







kafka存在的问题
- Kafka 很难进行扩展,因为 Kafka 把消息持久化在 broker 中,迁移主题分区时,需要把分区的数据完全复制到其他 broker 中,这个操作非常耗时。
- 当需要通过更改分区大小以获得更多的存储空间时,会与消息索引产生冲突,打乱消息顺序。因此,如果用户需要保证消息的顺序,Kafka 就变得非常棘手了。
- 如果分区副本不处于 ISR(同步)状态,那么 leader 选取可能会紊乱。一般地,当原始主分区出现故障时,应该有一个 ISR 副本被征用,但是这点并不能完全保证。若在设置中并未规定只有 ISR 副本可被选为 leader 时,选出一个处于非同步状态的副本做 leader,这比没有 broker 服务该 partition 的情况更糟糕。
- 使用 Kafka 时,你需要根据现有的情况并充分考虑未来的增量计划,规划 broker、主题、分区和副本的数量,才能避免 Kafka 扩展导致的问题。这是理想状况,实际情况很难规划,不可避免会出现扩展需求。
- Kafka 集群的分区再均衡会影响相关生产者和消费者的性能。
- 发生故障时,Kafka 主题无法保证消息的完整性(特别是遇到第 3 点中的情况,需要扩展时极有可能丢失消息)。
- 使用 Kafka 需要和 offset 打交道,这点让人很头痛,因为 broker 并不维护 consumer 的消费状态。
- 如果使用率很高,则必须尽快删除旧消息,否则就会出现磁盘空间不够用的问题。
- 众所周知,Kafka 原生的跨地域复制机制(MirrorMaker)有问题,即使只在两个数据中心也无法正常使用跨地域复制。因此,甚至 Uber 都不得不创建另一套解决方案来解决这个问题,并将其称为 uReplicator (https://eng.uber.com/ureplicator/)。
- 要想进行实时数据分析,就不得不选用第三方工具,如 Apache Storm、Apache Heron 或 Apache Spark。同时,你需要确保这些第三方工具足以支撑传入的流量。
- Kafka 没有原生的多租户功能来实现租户的完全隔离,它是通过使用主题授权等安全功能来完成的。
pulsar的应用场景
1)队列和流的融合—维护一套 MQ 服务就够了
Apache Pulsar支持队列模型、也支持流模型。Topic每条消息支持多次消费。Apache Pulsar 抽象出了统一的 producer-topic-subscription-consumer 消费模型。
2)多种 MQ 协议兼容—轻松迁移传统 MQ 服务
支持多种不同协议的自定义转换,也就是说,开发了很多东西支持不改动原有代码的前提下,将其他消息队列的数据发送到pulsar集群中。
3)企业级多租户特性—数据安全有保证
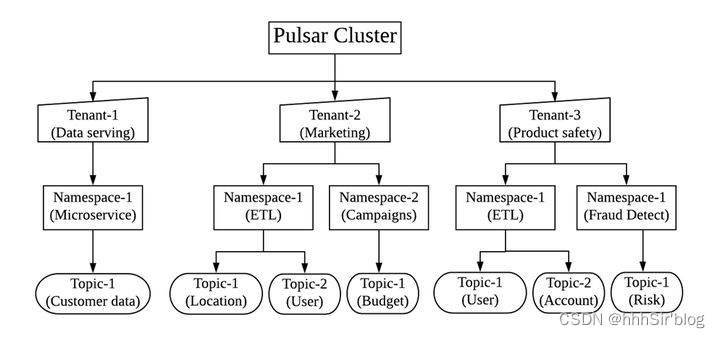
每个租户都可以有单独的认证和授权机制;租户也是存储配额、消息 TTL 和隔离策略的管理单元。
4)跨地域复制—自带跨机房冗灾能力
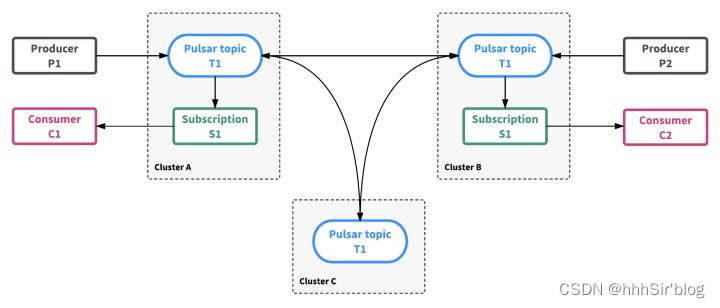
在大型的分布式系统中,都会涉及到跨多个数据中心的需求,通常会使用跨地域复制机制提供额外的冗余防止服务无法正常运作。Apache Pulsar 的跨地域多机房互备特性,是 Pulsar 企业级特性的重要组成部分,它在保证数据稳定可靠的同时,为用户提供了便捷的操作和管理。Pulsar 自带的跨地域复制机制(Geo-Replication)可以提供一种全连接的异步复制.
5)云原生支持—助力服务上云
云原生的原生即软件设计之初就考虑到了将来会被运行在云端的可能,从而在设计层面上就充分利用了云资源的特点,典型的是分布式和弹性伸缩的能力。Pulsar 之所以说是云原生的消息平台,核心就是它的架构设计能够充分利用分布式的、能够弹性伸缩的云端资源。以 Pulsar on Kubernetes 为例,Bookie 是有状态的节点,但是节点之间是对等的,可以采用 StatefulSet 来部署;而 Broker 作为无状态的节点,直接使用 ReplicaSet 即可,每个 Pod 支持水平扩展。















 2359
2359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









