







1.order by
hive 的order by 就和SQL的order by是一样的,是全局排序。
select * from student order by id;

2.sort by
对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用sort by;Sort by为每个reducer产生一个排序文件;每个Reducer内部进行排序。
使用sort by之前,一般要先设置reducer的个数
set mapreduce.job.reduces=3;
select * from student sort by id;

可以看到reducer的数量为3,并且查询结果也按id分成了3组;
如果把reducer的数量设置为4:
set mapreduce.job.reduces=4;
select * from student sort by id;

3.distribute by
其实就和sort by是一样的,也是先把所有数据分区,然后区内进行排序,不同的是sort by只设定了排序字段,并没有设置分区字段
select empno,sal from emp
distribute by empno
sort by sal desc;
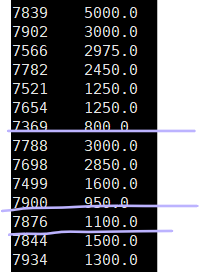
4.cluster by
当分区字段和sort by字段一样时,就可以使用cluster by
select empno,sal from emp
cluster by empno;

可以看到,分区方式还是和上个例子是一样的,只是区内的排序方式不一样了(上例是按sal排序,本例是按empno排序)















 5794
5794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









