







当我觉得一篇博文讲完数据库索引之后,才发现还有好多索引的知识没有涉及。
这篇博文涉及到的知识点如下:覆盖索引、回表、索引统计信息、行式数据库、列式数据库、数据库中的存储结构、InnoDB存储引擎中缓冲池和查询缓存
希望能够给你 SQL 优化提供更多的思路和建议。
再谈聚集索引
- 如果表设置了主键,则主键就是聚集索引
- 如果表没有创建主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚集索引
- 以上都没有,则会默认创建一个隐藏的row_id作为聚集索引
非聚集索引查找过程:
如果查询条件为普通索引(非聚集索引),需要扫描两次 B+树,第一次扫描通过普通索引定位到聚集索引的值,然后第二次扫描通过聚集索引的值定位到要查找的行记录数据
例如:
SELECT * FROM user WHERE age='30';
- 先通过普通索引 age=‘30’ 定位到主键值 id =‘1’
- 在通过聚集索引 id =‘1’ 定位到行记录数据
回表查询
先通过普通索引定位到聚集索引的值,然后第二次扫描通过聚集索引的值定位到要查找的行记录数据,需要扫描两次索引B+树,它的性能较扫一遍索引树更低。
索引覆盖
只需要在一棵索引树上就能获取SQL所有的列数据,无需回表,速度更快。
例如:
SELECT id,age FROM user WHERE age='10';
如何实现覆盖索引
常见的方法是:将被查询的字段,建立到联合索引里去。
例如:
select id,name from user where age='10';
explain分析:因为age是普通索引,使用到了age索引,通过一次扫描B+树即可查询到相应的结果,这样就实现了覆盖索引

SELECT id,age,name FROM user WHERE age = 10;
explain分析:age是普通索引,但name列不在索引树上,所以通过age索引在查询到id和age的值后,需要进行回表再查询name的值。此时的Extra列的NULL表示进行了回表查询

为了实现索引覆盖,需要建组合索引idx_age_name(age,name)
DROP INDEX idx_age ON user;
CREATE INDEX idx_age_name ON user(`age`,`name`);
explain分析:此时字段age和name是组合索引idx_age_name,查询的字段id、age、name的值刚刚都在索引树上,只需扫描一次组合索引B+树即可,这就是实现了索引覆盖,此时的Extra字段为Using index表示使用了索引覆盖。

