







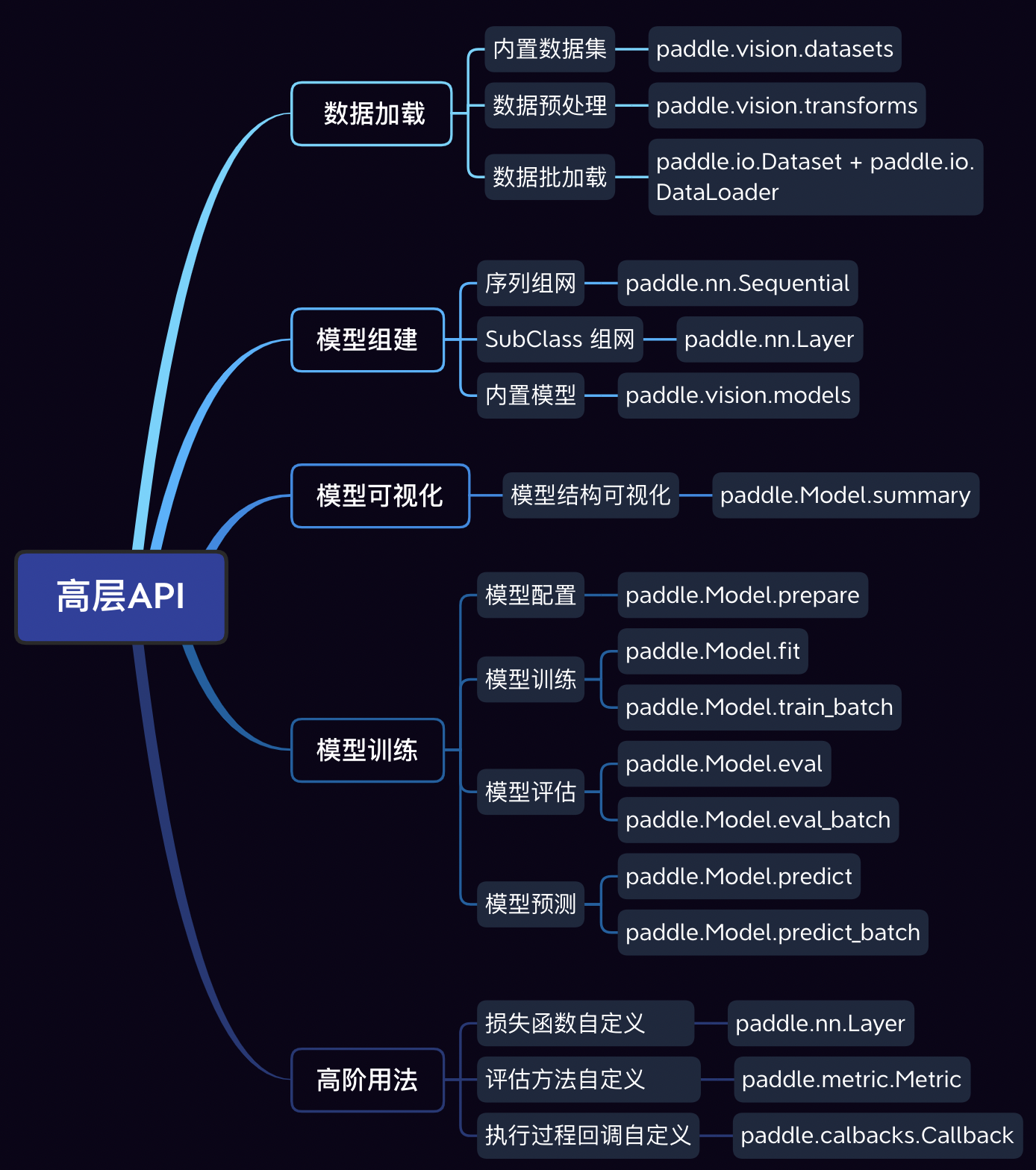
高层API全景图
!git clone https://gitee.com/paddlepaddle/Paddle.git --depth=1
1.MNIST数据集
先拜读下2.0的 MNIST PaddlePaddle 数据集定义,已经git了。地址 Paddle/python/paddle/vision/datasets/mnist.py
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import print_function
import os
import gzip
import struct
import numpy as np
from PIL import Image
import paddle
from paddle.io import Dataset
from paddle.dataset.common import _check_exists_and_download
__all__ = ["MNIST", "FashionMNIST"]
class MNIST(Dataset):
"""
Implementation of `MNIST <http://yann.lecun.com/exdb/mnist/>`_ dataset
Args:
image_path(str): path to image file, can be set None if
:attr:`download` is True. Default None
label_path(str): path to label file, can be set None if
:attr:`download` is True. Default None
mode(str): 'train' or 'test' mode. Default 'train'.
