据多个元素获取流
Stream<String> stream = Stream.of("aa","bb","cc");
// 输出
System.out.println(Arrays.toString(stream.toArray()));
}
}
4.Stream的常用方法
流模型的操作很丰富,这里介绍一些常用的API。这些方法可以被分成两种:
终结方法:返回值类型不再是 Stream 接口自身类型的方法,因此不再支持类似 StringBuilder 那样的链式 调用。本小节中,终结方法包括 count 和 forEach 方法。
非终结方法:返回值类型仍然是 Stream 接口自身类型的方法,因此支持链式调用。(除了终结方法外,其余方法均为非终结方法。)
函数拼接与终结方法 在上述介绍的各种方法中,凡是返回值仍然为 Stream 接口的为函数拼接方法,它们支持链式调用;而返回值不再
为 Stream 接口的为终结方法,不再支持链式调用。如下表所示:
| 方法名 | 作用 | 方法种类 | 是否支持链式调用 |
|---|---|---|---|
| count | 统计个数 | 终结 | 否 |
| forEach | 逐一处理 | 终结 | 否 |
| filter | 过滤 | 函数拼接 | 是 |
| limit | 取用前几个 | 函数拼接 | 是 |
| skip | 跳过前几个 | 函数拼接 | 是 |
| map | 映射 | 函数拼接 | 是 |
| concat | 组合 | 函数拼接 | 是 |
4.1forEach
在Stream中有一个方法叫做forEach,可以对流中的元素进行逐一处理,逐一操作
void forEach(Consumer action):对流中的每一个元素进行逐一操作,逐一处理。参数Consumer表示处理规则。
Consumer是一个函数式接口,这个接口中只有一个抽象方法
void accept(T t):对数据进行操作,进行处理。
forEach方法的参数是Consumer函数式接口,那么可以传递Lambda表达式,这个Lambda表达式表示的是Consumer接口中唯一的一个抽象方法
accept的内容,我们要在Lambda表达式中编写操作规则。
import java.util.stream.Stream;
public class Demo04ForEach {
public static void main(String[] args) {
// 获取Stream流
Stream<String> stream = Stream.of("aa", "bb", "cc", "dd", "ee");
// 对流中的每一个元素进行逐一处理
stream.forEach(s -> System.out.println(s));
}
}
4.2filter
在Stream中有一个方法叫做filter,可以对流中的元素进行过滤筛选。
Stream<T> filter(Predicate predicate):用来对流中的元素进行过滤筛选,返回值是过滤后新的流。参数predicate表示过滤规则。
Predicate是一个函数式接口,里面只有一个抽象方法
boolean test(T t):判断数据是否符合要求。
filter方法参数是Predicate函数式接口,所以可以向参数位置传递Lambda表达式,该Lambda表达式表示Predicate接口中的唯一的抽象方法
test的内容[抽血后]。我们要在Lambda表达式中编写过滤规则。
因为Lambda表达式就是重写后的test.
如果我们希望某个数据留下,那么就返回true,如果不希望某个数据留下,那么就返回false。
import java.util.stream.Stream;
public class Demo05Filter {
public static void main(String[] args) {
//获取Stream流
Stream<String> stream = Stream.of("aa", "bbbbbb", "ccc", "ddddd");
//对流中的元素进行过滤,只留下长度大于4的元素。
//参数s表示流中的每一个元素,Lambda表达式的方法体是过滤的规则,如果结果是true,元素留下
Stream<String> newStream = stream.filter(s -> s.length() > 4);
//对过滤后新的流中的元素进行逐一处理,逐一输出
newStream.forEach(s -> System.out.println(s));
}
}
4.3Count
/*
在Stream中有一个方法叫做count,可以获取流中元素的个数。
long count():获取流中的元素的个数。
*/
import java.util.stream.Stream;
public class Demo06Count {
public static void main(String[] args) {
Stream<String> stream = Stream.of("aa", "bb", "cc", "dd", "ee");
long count = stream.count();
System.out.println(count);
}
}
4.4 Limit
/*
在Stream中有一个方法叫做limit,可以获取流中的前几个元素。
Stream<T> limit(long n):获取流中的前n个元素然后放入到新的流中返回。
*/
import java.util.stream.Stream;
public class Demo07Limit {
public static void main(String[] args) {
Stream<String> stream = Stream.of("aa", "bb", "cc", "dd", "ee");
// 获取前两个
Stream<String> limit = stream.limit(2);
// 输出
limit.forEach(s -> System.out.println(s));
}
}
4.5skip
/*
在Stream中有一个方法叫做skip,可以跳过流中的前几个元素,获取剩下的元素
Stream<T> skip(long n):跳过流中前n个元素,获取剩下的元素放到一个新的流中返回。
*/
