




 本文详细介绍了使用JavaScript实现的五种排序算法:快速排序、插入排序(包括直接插入和希尔排序)、选择排序(包括简单选择、树形选择和堆排序)、归并排序以及基数排序。文中对每种排序算法的原理、性能分析和稳定性进行了阐述,并提供了相应的代码示例。
本文详细介绍了使用JavaScript实现的五种排序算法:快速排序、插入排序(包括直接插入和希尔排序)、选择排序(包括简单选择、树形选择和堆排序)、归并排序以及基数排序。文中对每种排序算法的原理、性能分析和稳定性进行了阐述,并提供了相应的代码示例。
最近复习一些数据结构的算法,想着既然弄熟了JavaScript,倒不如用JavaScript来实现一下。
在数据结构中的排序算法中,大致可以分为五类:快速排序、插入排序、选择排序、归并排序、基数排序。
目录
1 快速排序
快速排序,法如其名,快——快速排序甚至被认为是目前最好的一种内部排序方法。不过在讲快速排序之前,还是有必要先理解一下冒泡排序。
1.1 冒泡排序
-
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
-
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
-
针对所有的元素重复以上的步骤,除了最后一个。
-
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。

看,就像泡泡一样,每一趟最大的数总是会浮上来。
(二)算法分析:
a. 时间复杂度:
假定我们所需的结果序列是一个升序序列,冒泡排序存在最好和最坏的情况。
最好情况下,待排序列已经是升序序列,此时一趟扫描即可完成排序。所需的关键字比较次数C和移动次数M均达到最小值:
Cmin = n - 1,Mmin = 0
所以,冒泡排序最好的时间复杂度为O(n)。
最坏情况下,待排序列一开始是降序的,需要进行n-1趟排序。每趟排序要进行n-i次关键字的比较(1<=i<=n-1),且每次比较都必须移动记录3次来达到交换记录位置。此时,比较次数和移动次数都达到最大值:
Cmax = n(n-1)/2,Mmax = 3n(n-1)/2
所以,冒泡排序最坏的时间复杂度为O(n^2)。
综上,冒泡排序平均时间复杂度为O(n^2)。
b. 稳定性:
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,是不会再交换的;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是稳定排序算法。
(三)代码:
function bubbleSort(arr) {
var len = arr.length;
for (var i = 0; i < len - 1; i++) {
for (var j = 0; j < len - 1 - i; j++) {
if (arr[j] > arr[j+1]) { // 相邻元素两两对比
var temp = arr[j+1]; // 元素交换
arr[j+1] = arr[j];
arr[j] = temp;
}
}
}
return arr;
}按照上面说的,冒泡排序存在最好和最坏的情况,我们说最好的情况下,只需要比较(n-1)次,可上面的代码可不是这么一回事——管你待排序列长什么样,我都比较个n(n-1)/2次。这让我们不得不考虑一下性能优化的问题。
这让我想起一次坑爹的经历——一次去应聘某公司的实习生,面试官问起来排序算法,首当其冲就是冒泡排序。
当时我这么和面试官说:“冒泡排序在最好的情况下,只需要比较n-1次”。
哪知面试官皱了皱眉,反驳我:“最好的情况下只能保证移动的记录最少为0,但是比较的次数没有增减,最好最坏的情况下都需要比较 ’n(n-1)/2‘ 次”。
当时我面试很是紧张,迷迷糊糊也觉得面试官说的没毛病——也对哦,就算原始数组是排好序的,但是也得比较了再说啊!
