







0x01. 摘要
在许多领域中,同名消歧一直被视为一个很有意义但具有挑战性的问题,如文献管理,社交网络分析等。对论文同名作者的消歧是指利用论文的信息,如标题,作者,作者机构,摘要,关键词等,通过一些方法将论文分配到正确的作者档案中。目前已经有很多研究者针对同名作者消歧问题提出了解决方法,这些方法主要包括利用论文信息进行基于规则的匹配,或者利用表示学习方法,对论文信息进行表征学习,然后利用聚类方法,如层次聚类,DBSCAN等对这些表征向量进行聚类,使得相似的论文聚成一簇,不相似的论文被分到不同的簇中。
本文提出了一种高效的作者名消歧方法,使用基于元路径随机游走的异质网络嵌入方法和基于word2vec的语义表征学习方法学习论文的表征向量,并使用基于DBSCAN与规则匹配结合的聚类方法将论文划分给不同的作者。
0x02. 整体思路
对于某个需要消歧的名字,根据其所有论文之间的关系信息和论文文本信息求出论文表征向量,进而求出论文之间的两两相似度,得到论文相似性矩阵,使用聚类算法和基于相似度阈值的匹配方法将论文划分为不同的簇,则每个簇代表一个特定作者的论文集。
整体框架如下:
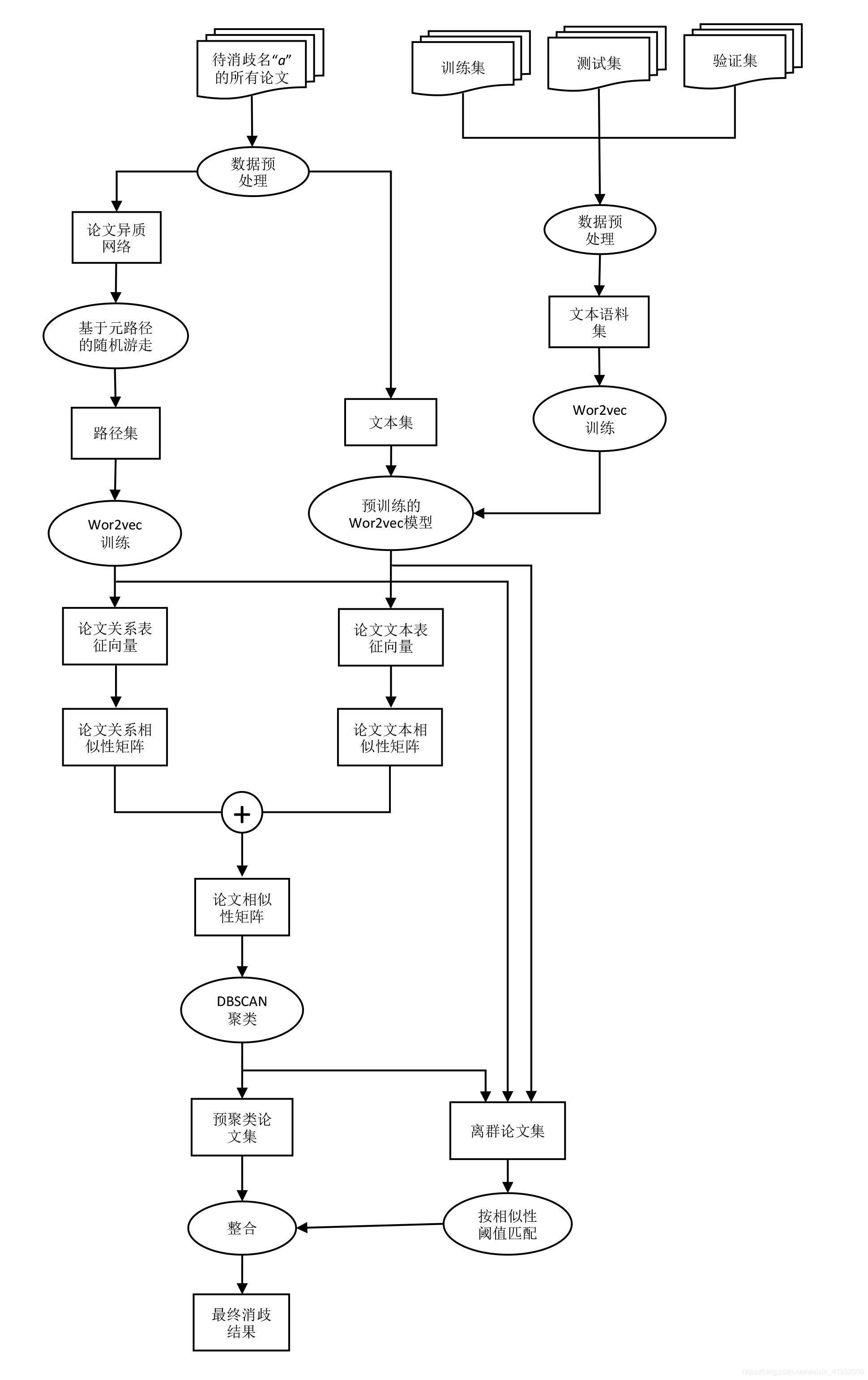
0x03. 特征分析
我们把该问题看作是对一个论文集的聚类任务,且不指定聚类簇个数,即K值。
首先,分析每篇论文的特征,论文的特征包含title, abstract, author, venue, organization, year, keyword. 我们把这些特征划分为两种类型,一种是语义特征,一种是离散特征。
语义特征指的是可以具有语义信息的文本特征,例如title, abstract, keyword,这些文本可以使用语义表征学习模型如word2vec等转化为文本语义向量。在后续的实验中,我们认为venue, organization, year也具有弱语义信息。
