






1:num++是不安全的
如果我们要实现一个计数的操作最简单的方法就是在方法里面定义一个变量,将变量加1。
证明num++是不安全的
package com.hzt.learnthreadlocal.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @Author: hzt
* @Date: 2022/2/24 11:29
*/
@RestController
public class TestCPlusPlus {
private Integer num = 0;
@RequestMapping("/get")
public Integer getNum(){
return num;
}
@RequestMapping("/add")
public Integer add(){
num++;
return num;
}
@RequestMapping("/reset")
public Integer resetNum(){
num=0;
return num;
}
}
使用jmeter100个线程每个线程发送500个请求,结果如下:耗时6秒,只成功增加了48799而我们一共发了5w个请求


使用原子类更改一下num变量,代码如下:
package com.hzt.learnthreadlocal.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @Author: hzt
* @Date: 2022/2/24 11:29
*/
@RestController
public class TestCPlusPlusAtomicInteger {
private AtomicInteger num = new AtomicInteger(0);
@RequestMapping("/get")
public Integer getNum(){
return num.get();
}
@RequestMapping("/add")
public Integer add(){
num.addAndGet(1);
return num.get();
}
@RequestMapping("/reset")
public Integer resetNum(){
num.set(0);
return num.get();
}
}


理论上来说使用原子类会比无锁的integer要慢一点,因为它加了一个cas的轮询机制,在更大的并发下,原子类的耗时会耗时更长
2:使用threadlocal来改造这段代码
package com.hzt.learnthreadlocal.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @Author: hzt
* @Date: 2022/2/24 11:29
*/
@RestController
public class TestThreadLocal {
private ThreadLocal<Integer> num = new ThreadLocal<Integer>(){
@Override
protected Integer initialValue() {
return 0;
}
};
@RequestMapping("/get")
public Integer getNum(){
return num.get();
}
@RequestMapping("/add")
public Integer add(){
num.set(num.get()+1);
return num.get();
}
@RequestMapping("/reset")
public Integer resetNum(){
num.set(0);
return num.get();
}
}
因为spring其实是一个线程池,一般默认有200个线程连接,所以每次请求加一的请求打到哪个线程上面去,我们也不知道,我们尝试使用jmeter200个线程每个线程发送300个请求add方法



可以看出每次请求的都分散在线程池中的各个线程中
那么,假如我们现在有这样子的一个需求,我们有一个计算任务,需要快速的计算出数据且保证数据的准确性,我们首先想到的就是synchronized这个关键字,确实,这个老大哥一出来,确实是简答又容易实现。但是这个方法会造成线程切换之间的开销,这个操作是重量级的(因为CPU要保存现场和恢复现场,耗费的时间较长)其次就是cas,通过轮询的方法减少线程的切换,这种方法好处就是在不用麻烦操作系统,比较轻量级,但是也有另外一个弊端,就是线程需要轮询,会造成CPU空转,导致CPU占用过高,要是长时间几个线程一直轮询,而且是单CPU单核的情况,就会造成浪费CPU资源。这个时候就不如重量级锁来得节省资源了。还有一个方法,就是我们的threadlocal 我们可以在线程内部设置一个值,线程自己改自己的值,并将值写入到一个共享变量中,我们就可以获取到各个线程计算后的 值的和。但是在这里还有一个问题就是我们在统计的时候依然需要使用锁来实现线程各个值的相加。具体的代码实现如下:
package com.hzt.learnthreadlocal.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
/**
* @Author: hzt
* @Date: 2022/2/24 11:29
*/
@RestController
public class TestThreadLocalAdd {
Map<Thread,Integer> map = new HashMap<>();
private ThreadLocal<Integer> num = new ThreadLocal<Integer>(){
@Override
protected Integer initialValue() {
return 0;
}
};
@RequestMapping("/get")
public Integer getNum(){
int res = 0;
for(Map.Entry<Thread, Integer> entry : map.entrySet()){
res+=entry.getValue();
}
return res;
}
@RequestMapping("/getOne")
public Integer getOne(){
return num.get();
}
@RequestMapping("/add")
public Integer add(){
num.set(num.get()+1);
map.put(Thread.currentThread(),num.get());
return num.get();
}
@RequestMapping("/reset")
public Integer resetNum(){
num.set(0);
return num.get();
}
}
请求各个线程的和
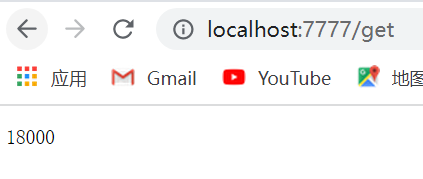
压测的数据

请求单个线程里面的ThreadLocal值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UTdLaYuu-1649319621919)(C:\Users\hzt\AppData\Roaming\Typora\typora-user-images\image-20220224185909913.png)]](https://img-blog.csdnimg.cn/c668322cb74348bb827d327f3d0690ed.png)















 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