import java.util.stream.Stream;
public class Demo08Skip {
public static void main(String[] args) {
// 获取流
Stream<String> stream = Stream.of("aa", "bb", "cc", "dd", "ee");
// 跳过前两个元素
Stream<String> skip = stream.skip(2);
skip.forEach(s -> System.out.println(s));
}
}
4.6concat
/*
在Stream中有一个静态方法叫做concat,可以对两个流进行合并,合并成新的流。
static Stream concat(Stream a, Stream b):对a和b这两个流进行合并,合并成新的流返回。
*/
import java.util.stream.Stream;
public class Demo09Concat {
public static void main(String[] args) {
// 创建两个流
Stream<String> stream1 = Stream.of("aa", "bbbbbb");
Stream<String> stream2 = Stream.of("ccc", "ddddd");
// 通过stream的静态方法concat对流进行合并
Stream<String> stream = Stream.concat(stream1, stream2);
stream.forEach(s -> System.out.println(s));
}
}
4.7Map
映射也可以看成转换
/*
在Stream中有一个方法就叫做map,可以将流中的元素【映射】到另一个流中。
举例:
原来的流:"10", "20", "30"
映射后新的流:10, 20, 30
映射就是将原来流中的每一个元素都进行操作,操作之后放到新的流中。
Stream中的map方法:
Stream map(Function mapper):将流中的元素映射到新的流中并返回。参数Function表示映射规则。
Function是一个函数式接口,里面只有一个抽象方法叫做apply
R apply(T t):对数据进行处理,然后返回处理后结果。
map方法的参数是Function这个函数式接口,那么我们可以传递Lambda表达式, 这个Lambda表达式表示的Function中唯一的一个抽象方法
apply方法的内容,我们因为要在apply中定义映射(处理)规则,所以我们将映射规则直接写在Lambda表达式
中即可,因为Lambda表达式表示的就是重写后的Function中的apply方法
*/
import java.util.stream.Stream;
public class Demo10Map {
public static void main(String[] args) {
// 获取一个stream流
Stream<String> stream = Stream.of("10", "20", "30");
//将流中的每一个元素转成数组保存到新的流中[映射]
//s表示流中的每一个元素,此时是拿到原来流中的每一个字符串,然后放到新的流中返回
Stream<Integer> integerStream = stream.map(s ->Integer.parseInt(s));
integerStream.forEach(num-> System.out.println(num));
}
}
5.注意事项
/*
Stream中的注意事项:
1.Stream流的非终结方法返回值类型都是本身stream类型,但是返回的并不是本身的对象
2.Stream流只能一次性使用,不能多次使用
*/
import java.util.stream.Stream;
public class Demo11Stream {
public static void main(String[] args) {
// 获取流
Stream<String> stream = Stream.of("aa", "bb", "cc", "dd");
// 调用非总结方法
Stream<String> limit = stream.limit(2);
//stream.skip(1);
/*Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.<init>(AbstractPipeline.java:203)
at java.util.stream.ReferencePipeline.<init>(ReferencePipeline.java:94)
at java.util.stream.ReferencePipeline$StatefulOp.<init>(ReferencePipeline.java:647)
at java.util.stream.SliceOps$1.<init>(SliceOps.java:120)
at java.util.stream.SliceOps.makeRef(SliceOps.java:120)
at java.util.stream.ReferencePipeline.skip(ReferencePipeline.java:411)
at cn.com.mryhl.demo08_stream.Demo11Stream.main(Demo11Stream.java:18)
Process finished with exit code 1
*/
System.out.println(stream == limit);//false
}
}
6.流练习
/*
现在有两个ArrayList 集合存储队伍当中的多个成员姓名,要求使用传统的for循环(或增强for循环)
依次进行以下若干操作步骤:
1. 第一个队伍只要名字为3个字的成员姓名;
2. 第一个队伍筛选之后只要前3个人;
3. 第二个队伍只要姓张的成员姓名;
4. 第二个队伍筛选之后不要前2个人;
5. 将两个队伍合并为一个队伍;
6. 根据姓名创建Person 对象;
7. 打印整个队伍的Person对象信息。
*/
import java.util.ArrayList;
import java.util.List;
public class Demo12StreamTest {