索引统计信息
Mysql 优化器主要是根据表的索引统计信息来计算SQL执行花费的成本,选择不同的索引,花费的成本不同,优化器会选择花费更低的索引方案。
因为INNODB表的统计信息并不是实时统计更新,如果统计信息和实际的索引信息差异很大,就会导致优化器计算各个索引成本后,做出非预期的选择。
首先,我们来看看innodb表统计信息的相关因素:
-
innodb_stats_persistent_sample_pages
innodb表信息统计采样页数,默认20,该值越大,统计信息 约准确,耗时也就越长 -
innodb_stats_persistent
统计信息是否持久化到磁盘,默认开启 -
innodb_stats_auto_recalc
是否自动更新统计信息,默认开启,表更新超过10%记录会自动重新统计表信息进行更新 -
mysql.innodb_table_stats(innodb表统计信息存储表)
database_name:库名
table_name:表名
last_update:最近更新时间
n_rows:记录数
clustered_index_size:主键索引页数
sum_of_other_index_sizes:非主键索引页数
- mysql.innodb_index_stats(innodb表索引信息存储表)
database_name:库名
table_name:表名
index_name:索引名
last_update:最近更新时间
stat_name:统计项
stat_value:统计项值
sample_size:统计采样页数
stat_description:统计项说明
innodb_index_stats常用统计项说明
n_diff_pfx{NUM}:该索引统计项不同的值有多少,对于非联合索引,NUM均为 01,联合索引该项表示前NUM列组合不同的值的有多少,如n_diff_pfx02表示该索引 key1,key2组合有多少个不同的值。
n_leaf_pages:该索引叶子节点页数
size:索引总页数
1. 表在更新10%以上数据或手动执行analyze table xx时会重新统计表信息
2. 表统计信息不准确,可以手动查出表索引精确的信息,然后更新至innodb_table_stats、innodb_index_stats相关统计项中,最后通过flush table xx使手动更新统计项生效,执行flush table xx注意慢语句。
mysql中⼀张表⽀持多个索引,但是在写SQL语句的时候,并没有主动指定使⽤哪个索引。
常用的命令备查
SET long_query_time=0 慢查询⽇志的阈值设置为0,表⽰这个线程接下来的语句都会记录到慢查询⽇志
SHOW index FEOM tab1 来查 索引的基数。这个基数越大,索引的区分度越好。
SELECT * FROM t FORCE INDEX(a) WHERE a BETWEENT 10000 AND 20000; 使用强制索引a进行查询
ANALYZE table1 重新统计索引表
SHOW INDEX FROM celery_taskmeta 表索引信息,注意cardinality的值,为该索引统计不同值的个数:
SELECT COUNT(*) FROM operation.celery_taskmeta 手动统计
UPDATE mysql.innodb_table_stats set n_rows=10104654 WHERE table_name='celery_taskmeta'; 手动更新下表统计信息为人工查出来的结果
FLUSH TABLE celery_taskmeta 刷新下表
数据库分类
行式数据库(Row-Based),数据按行存储。常见的行式数据库有Mysql,DB2,Oracle,Sql-server等;
列式数据库(Column-Based)数据存储方式按列存储,常见的列数据库有Hbase,Hive,Clickhouse,Sybase 等。
行存储的特点
数据是按行存储的
没有索引的查询会消耗大量的IO资源
建立索引和视图需要耗费大量的时间和系统资源
面对高并发的查询,数据库必须被大量膨胀才能满足性能需求
列存储特点
数据按列存储—每一列单独存放
数据即是索引,无须另建索引
只访问查询所涉及到的列(与行数据库不同)--节省IO开支
可以高效压缩
查询的并发处理性能高
数据库中的存储结构
记录是按照行来存储的,但是数据库的读取并不以行为单位,否则一次读取(也就是一次 I/O 操作)只能处理一行数据,效率会非常低。
因此在数据库中,不论读一行,还是读多行,都是将这些行所在的页进行加载。也就是说,数据库管理存储空间的基本单位是页(Page)。
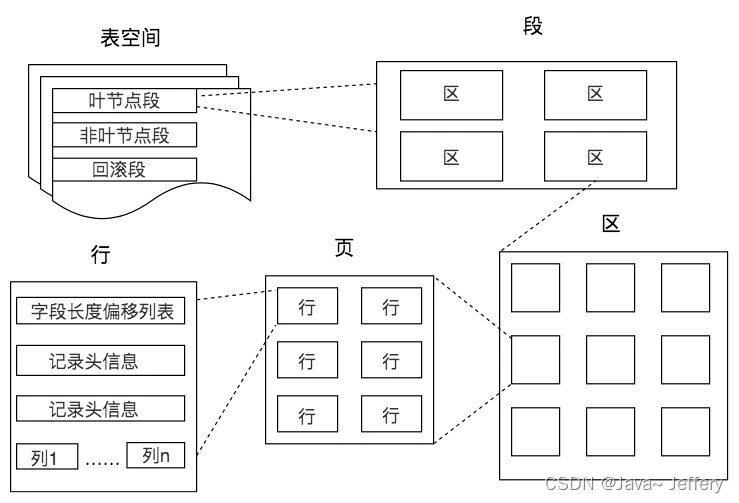
SQL 查询是一个动态的过程,从页加载的角度来看,我们可以得到以下两点结论:
- 位置决定效率。如果页就在数据库缓冲池中,那么效率是最高的,否则还需要从内存或者磁盘中进行读取,当然针对单个页的读取来说,如果页存在于内存中,会比在磁盘中读取效率高很多。
- 批量决定效率。如果我们从磁盘中对单一页进行随机读,那么效率是很低的(差不多 10ms),而采用顺序读取的方式,批量对页进行读取,平均一页的读取效率就会提升很多,甚至要快于单个页面在内存中的随机读取。
mysql> SHOW STATUS LIKE 'last_query_cost'; 统计刚才执行的SQL语句需要加载多少个页面
InnoDB存储引擎中缓冲池
在InnoDB存储引擎中有一部分数据会放到内存中,缓冲池则占了这部分内存(In-Memory Structures)的大部分,它是用来存储各种数据的缓存,包括了数据页,索引页,插入缓冲,锁信息,自适应Hash,数据字典信息等。
为什么要使用缓冲池技术呢,这是因为InnoDB存储引擎是基于磁盘文件存储的,我们在访问物理硬盘和在内存中进行访问速度相差很大,为了尽可能弥补这中间的IO效率鸿沟,我们就需要把经常使用的数据加载到缓冲池中,避免每次访问都进行磁盘IO,从而提升数据库整体的访问性能。所以说“频次X位置”的原则,帮我们对IO访问效率进行了优化:
1)位置决定效率,提供缓冲池就是在内存中可以直接访问到数据,因此效率可以大幅提升
2)频次决定优先级顺序,因为缓冲池的大小是有限的,比如我们的磁盘有200G,但是内存只有16G,缓冲池大小只有1G,那么这时无法将所有数据都加载到缓冲池里,这里就有个优先级顺序的问题,也就是对经常使用频次高的热数据进行加载。
在了解了缓冲池作用之后,我们还需要了解缓冲池的另一个特性:预读。
因为缓冲池的作用就是提升IO效率,而我们进行读取数据的存在一个“局部性原理”,也就是我们使用了一些数据,大概率还会使用它周围的一些数据。因此我们可以采用“预读”的机制来减少未来的磁盘IO操作,进行提前加载。
查询缓存
查询缓存是提前把查询结果缓存起来,这样下次就不需要执行可以直接拿到结果。需要说明的是,在MySQL中的查询缓存,不是缓存查询计划,而是查询及对应的查询结果。这就意味着查询匹配的鲁棒性大大降低,只有相同的查询操作才会命中查询缓存。因此在MySQL的查询缓存命中率不高,在MySQL8.0版本中已经弃用了查询缓存功能。查看是否使用了查询缓存,使用命令:show variables like '%query_chache%';
所以说缓冲池不等于查询缓存,他们两个存在共同的特点就是都是通过缓存的机制来提升效率。而缓冲池是服务于数据库整体的IO操作,通过建立缓冲池机制来弥补存储引擎的磁盘文件与内存访问之间的效率鸿沟,同时缓冲池会采用“预读”的机器提前加载一些马上会用到的数据,以提升整体的数据库性能。而查询缓存是服务于SQL查询和查询结果集的,因为命中条件苛刻,而且只要当数据表发生了变化,查询缓存就会失效,因此命中率低,在MySQL8.0版本中已经弃用了该功能。
















 3432
3432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