download(bool): whether to download dataset automatically if
:attr:`image_path` :attr:`label_path` is not set. Default True
backend(str, optional): Specifies which type of image to be returned:
PIL.Image or numpy.ndarray. Should be one of {'pil', 'cv2'}.
If this option is not set, will get backend from ``paddle.vsion.get_image_backend`` ,
default backend is 'pil'. Default: None.
Returns:
Dataset: MNIST Dataset.
Examples:
.. code-block:: python
from paddle.vision.datasets import MNIST
mnist = MNIST(mode='test')
for i in range(len(mnist)):
sample = mnist[i]
print(sample[0].size, sample[1])
"""
NAME = 'mnist'
URL_PREFIX = 'https://dataset.bj.bcebos.com/mnist/'
TEST_IMAGE_URL = URL_PREFIX + 't10k-images-idx3-ubyte.gz'
TEST_IMAGE_MD5 = '9fb629c4189551a2d022fa330f9573f3'
TEST_LABEL_URL = URL_PREFIX + 't10k-labels-idx1-ubyte.gz'
TEST_LABEL_MD5 = 'ec29112dd5afa0611ce80d1b7f02629c'
TRAIN_IMAGE_URL = URL_PREFIX + 'train-images-idx3-ubyte.gz'
TRAIN_IMAGE_MD5 = 'f68b3c2dcbeaaa9fbdd348bbdeb94873'
TRAIN_LABEL_URL = URL_PREFIX + 'train-labels-idx1-ubyte.gz'
TRAIN_LABEL_MD5 = 'd53e105ee54ea40749a09fcbcd1e9432'
def __init__(self,
image_path=None,
label_path=None,
mode='train',
transform=None,
download=True,
backend=None):
assert mode.lower() in ['train', 'test'], \
"mode should be 'train' or 'test', but got {}".format(mode)
if backend is None:
backend = paddle.vision.get_image_backend()
if backend not in ['pil', 'cv2']:
raise ValueError(
"Expected backend are one of ['pil', 'cv2'], but got {}"
.format(backend))
self.backend = backend
self.mode = mode.lower()
self.image_path = image_path
if self.image_path is None:
assert download, "image_path is not set and downloading automatically is disabled"
image_url = self.TRAIN_IMAGE_URL if mode == 'train' else self.TEST_IMAGE_URL
image_md5 = self.TRAIN_IMAGE_MD5 if mode == 'train' else self.TEST_IMAGE_MD5
self.image_path = _check_exists_and_download(
image_path, image_url, image_md5, self.NAME, download)
self.label_path = label_path
if self.label_path is None:
assert download, "label_path is not set and downloading automatically is disabled"
label_url = self.TRAIN_LABEL_URL if self.mode == 'train' else self.TEST_LABEL_URL
label_md5 = self.TRAIN_LABEL_MD5 if self.mode == 'train' else self.TEST_LABEL_MD5
self.label_path = _check_exists_and_download(
label_path, label_url, label_md5, self.NAME, download)
self.transform = transform
# read dataset into memory
self._parse_dataset()
self.dtype = paddle.get_default_dtype()
def _parse_dataset(self, buffer_size=100):
self.images = []
self.labels = []
with gzip.GzipFile(self.image_path, 'rb') as image_file:
img_buf = image_file.read()
with gzip.GzipFile(self.label_path, 'rb') as label_file:
lab_buf = label_file.read()
step_label = 0
offset_img = 0
# read from Big-endian
# get file info from magic byte
# image file : 16B
magic_byte_img = '>IIII'
magic_img, image_num, rows, cols = struct.unpack_from(
magic_byte_img, img_buf, offset_img)
offset_img += struct.calcsize(magic_byte_img)
offset_lab = 0
# label file : 8B
magic_byte_lab = '>II'
magic_lab, label_num = struct.unpack_from(magic_byte_lab,
lab_buf, offset_lab)
offset_lab += struct.calcsize(magic_byte_lab)
while True:
if step_label >= label_num:
break
fmt_label = '>' + str(buffer_size) + 'B'
labels = struct.unpack_from(fmt_label, lab_buf, offset_lab)
offset_lab += struct.calcsize(fmt_label)
step_label += buffer_size
fmt_images = '>' + str(buffer_size * rows * cols) + 'B'
images_temp = struct.unpack_from(fmt_images, img_buf,
offset_img)
images = np.reshape(images_temp, (buffer_size, rows *
cols)).astype('float32')
offset_img += struct.calcsize(fmt_images)
for i in range(buffer_size):
self.images.append(images[i, :])
self.labels.append(
np.array([labels[i]]).astype('int64'))
def __getitem__(self, idx):
image, label = self.images[idx], self.labels[idx]
image = np.reshape(image, [28, 28])
if self.backend == 'pil':
image = Image.fromarray(image.astype('uint8'), mode='L')
if self.transform is not None:
image = self.transform(image)
if self.backend == 'pil':
return image, label.astype('int64')
return image.astype(self.dtype), label.astype('int64')
def __len__(self):
return len(self.labels)
可见数据加载中,主要用到了paddle.vision.datasets以及paddle.vision.transforms
dataset中主要实现了数据的初始化(下载,读取)、数据增强、返回数据以及数据长度等信息。
问题思考
- 使用了数据增强,那就是返回给训练用的数据是增强过的,但是如何把原数据也加入训练集呢?
- 测试集和训练集使分开的,但如果是从训练集中划分出测试集,测试集需要不需要每次都随机从训练集中抽取?
# 引入试用的包
import paddle
# transform包,用于数据增强,归一化
from paddle.vision.transforms import Compose, Normalize
from paddle.vision.datasets import MNIST
import paddle.nn as nn
Normalize
class paddle.vision.transforms.Normalize(mean=0.0, std=1.0, data_format=‘CHW’, to_rgb=False, keys=None)
图像归一化处理,支持两种方式:
-
- 用统一的均值和标准差值对图像的每个通道进行归一化处理;
-
- 对每个通道指定不同的均值和标准差值进行归一化处理。
output[channel] = (input[channel] - mean[channel]) / std[channel]
参数
- mean (int|float|list) - 用于每个通道归一化的均值。
- std (int|float|list) - 用于每个通道归一化的标准差值。
- data_format (str, optional): 数据的格式,必须为 ‘HWC’ 或 ‘CHW’。 默认值: ‘CHW’。
- to_rgb (bool, optional) - 是否转换为 rgb 的格式。默认值:False。
- keys (list[str]|tuple[str], optional) - 与 BaseTransform. 默认值: None。
返回值numpy归一化后的数组
# 数据预处理,这里用到了随机调整亮度、对比度和饱和度
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 数据加载,在训练集上应用数据预处理的操作
# 可以看到自动下载了数据集,并完成train、test数据集实例化
train_dataset = MNIST(mode='train', transform=transform)
test_dataset = MNIST(mode='test', transform=transform)
问题思考
- 测试集也需要数据增强吗?
- 此处的数据增强其实做的就是数据归一化的工作。
2.模型组网
- paddle.nn.Flatten(start_axis=1, stop_axis=- 1) 该接口用于构造一个 Flatten 类的可调用对象。即展开为一维Tensor。
- paddle.nn.Sequential(*layers) 顺序容器。子Layer将按构造函数参数的顺序添加到此容器中。传递给构造函数的参数可以Layers或可迭代的name Layer元组。
- paddle.nn.Linear(in_features, out_features, weight_attr=None, bias_attr=None, name=None) 线性变换层 in_features, out_features输入输出单元数目
- paddle.nn.Dropout(p=0.5, axis=None, mode="upscale_in_train”, name=None) Dropout是一种正则化手段,该算子根据给定的丢弃概率 p ,在训练过程中随机将一些神经元输出设置为0,通过阻止神经元节点间的相关性来减少过拟合。 p:丢弃概率,默认0.5。
- paddle.nn.ReLU(name=None) ReLU激活层(Rectified Linear Unit) ReLU(x)=max(0,x)
# 模型组网
mnist = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 10)
)
3.模型封装
- class paddle.Model
- Model 对象是一个具备训练、测试、推理的神经网络。该对象同时支持静态图和动态图模式,通过 paddle.enable_static() 来切换。需要注意的是,该开关需要在实例化 Model 对象之前使用。输入需要使用 paddle.static.InputSpec 来定义
# 模型封装,用Model类封装
model = paddle.Model(mnist)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/distributed/parallel.py:119: UserWarning: Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything.
"Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything."
# 或者
# inputs and labels are not required for dynamic graph.
from paddle.static import InputSpec
input = InputSpec([None, 784], 'float32', 'x')
label = InputSpec([None, 1], 'int64', 'label')
model = paddle.Model(mnist, input, label)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/distributed/parallel.py:119: UserWarning: Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything.
"Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything."
4.模型配置
# 模型配置:为模型训练做准备,设置优化器,损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
5.模型训练
fit(train_data=None, eval_data=None, batch_size=1, epochs=1, eval_freq=1, log_freq=10, save_dir=None, save_freq=1, verbose=2, drop_last=False, shuffle=True, num_workers=0, callbacks=None)
常用参数解析
- save_dir (str|None) - 保存模型的文件夹,如果不设定,将不保存模型。默认值:None。
- save_freq (int) - 保存模型的频率,多少个 epoch 保存一次模型。默认值:1。
- shuffle (bool) - 是否对训练数据进行洗牌。当 train_data 为 DataLoader 的实例时,该参数会被忽略。默认值:True。
- drop_last (bool) - 是否丢弃训练数据中最后几个不足设定的批次大小的数据。默认值:False。
- verbose (int) - 可视化的模型,必须为0,1,2。当设定为0时,不打印日志,设定为1时,使用进度条的方式打印日志,设定为2时,一行一行地打印日志。默认值:2。
# 模型训练
# model.fit(train_dataset,
# epochs=5,
# batch_size=64,
# verbose=1)
# 训练配置可以据此设置
model.fit(train_dataset,
epochs=5,
batch_size=64,
save_freq=10,
save_dir="out",
drop_last=False,
shuffle=True,
verbose=1)
6.模型评估
evaluate(eval_data, batch_size=1, log_freq=10, verbose=2, num_workers=0, callbacks=None):
在输入数据上,评估模型的损失函数值和评估指标
- eval_data (Dataset|DataLoader) - 一个可迭代的数据源,推荐给定一个 paddle paddle.io.Dataset 或 paddle.io.Dataloader 的实例。默认值:None。
- batch_size (int) - 训练数据或评估数据的批大小,当 eval_data 为 DataLoader 的实例时,该参数会被忽略。默认值:1。
- log_freq (int) - 日志打印的频率,多少个 step 打印一次日志。默认值:1。