public static void main(String[] args) {
List<String> one = new ArrayList<>();
one.add("迪丽热巴");
one.add("宋远桥");
one.add("苏星河");
one.add("老子");
one.add("庄子");
one.add("孙子");
one.add("洪七公");
one.add("欧阳锋");
List<String> two = new ArrayList<>();
two.add("古力娜扎");
two.add("张无忌");
two.add("张三丰");
two.add("赵丽颖");
two.add("张二狗");
two.add("张天爱");
two.add("张三");
//1. 第一个队伍只要名字为3个字的成员姓名;
List<String> oneA = new ArrayList<>();
//遍历one,拿到每一个元素判断名字是否是三个字,如果是,就添加到oneA中
for (String s : one) {
if (s.length() == 3) {
oneA.add(s);
}
}
//2. 第一个队伍筛选之后只要前3个人;
List<String> oneB = new ArrayList<>();
//遍历oneA,只获取前三个元素添加到oneB
for (int i = 0; i < 3; i++) {//0 1 2
//获取元素
String str = oneA.get(i);
//添加到oneB中
oneB.add(str);
}
//3. 第二个队伍只要姓张的成员姓名;
List<String> twoA = new ArrayList<>();
//遍历two,拿到里面的每一个元素,判断是否姓张,如果姓张,就添加到twoA集合
for (String str : two) {
if (str.startsWith("张")) {
twoA.add(str);
}
}
//4. 第二个队伍筛选之后不要前2个人;
List<String> twoB = new ArrayList<>();
//遍历twoA,跳过前两个元素,拿到后面的每一个元素添加到twoB
for (int i = 2; i < twoA.size(); i++) {
String str = twoA.get(i);
twoB.add(str);
}
//5. 将两个队伍合并为一个队伍;
List<String> totalList = new ArrayList<>();
totalList.addAll(oneB);//将oneB中的所有的元素添加到totalList中。
totalList.addAll(twoB);//将twoB中的所有的元素添加到totalList中
//6. 根据姓名创建Person 对象;
//将totalList中的每一个字符串姓名变成Person对象保存【映射】到新的集合
List<Person> personList = new ArrayList<>();
//遍历totalList集合,拿到每一个姓名,根据姓名创建Person对象,添加到personList集合
for (String name : totalList) {
personList.add(new Person(name));
}
//7. 遍历打印整个队伍的Person对象信息。
for (Person person : personList) {
System.out.println(person);
}
}
}
/*
现在有两个ArrayList 集合存储队伍当中的多个成员姓名,要求使用传统的for循环(或增强for循环)
依次进行以下若干操作步骤:
1. 第一个队伍只要名字为3个字的成员姓名;
2. 第一个队伍筛选之后只要前3个人;
3. 第二个队伍只要姓张的成员姓名;
4. 第二个队伍筛选之后不要前2个人;
5. 将两个队伍合并为一个队伍;
6. 根据姓名创建Person 对象;
7. 打印整个队伍的Person对象信息。
*/
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class Demo13StreamTest {
public static void main(String[] args) {
List<String> one = new ArrayList<>();
one.add("迪丽热巴");
one.add("宋远桥");
one.add("苏星河");
one.add("老子");
one.add("庄子");
one.add("孙子");
one.add("洪七公");
one.add("欧阳锋");
List<String> two = new ArrayList<>();
two.add("古力娜扎");
two.add("张无忌");
two.add("张三丰");
two.add("赵丽颖");
two.add("张二狗");
two.add("张天爱");
two.add("张三");
//1. 第一个队伍只要名字为3个字的成员姓名;
//2. 第一个队伍筛选之后只要前3个人;
Stream<String> streamOne = one.stream().filter(s -> s.length() == 3).limit(3);
//3. 第二个队伍只要姓张的成员姓名;
//4. 第二个队伍筛选之后不要前2个人;
Stream<String> streamTwo = two.stream().filter(s -> s.startsWith("张")).skip(2);
//5. 将两个队伍合并为一个队伍;
//6. 根据姓名创建Person 对象;
//7. 打印整个队伍的Person对象信息。
Stream.concat(streamOne, streamTwo).map(s -> new Person(s)).forEach(p -> System.out.println(p));
}
}
7.收集到集合中
/*
将流中的元素收集到集合中(将流转成集合)
在Stream中有一个方法叫做collect,可以将流中的元素收集到集合(将流转成集合)
R collect(Collector collector):该方法可以将流中的元素收集到集合.参数collector表示收集到哪种集合.