离散特征指的是本身的文本信息没有很大的价值,例如author,作者名称本身的语义并没有作用,一个作者只有在两篇文章中同时出现时才有作用,这表示两篇论文有一个共同作者,则它们之间的相似性较大。因此我们把这类特征成为离散特征,只能用来转换为论文间的关系。在后续的实验中,我们发现organization也属于离散特征,因为其中的有些词如地名可以用来搭建论文之间的关系。
具体实施上,我们定义author, organization为离散特征,定义title, venue, organization, year, keyword为语义特征。
基于以上两种特征的认识,我们的思路是使用语义特征学习论文的文本表征向量,利用离散特征来构建论文之间的关系,如有共同作者关系,有机构相似性关系,以此构建论文网络,通过网络嵌入学习方法来学习论文的关系表征向量。再使用聚类算法对论文进行聚类。
0x04. 论文表征学习
这部分我们介绍如何学习论文的两种表征向量。
4.1 论文关系表征学习
此部分的作用是学习到每个论文的关系表征向量。可以看作是先搭建论文异质网络,然后利用网络嵌入的方法学习到每个论文节点的表示向量。本部分用到的特征有author和organization。
网络嵌入(Network Embedding)模型尤其是异质网络嵌入模型已经有了很多研究成果,我们使用的网络嵌入模型主要参考DeepWalk[1]和Metapath2vec[2]。
4.1.1 异质网络构建
对于每一个需要消歧的名字,将其对应的所有的论文之间的关系抽取出来,构建出一个论文异质网络,如图1所示。这个异质网络包含一种类型的节点:论文(每篇论文代表一个节点),两种类型的边:CoAuthor,CoOrg。
CoAuthor代表两个论文之间有共同作者(不包含需要消歧的名字),边上的度代表拥有共同作者的个数。例如如果两篇论文之间有共同作者,那么就在它们之间构建一条关系名为CoAuthor 的边,同时这条边具有共同作者数目的属性,如果有1个共同作者,这个关系的权
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