- verbose (int) - 可视化的模型,必须为0,1,2。当设定为0时,不打印日志,设定为1时,使用进度条的方式打印日志,设定为2时,一行一行地打印日志。默认值:2。
- num_workers (int) - 启动子进程用于读取数据的数量。当 eval_data 为 DataLoader 的实例时,该参数会被忽略。默认值:True。
- callbacks (Callback|list[Callback]|None) - Callback 的一个实例或实例列表。该参数不给定时,默认会插入 ProgBarLogger 和 ModelCheckpoint 这两个实例。默认值:None。
model.evaluate(test_dataset, verbose=1)
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 10000/10000 [==============================] - loss: 5.0068e-06 - acc: 0.9725 - 2ms/step
Eval samples: 10000
{'loss': [5.006803e-06], 'acc': 0.9725}
7.模型保存与载入
模型训练好了,不保存可怎么行呢?且看下面如何保存。
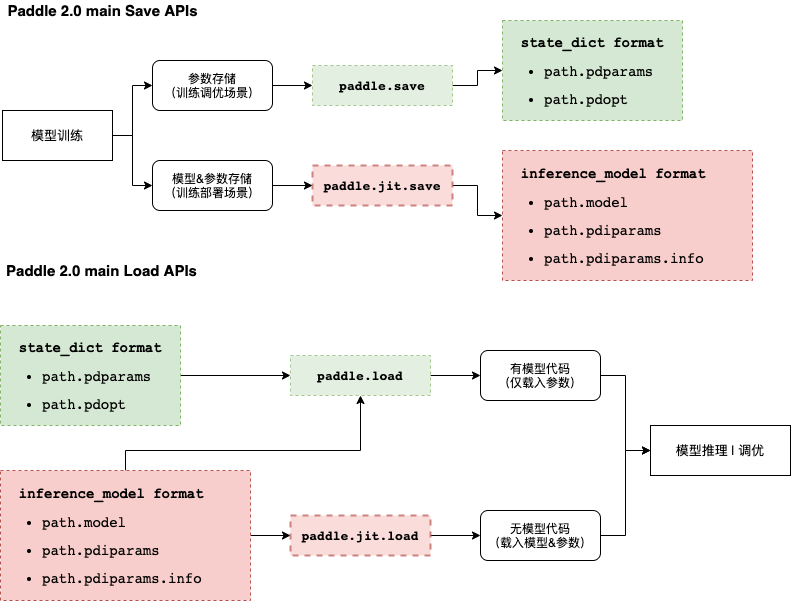
- paddle.Model.save
- paddle.Model.load
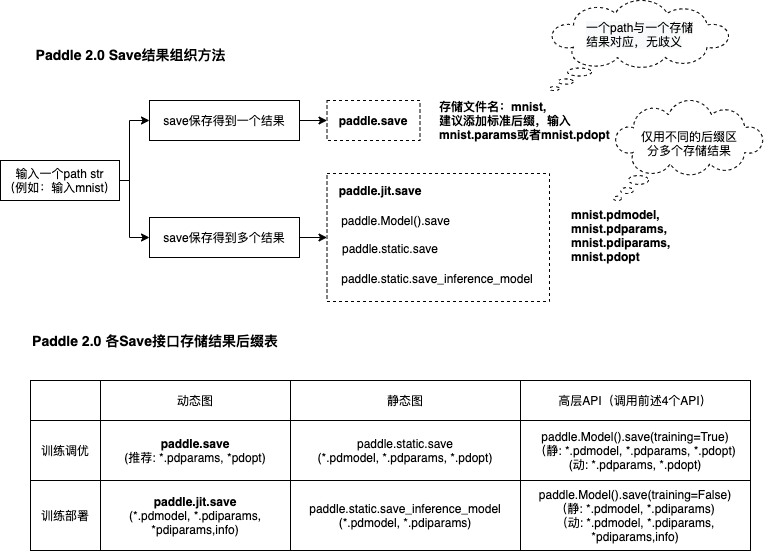
# 保存训练模型
model.save("out_model/best", training=True)
模型载入
import paddle
import paddle.nn as nn
from paddle.static import InputSpec
device = paddle.set_device('cpu')
input = InputSpec([None, 784], 'float32', 'x')
label = InputSpec([None, 1], 'int64', 'label')
model2 = paddle.Model(nn.Sequential(
nn.Linear(784, 200),
nn.Tanh(),
nn.Linear(200, 10),
nn.Softmax()),
input,
label)
model.load('out_model/best')
8.模型预测
predict(test_data, batch_size=1, num_workers=0, stack_outputs=False, callbacks=None):
- test_data (Dataset|DataLoader) - 一个可迭代的数据源,推荐给定一个 paddle paddle.io.Dataset 或 paddle.io.Dataloader 的实例。默认值:None。
- batch_size (int) - 训练数据或评估数据的批大小,当 eval_data 为 DataLoader 的实例时,该参数会被忽略。默认值:1。
- num_workers (int) - 启动子进程用于读取数据的数量。当 eval_data 为 DataLoader 的实例时,该参数会被忽略。默认值:True。
- stack_outputs (bool) - 是否将输出进行堆叠。默认值:False。
- callbacks (Callback|list[Callback]|None) - Callback 的一个实例或实例列表。默认值:None。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









