







启动步骤:
1.启动3台虚拟机【都用root登录】
2.启动hadoop:
start-all.sh,然后jps进行测试出现633
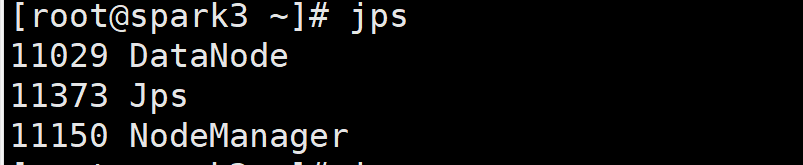
第一台 6

第二台3
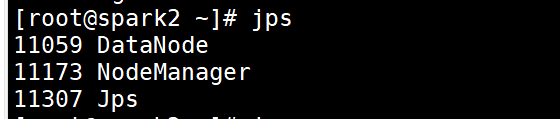
第三台 3
讲真我刚开始就不知道 633什么意思。说的不明不白的。
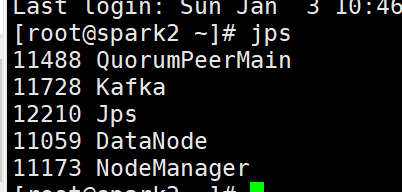
3.启动3台zookeeper:
zkServer.sh start,jps出现744
第一台spark1 【7】

第一台spark2 【4】

第一台spark3 【4】

4.启动3台kafka:
kafka-server-start.sh /hadoop
fka213240/config
rver.properties,新建选项卡连接101,测试jps出现855
注意:启动 之前 需要vi /hadoop/kafka213240/config/server.properties (有3个地方要改)
修改其中broke.id为不同的值,如1,2,3【三台不同的虚拟机分别修改】

启动spark1

查看jps时 是 新建会话,

启动2
3台操作一样
5.连接数据库:[root@Spark1 zk356]# systemctl start mariadb
[root@Spark1 zk356]# mysql -uroot -p
MariaDB [(none)]> use mysql;
MariaDB [mysql]> select user,host from user;
MariaDB [mysql]> update user set host='%' where user='root' and host='localhost';
6.然后执行
kafka-console-consumer.sh --bootstrap-server spark1:9092,spark2:9092,spark3:9092 --topic laozhangX --from-beginning
7.新建选项卡【就是再打开一个界面,链接第一台虚拟机。这里使用的是xshell进行链接】,连接101,启动flume:flume-ng agent -c conf -f /hadoop/flume190/conf/flume_mysql.conf -n a1 -Dflume.root.logger=INFO,console
8.新建选项卡,连接101,执行python代码:进入代码路径执行spark-submit 文件名
附上详细步骤讲解【腾讯文档】最新版本Hadoop_SparkStreaming
https://docs.qq.com/doc/DQndtbUJDVWFnblJW
















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