后来面试完在回去的路上想着,对个鬼!只要定义标准:“如果一趟比较下来,没有移动记录,则排序结束” 不就好了!这其实就是性能优化了。
var arr = [1, 8, 5, 7, 10, 4, 3, 2, 6, 9]
var arr2 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
//交换函数
function swap(arr, i, j) {
var temp = arr[j]
arr[j] = arr[i]
arr[i] = temp
}
// 1. 冒泡排序
function bubbleSort(arr) {
var len = arr.length,
time = 0
for (var i = 0; i < len; i++) {
var flagSort = false //此趟排序是否交换记录
for (var j = 0; j < len - i; j++) {
if (arr[j] > arr[j + 1]) {
flagSort = true
time++
swap(arr, j, j + 1)
}
}
console.log(time)
if (!flagSort) {
return arr
}
}
return arr
}
console.log(arr) //[1, 8, 5, 7, 10, 4, 3, 2, 6, 9]
console.log(arr2) //[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
console.log(bubbleSort(arr), '冒泡排序') //[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
console.log(bubbleSort(arr2)) //[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]上面代码我加入了一个 flagSort 变量,来标志这趟排序是否有交换的记录,如果在一趟排序下来,flagSort仍然为false,说明该趟排序并没有交换记录,直接return。除此之外,我还加入了一个time变量,可以在每趟排序中打印交换记录的次数。在数组arr2中,由于arr2已经是正序的数组,因此time为0。
1.2 快速排序
(一)算法过程:
1. 首先设定一个分界值,通过该分界值将数组分成左右两部分。
2. 将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
3. 然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
4. 重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。

(二)算法分析:
a. 时间复杂度:

b. 稳定性:
快速排序是不稳定的算法。举个例子就知道了。假定初始序列为:
[49,27,65,97,30,27*,49*]
运用快速排序算法,得到的有序序列为:
[27*,27,30,49,49*,65,97]
(三)代码:
// 2. 快速排序-主函数
function quickSort(arr, left, right) {
var len = arr.length,
left = typeof left == 'number' ? left : 0,
