







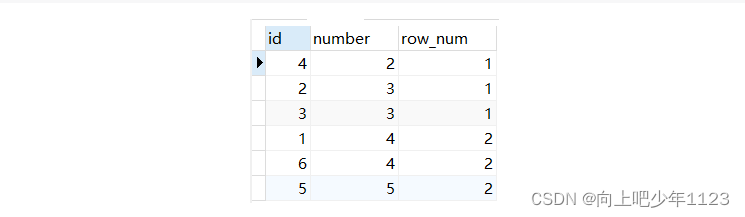
一、ROW_NUMBER()
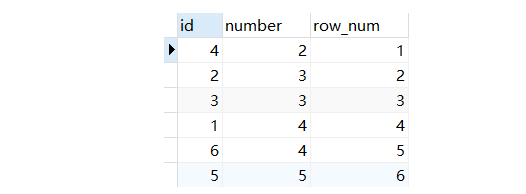
Row_number() 在排名是序号 连续 不重复,即使遇到表中的两个一样的数值亦是如此
select *,row_number() OVER(order by number ) as row_num from num
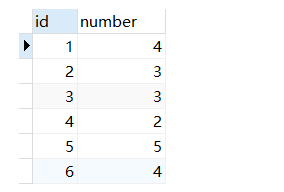
数据如下:
结果如图:
注意:在使用row_number() 实现分页时需要特别注意一点,over子句中的order by 要与SQL排序记录中的order by保持一致,否则得到的序号可能不是连续的
二、rank()
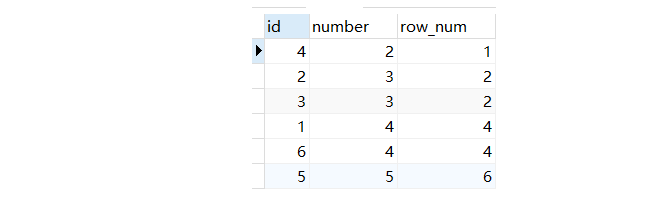
Rank() 函数会把要求排序的值相同的归为一组且每组序号一样,排序不会连续执行
select *,rank() OVER(order by number ) as row_num from num
结果如下:
三、dense_rank()
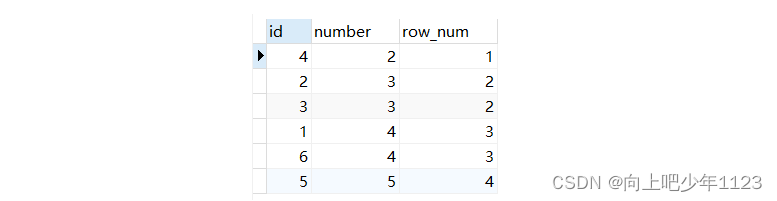
Dense_rank() 排序是连续的,也会把相同的值分为一组且每组排序号一样
select *,dense_rank() OVER(order by number ) as row_num from num
结果如下:
四、ntile()
Ntile(group_num) 将所有记录分成group_num个组,每组序号一样
select *,ntile(2) OVER(order by number ) as row_num from num
结果如下:
ntile函数的分组依据(约定):
1、每组的记录数不能大于它上一组的记录数,即编号小的桶放的记录数不能小于编号大的桶。也就是说,第1组中的记录数只能大于等于第2组及以后各组中的记录数。
2、所有组中的记录数要么都相同,要么从某一个记录较少的组(命名为X)开始后面所有组的记录数都与该组(X组)的记录数相同。也就是说,如果有个组,前三组的记录数都是9,而第四组的记录数是8,那么第五组和第六组的记录数也必须是8。
这里对约定2进行详细说明一下,以便于更好的理解。
首先系统会去检查能不能对所有满足条件的记录进行平均分组,若能则直接平均分配就完成分组了;若不能,则会先分出一个组,这个组分多少条记录呢?就是 (总记录数/总组数)+1 条,之所以分配 (总记录数/总组数)+1 条是因为当不能进行平均分组时,总记录数%总组数肯定是有余的,又因为分组约定1,所以先分出去的组需要+1条。
分完之后系统会继续去比较余下的记录数和未分配的组数能不能进行平均分配,若能,则平均分配余下的记录;若不能,则再分出去一组,这个组的记录数也是(总记录数/总组数)+1条。
然后系统继续去比较余下的记录数和未分配的组数能不能进行平均分配,若能,则平均分配余下的记录;若还是不能,则再分配出去一组,继续比较余下的…这样一直进行下去,直至分组完成。
举个例子,将51条记录分配成5组,51%5==1不能平均分配,则先分出去一组(51/5)+1=11条记录,然后比较余下的 51-11=40 条记录能否平均分配给未分配的4组,能平均分配,则剩下的4组,每组各40/4=10 条记录,分配完成,分配结果为:11,10,10,10,10,我开始就错误的以为他会分配成 11,11,11,11,7。














 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