Collector是一个接口,我们要使用这个接口的实现类对象,这个接口的实现类对象不是由我们去创建的,而是通过工具类获取,获取Collector的工具类叫做Collectors
Collectors里用于获取Collector对象的方法
static Collector toList():获取到的Collector对象表示将数据收集到list集合中
static Collector toSet():获取到的Collector对象表示将数据收集到set集合中
*/
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Demo01StreamToCollection {
public static void main(String[] args) {
//获取Stream流
Stream<String> stream = Stream.of("aa", "bb", "cc", "dd");
// 将流中的元素收集到List集合中
// List<String> list = stream.collect(Collectors.toList());
//System.out.println(list);
//将流中的元素收集到Set集合(将流转成Set集合)
Set<String> set = stream.collect(Collectors.toSet());
System.out.println(set);
}
}
8.收集到数组中
/*在Stream中有一个方法叫做toArray,可以将流中的内容收集到数组中(将流转成数组)
Object[] toArray():将流转成数组
*/
import java.util.Arrays;
import java.util.stream.Stream;
public class Demo02StreamToArray {
public static void main(String[] args) {
//获取Stream流
Stream<String> stream = Stream.of("aa", "bb", "cc", "dd");
Object[] objects = stream.toArray();
//输出
System.out.println(Arrays.toString(objects));
}
}
总结
一. 线程池
概念:线程池就是一个容器,这个容器里面预先保存了很多线程,线程池里面的线程可以多次执行任务。
这样就可以解决频繁创建以及销毁线程带来的性能问题。
相关API:
Executor:线程池的根接口。
ExecutorService:Executor的子接口,该接口表示线程池
Executors:线程池的工具类,可以获取线程池
newFixedThreadPool(int leng):获取定长的线程池的方法
线程池的使用方式:
1. 通过Executors调用方法获取线程池。
2. 定义线程池要执行的任务【Runnable实现类】
3. 调用线程池的submit方法,提交线程任务。
4. 销毁线程池【一般不做】
Callable接口的方式完成多线程
了解,基本不用。
二. 死锁
如果多个线程各自持有自己的锁并且等待对方释放锁,就会相互僵持,这就就是死锁。
死锁是一个错误的代码,要避免。
三. 线程状态
新建(NEW):刚刚创建出来并没有调用start方法启动的线程处于新建状态。
运行(RUNNABLE):线程调用start方法会处于运行的状态。
受阻塞(BLOCKED):等待获取锁的线程处于受阻塞的状态。
无限等待(WAITING):当线程调用wait()方法后,处于无限等待状态【没有时间的等待,别人不叫我,我就一直等】
计时等待(TIMED_WAITING):当线程调用sleep(毫秒),wait(毫秒值)会进入到计时等待【有时间的等待,到了时间别人不叫我,我也会醒】
退出(TERMINATED):如果线程执行完了run方法,或者线程调用了stop方法。
四. 等待唤醒机制【能看懂即可】
在Object中,有两种方法可以让线程等待以及唤醒线程。
void wait():让线程等待,直到有其他线程唤醒他。
void wait(long timeout):让线程等待,直到有其他线程唤醒他,或者时间到了也会自己醒。参数是等待的毫秒值。
void notify(): 唤醒一个等待的线程。
void notifyAll(): 唤醒所有等待的线程。
五. 定时器
Timer类, 表示定时器,可以只执行一次,也可以周期性的执行
Timer的构造方法:
Timer():空参数的构造方法
其他方法:
void schedule(TimerTask task, long delay):指定毫秒值【delay】后,执行任务【task】,只执行一次
void schedule(TimerTask task, long delay, long period):指定毫秒值【delay】后,执行任务【task】,该方法会周期性的执行任务,每隔period会执行一次
void schedule(TimerTask task, Date time):安排定时器在指定的时间【time】执行任务【task】
void schedule(TimerTask task, Date firstTime, long period):安排定时器在指定的时间【time】执行任务【task】。会周期性的执行,每隔period会执行一次
六. Lambda表达式【要会写】
Lambda是匿名内部类的简化写法。
标准格式:
(参数类型 参数名) -> {
方法体;
return 返回值;
}
省略规则:
1. 小括号中的参数类型可以省略。
2. 如果小括号中只有一个参数,小括号可以省略。
3. 如果大括号中只有一条语句,可以省略大括号,return,以及分号。
Lambda表达式的使用前提:
1. 必须要有函数式接口【该接口中有且仅有一个需要被重写的抽象方法】
2. 必须支持上下文推导【使用函数式接口当做方法参数,传递Lambda表达式】
七. Stream流
思想:相当于流水线
获取流的两种方式:
1. 通过单列集合调用stream方法获取。
2. 通过Stream的静态方法of根据数组或者多个元素获取。
Stream中的其他方法:
forEach:逐一处理
count:获取个数
limit:获取前几个元素
skip:跳过前几个元素
filter: 过滤
concat:合并
map:映射
将流中的元素收集到集合或数组
将流中的元素收集到集合
流.collect(Collectors.toList()):将流中的元素收集到List集合
流.collect(Collectors.toSet()):将流中的元素收集到Set集合
将流中的元素收集到数组
流.toArray();
多线程部分要能够写出线程池的代码
函数式编程部分要能够使用Lambda表达式















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