right = typeof right == 'number' ? right : len - 1
if (left < right) {
var partIndex = partition(arr, left, right)
quickSort(arr, left, partIndex - 1)
quickSort(arr, partIndex + 1, right)
}
return arr
}
//快速排序-分区函数
function partition(arr, left, right) {
var pivot = left,
index = pivot + 1
for (var i = index; i <= right; i++) {
if (arr[i] < arr[pivot]) {
swap(arr, i, index)
index++
}
}
swap(arr, pivot, index - 1)
return index - 1
}
console.log(arr) //[1, 8, 5, 7, 10, 4, 3, 2, 6, 9]
console.log(quickSort(arr), '快速排序')//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]2 插入排序
2.1 直接插入排序
(一)算法过程:
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
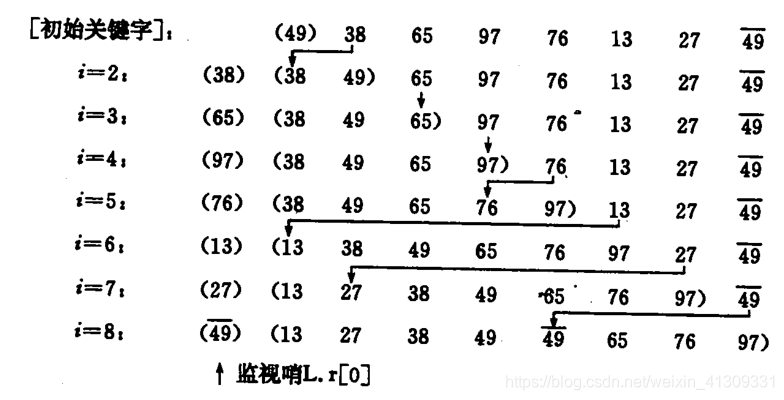
(二)算法分析:
a. 算法复杂度:
假定我们所需的结果序列是一个升序序列,插入排序存在最好和最坏的情况。最好情况下,如果待排序列n个元素已经是升序排序,那么需要比较(n-1)次。最坏情况下,如果待排序列n个元素是降序排序,那么需要比较n(n-1)/2次。平均来说插入排序是时间复杂度是O(n^2)。
因此,插入排序不适合数据量较大的排序应用。但是如果需要排序的数据量很小,例如量级小于千,那么插入排序还是一个不错的选择。
b. 稳定性:
插入排序是在一个已经有序的小序列的基础上,一次插入一个元素。当然,刚开始这个有序的小序列只有1个元素,就是第一个元素。比较是从有序序列的末尾开始,也就是想要插入的元素和已经有序的最大者开始比起,如果比它大则直接插入在其后面,否则一直往前找直到找到它该插入的位置。如果碰见一个和插入元素相等的,那么插入元素把想插入的元素放在相等元素的后面。所以,相等元素的前后顺序没有改变,从原无序序列出去的顺序就是排好序后的顺序,所以插入排序是稳定的。
(三)代码:
// 4. 插入排序
function insertSort(arr) {
var len = arr.length,
preIndex,
currentValue
for (var i = 1; i < len; i++) {
preIndex = i - 1
currentValue = arr[i]
while (preIndex >= 0 && arr[preIndex] > currentValue) {
arr[preIndex + 1] = arr[preIndex]
preIndex--
}
arr[preIndex + 1] = currentValue
}
return arr
}
console.log(arr) //[1, 8, 5, 7, 10, 4, 3, 2, 6, 9]
