







 本文介绍了如何使用高德地图的JS API和Web API进行骑行路线规划。首先展示了jsAPI的基本用法,通过AMap.Riding搜索骑行路线。接着,详细解释了webAPI的起始点处理函数,用于获取骑行路线的距离和时长。最后,展示了如何批量处理多个起终点的骑行路线规划,通过循环调用webAPI实现。注意,高德地图的路线规划批量处理接口已下线,每日限额300000次。
本文介绍了如何使用高德地图的JS API和Web API进行骑行路线规划。首先展示了jsAPI的基本用法,通过AMap.Riding搜索骑行路线。接着,详细解释了webAPI的起始点处理函数,用于获取骑行路线的距离和时长。最后,展示了如何批量处理多个起终点的骑行路线规划,通过循环调用webAPI实现。注意,高德地图的路线规划批量处理接口已下线,每日限额300000次。
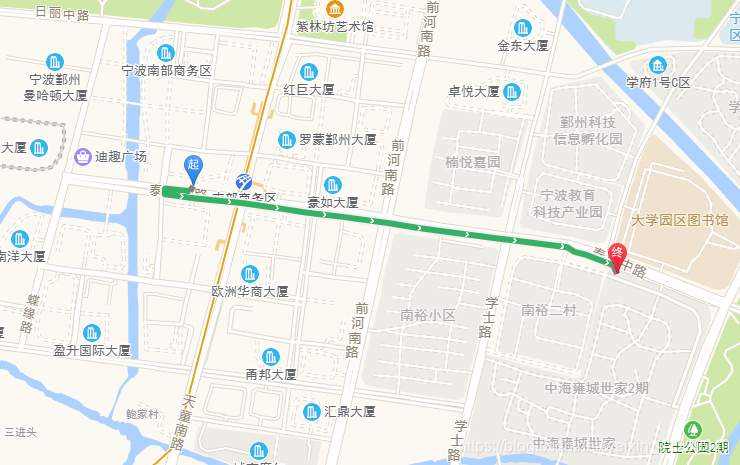
高德地图路线规划批量处理接口已下线,每日分配限额300000次。
jsAPI
var map = new AMap.Map("container", {
center: [116.397559, 39.89621],
zoom: 14
});
var ridingOption = {
map: map,
panel: "panel",
policy: 1,
hideMarkers: false,
isOutline: true,
outlineColor: '#ffeeee',
autoFitView: true
}
var riding = new AMap.Riding(ridingOption)
//根据起终点坐标规划骑行路线
riding.search([121.548053,29.806799],[121.55715,29.805168], function(status, result) {
// result即是对应的公交路线数据信息,相关数据结构文档请参考 https://lbs.amap.com/api/javascript-api/reference/route-search#m_RidingResult
if (status === 'complete') {
log.success('骑行路线数据查询成功')
var json =JSON.stringify(result);
console.log(json);
} else {
log.error('骑行路线数据查询失败' + result)
}
});
webAPI起始点处理
function getDriving($origin, $destination)
{
$url = "https://restapi.amap.com/v3/direction/driving?origin=" . $origin . "&destination=" . $destination . "&extensions=base&output=json&key=4d9a765939**8a3341c2828d87c";
$info = json_decode(file_get_contents($url), true);
if ($info["info"] == "OK") {
//var_dump($info["route"]["paths"][0]["distance"]);
$res = [];
$distance = round($info["route"]["paths"][0]["distance"] / 1000, 2);
$duration = round($info["route"]["paths"][0]["duration"] / 60, 2);
$res["data"]["distance"] = $distance;
$res["data"]["duration"] = $duration;
die(json_encode($res));
} else {
$res["msg"] = $info["info"];
die(json_encode($res));
}
}
$origin = "121.547919,29.806776";
$destination = "121.612332,29.915239";
getDriving($origin, $destination);
webAPI批量处理
function getDriving($origin, $destination)
{
$url = "https://restapi.amap.com/v3/direction/driving?origin=" . $origin . "&destination=" . $destination . "&extensions=base&output=json&key=4d9a765939a2**2828d87c";
$info = json_decode(file_get_contents($url), true);
if ($info["info"] == "OK") {
//var_dump($info["route"]["paths"][0]["distance"]);
$res = [];
$distance = round($info["route"]["paths"][0]["distance"] / 1000, 2);
$duration = round($info["route"]["paths"][0]["duration"] / 60, 2);
$res["data"]["distance"] = $distance;
$res["data"]["duration"] = $duration;
echo "<pre>";
echo "距离:" . $res["data"]["distance"] . "千米 时间:" . $res["data"]["duration"] . "分钟<br>";
} else {
$res["msg"] = $info["info"];
die(json_encode($res));
}
}
$origin = "121.547919,29.806776;121.549689,29.803545";//起点集
$destination = "121.612332,29.915239;121.557821,29.8055";//终点集
$arr1 = explode(";", $origin);
$arr2 = explode(";", $destination);
//批处理;
for ($i = 0; $i < count($arr1); $i++) {
getDriving($arr1[$i], $arr2[$i]);
}
lockdatav Done!


















 2472
2472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











