







Adaptive Variance Based Label Distribution Learning For Facial Age Estimation》 ECCV 2020
标签分布学习(LDL):
分布学习(Distribution learning)是为了解决标签模糊性问题而提出的一种学习方法。
假设真实年龄可以用离散分布来表示。分布的均值是真值年龄,分布的方差是未知的。
使用K-L散度衡量预测和真值分布之间的相似性,帮助改进年龄估计。
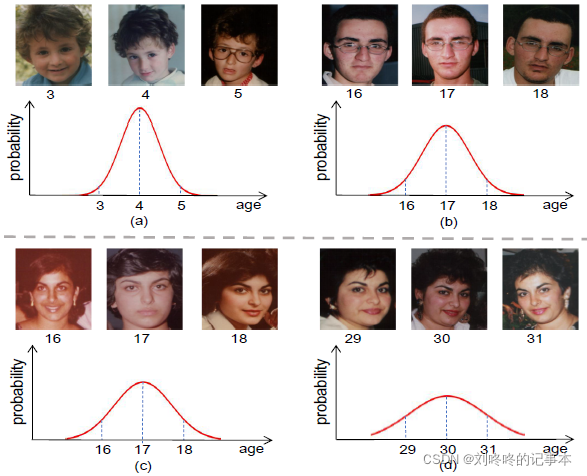
本文认为:同一人不同年龄的方差不同。同一年龄不同人的方差也不同。
提出一种基于自适应方差的分布学习方法(AVDL):
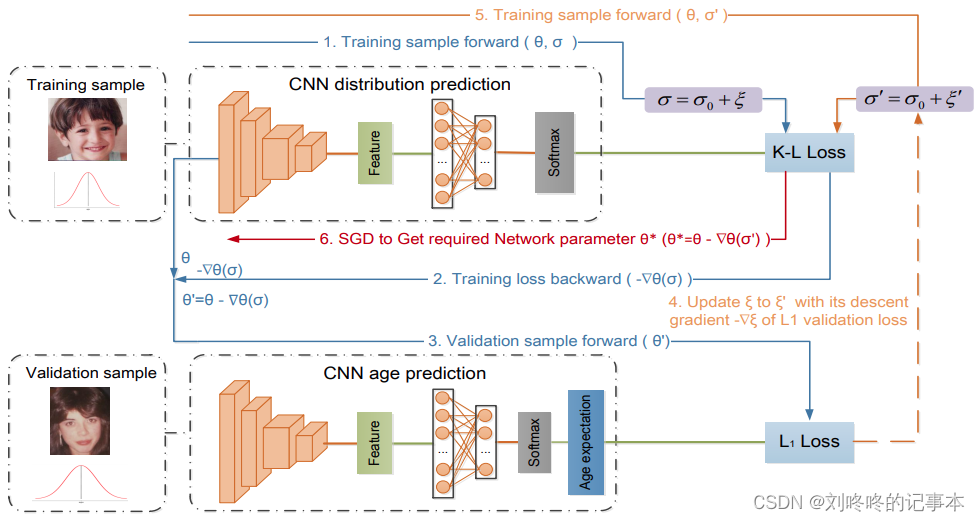 1)使用K-L损失作为训练损失来更新训练模型参数。
1)使用K-L损失作为训练损失来更新训练模型参数。
2)将更新后的参数与验证模型共享,在验证集上使用预测的期望年龄和ground truth计算L1损失,自适应地寻找适当的方差,使模型在验证集上表现得更好。
《C3AE: Exploring the Limits of Compact Model for Age Estimation》CVPR2019
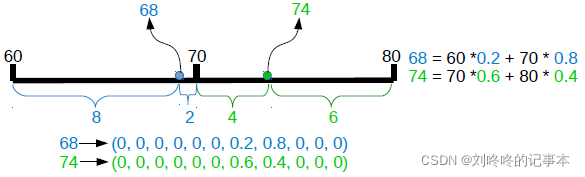
使用类似one-hot向量的两点表示法来表示年龄:
对于一个给定的年龄区间[a,b],将年龄区间均匀划分为K个小区间,年龄y可以用 ![]() 表示:
表示:![]() ,
, ![]() ,
, ![]()
![]()
![]()
例如k=10:
将年龄的两点表示和真实的年龄用来同时指导网络模型的训练。
两点表示的loss采用KL-Divergence:
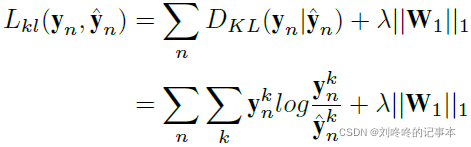
最终的年龄预估阶段的loss采用L1距离:
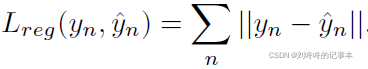
![]()
![]() =10
=10
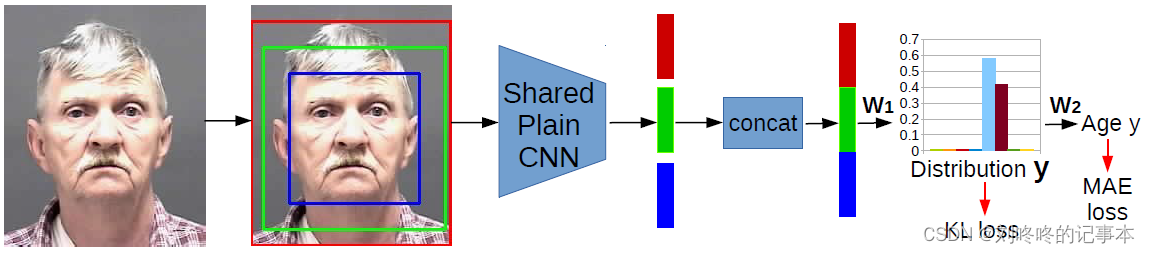
对特征进行concat操作