console.log(insertSort(arr), '插入排序')//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 2.2 希尔排序
(一)算法过程:
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
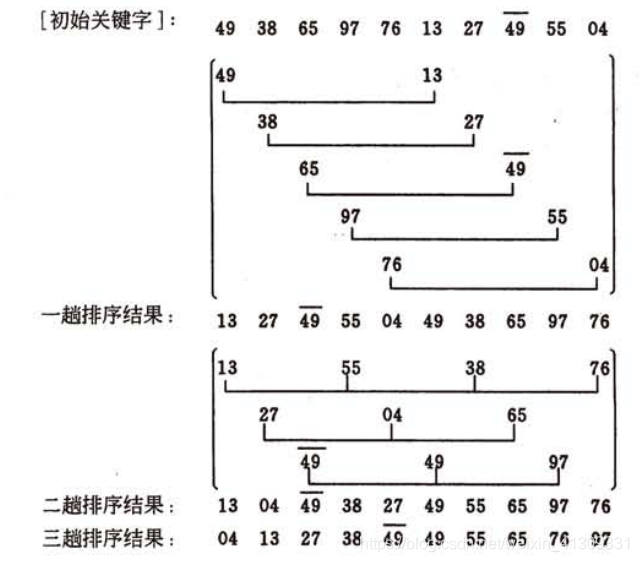
(二)算法分析:
a. 时间性能:
由算法的过程可以知道,希尔排序的执行时间依赖于增量序列。好的增量序列有如下特征:
1. 最后一个增量必须为1;
2. 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。
b. 希尔排序性能优于直接插入排序:
1. 当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
2. 当n值较小时,n和n^2 的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度O(n^2)差别不大。
3. 在希尔排序开始时z增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插入排序有较大的改进。
c. 稳定性:
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
(三)代码:
// 5. 希尔排序
function shellSort(arr) {
var len = arr.length,
temp,
gap = Math.round(len / 3)
for (gap; gap > 0; gap = Math.floor(gap / 3)) {
for (var i = gap; i < len; i++) {
temp = arr[i]
for (var j = i - gap; j >= 0 && arr[j] > temp; j -= gap) {
arr[j + gap] = arr[j]
}
arr[j + gap] = temp
}
}
return arr
}
console.log(arr) //[1, 8, 5, 7, 10, 4, 3, 2, 6, 9]
console.log(shellSort(arr), '希尔排序')//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]3 选择排序
3.1 简单选择排序
(一)算法过程:
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
(二)算法分析:
a. 时间复杂度:
在最好的情况下,待排序列已经有序,简单选择排序算法的交换次数为0;最坏情况下,交换次数为3(n-1)。然而,无论初始待排序列如何,简单选择排序的比较次数始终为n(n-1)/2。因此,总的时间复杂度也是O(n^2)。
b. 稳定性:
举个例子,有序列如下:
[5,8,5*,2,9]
我们知道第一遍选择中,5会和2交换,那么5和5*的位置顺序就被破坏了,因此选择排序不是一个稳定排序。
(三)代码:
// 3. 选择排序
function selectionSort(arr) {
var len = arr.length,
temp,
minIndex
for (var i = 0; i < len - 1; i++) {
minIndex = i
for (var j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j
}
}
swap(arr, i, minIndex)
}
return arr
}
console.log(arr) //[1, 8, 5, 7, 10, 4, 3, 2, 6, 9]
console.log(selectionSort(arr), '选择排序')//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]3.2 树形选择排序
(一)算法过程:
树形选择排序,又称锦标赛排序,是一种按照锦标赛的思想进行选择排序的方法。
首先对n个记录进行两两比较,然后在其中角逐出来的较小者继续进行比较,如此重复,直至选出最小记录为止:
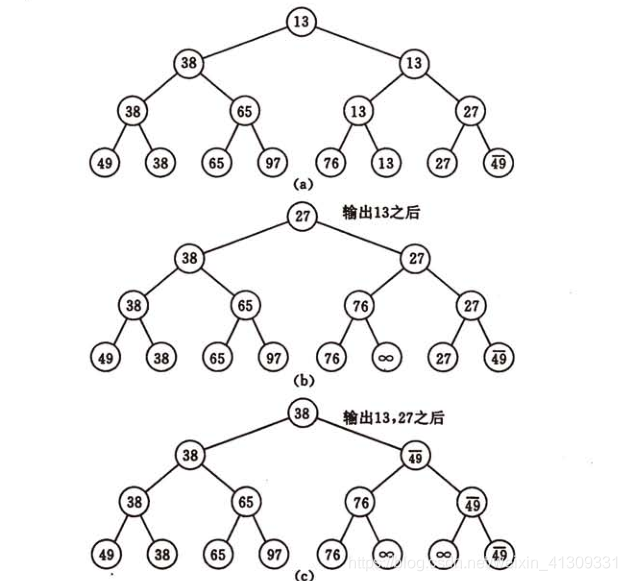
(二)算法分析:
由于n个叶子结点的完全二叉树深度为+1,因此在树形选择排序中,除了最小关键字外,每选择一个次小关键字仅需进行
次比较,因此它的时间复杂度为
。
3.3 堆排序
树形选择排序尚有辅助存储空间较多、和“最大值”进行多余的比较等缺点。为了弥补它的缺点,推排序出现了。
(一)算法过程:
将一个数组看成一颗完全二叉树的话,则堆的含义表明,完全二叉树中所有非终端结点的值均不大于(或不小于)其左右孩子结点的值。堆排序其实就是一个建堆和输出堆顶元素的过程。
建立初始堆的过程:
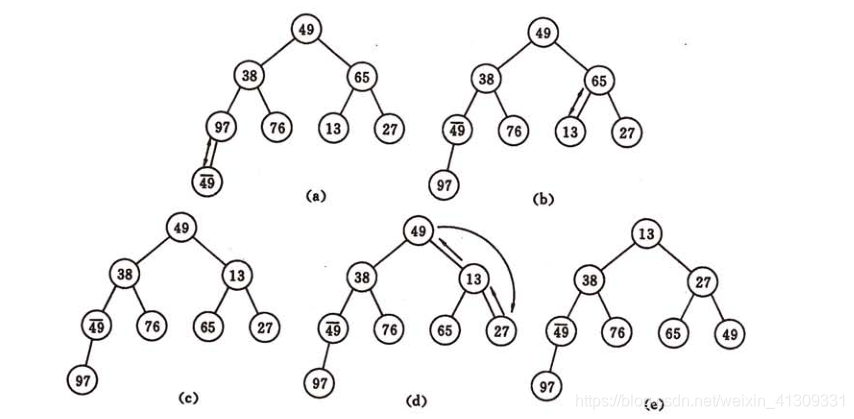
输出堆顶元素并调整建成新堆的过程:
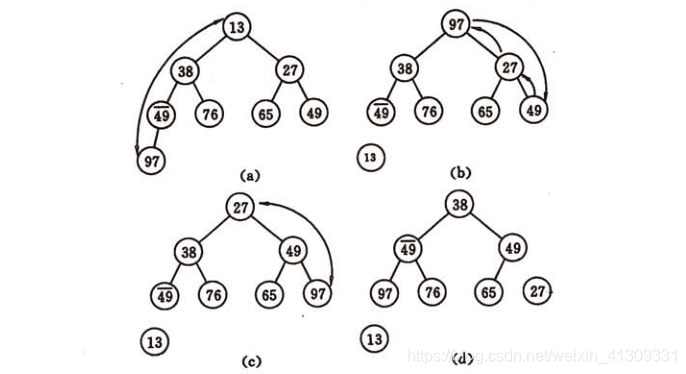
(二)算法分析:
堆排序在最坏的情况下,其时间复杂度也为。
(三)代码:
var len; // 因为声明的多个函数都需要数据长度,所以把len设置成为全局变量
function buildMaxHeap(arr) { // 建立大顶堆
len = arr.length;
for (var i = Math.floor(len/2); i >= 0; i--) {
heapify(arr, i);
}
}
function heapify(arr, i) { // 堆调整
var left = 2 * i + 1,
right = 2 * i + 2,
largest = i;
if (left < len && arr[left] > arr[largest]) {
largest = left;
}
if (right < len && arr[right] > arr[largest]) {
largest = right;
}
if (largest != i) {
swap(arr, i, largest);
heapify(arr, largest);
}
}
function swap(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
function heapSort(arr) {
buildMaxHeap(arr);
for (var i = arr.length-1; i > 0; i--) {
swap(arr, 0, i);
len--;
heapify(arr, 0);
}
return arr;
}4 归并排序