《Mean-Variance Loss for Deep Age Estimation from a Face》CVPR 2018
均值方差损失:由均值损失和方差损失组成。
均值损失用于惩罚估计的年龄分布的均值与真实年龄之间的不同:
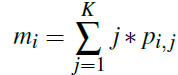
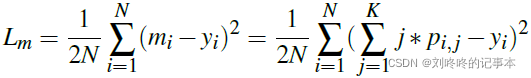
方差损失用于惩罚估计的年龄分布的方差,以获得一个集中的分布:
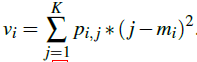
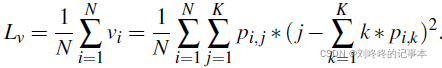
提出的均值方差损失和softmax损失联合嵌入到CNN中用于年龄估计。
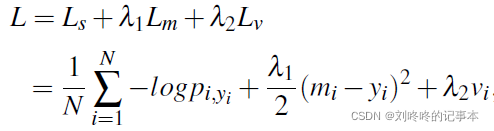
![]()
![]()
《SSR-Net: A Compact Soft Stagewise Regression Network for Age Estimation》
DEX: 将年龄预测回归问题变为多分类问题.
将年龄均分为S个年龄段,即对于[0,V]的年龄跨度,每个年龄段跨度为V/S.
对于一个 S类的分类模型,取其每一类的概率与当前类的代表年龄的加和作为最终的预测值.
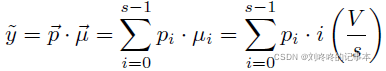
使用由粗到细的多阶段预测策略: 将任务分为K个阶段的多分类任务,第k阶段有sk个bins.
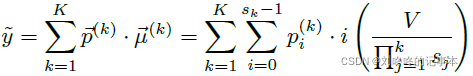
我们通过为每个bin引入一个动态范围,允许每个bin根据输入图像进行移动和缩放。
缩放:![]() 此时bin的宽度为:
此时bin的宽度为: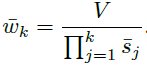
平移:![]()
最终网络输出:![]() ,年龄:
,年龄:
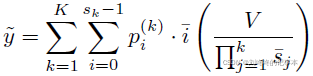
损失函数:最小化平均误差函数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