(一)算法过程:
归并操作的工作原理如下:
第一步:申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
第二步:设定两个指针,最初位置分别为两个已经排序序列的起始位置
第三步:比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
重复步骤3直到某一指针超出序列尾
将另一序列剩下的所有元素直接复制到合并序列尾
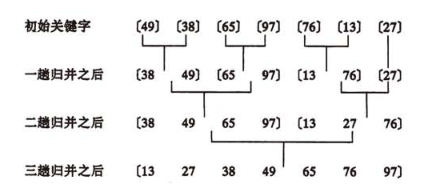
(二)算法分析:
归并算法是分治法的一种重要应用,归并排序是仅次于快速排序的排序算法。
归并排序是稳定的排序.即相等的元素的顺序不会改变.如输入记录 1(1) 3(2) 2(3) 2(4) 5(5) (括号中是记录的关键字)时输出的 1(1) 2(3) 2(4) 3(2) 5(5) 中的2 和 2 是按输入的顺序.这对要排序数据包含多个信息而要按其中的某一个信息排序,要求其它信息尽量按输入的顺序排列时很重要。归并排序的比较次数小于快速排序的比较次数,移动次数一般多于快速排序的移动次数。
(三)代码:
// 6. 归并排序
function mergeSort(arr) {
//采用自上而下的递归
var len = arr.length,
middle,
left,
right
if (len < 2) {
return arr
}
middle = Math.floor(len / 2)
left = arr.slice(0, middle)
right = arr.slice(middle)
return merge(mergeSort(left), mergeSort(right))
}
function merge(left, right) {
var res = []
while (left.length && right.length) {
if (left[0] <= right[0]) {
res.push(left.shift())
} else {
res.push(right.shift())
}
}
while (left.length) {
res.push(left.shift())
}
while (right.length) {
res.push(right.shift())
}
return res
}
console.log(arr)
console.log(shellSort(arr), '归并排序')5 基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
来看一个例子:
对待排序列,首先进行个位上的分配,依次取出项数,得到个位上正序的序列:
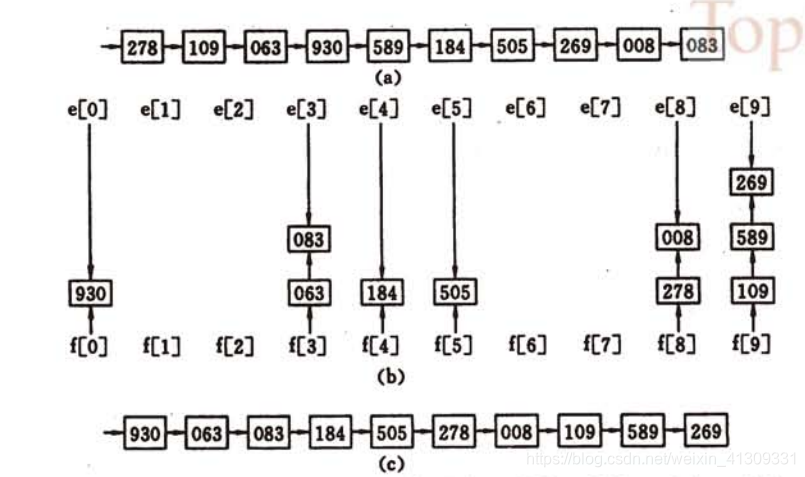
针对个位正序的序列,进行十位上的分配,依次取出项数,得到十位上正序的序列:
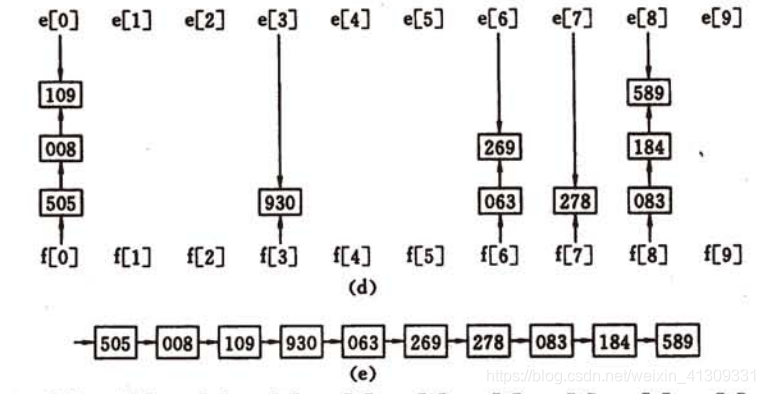
最后针对上面得到的结果序列,进行百位上的分配,依次取出项数,得到百位上正序的序列:
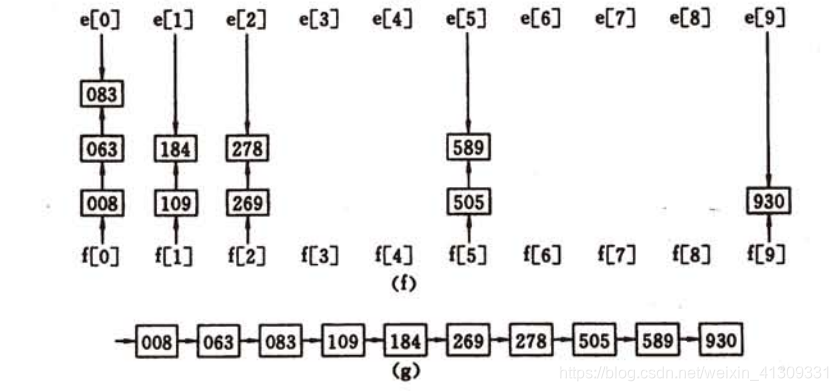
此时整个序列已是正序序列。

















 2292
2292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









