






#特斯拉的“纯视觉”路线 , 也许不是最好的
BEV+Transformer+占用网络技术路线的大热,再次将激光雷达推向风口浪尖。
激光雷达该不该被抛弃?
对车企来说,这是一个艰难的抉择:是坚定不移跟随特斯拉走具有「性价比」的纯视觉路线,还是采用看起来「成本稍高」的激光雷达融合方案?
要回答这个问题并不难——尤其是当你洞悉事情的真相是反常识的时候。
比如,去除激光雷达,看起来减掉的是智能驾驶系统的 BOM 成本,整车成本也随之下降了,但冰山之下的隐性成本增加了多少,你计算过吗?
再比如,占用网络的白名单可以覆盖包括机动车、行人、两轮车、锥桶、水马、路面、树木等十几个常见的「道路物体」,但白名单之外的物体,它能看见吗?
在城市 NOA 大规模落地前夕,整个智能驾驶行业需要重新审视纯视觉方案背后的成本和技术难易程度,以及激光雷达的核心价值。
「抄特斯拉作业」是否是最佳选择?在城市 NOA 落地浪潮下,车企如何集中优势发挥所长?
这些都是需要被优先考虑的问题。
01 模仿特斯拉,不该忽略纯视觉路线背后的「隐性成本」
「4 颗以下,请别说话。」这可能是此前汽车行业「卷」激光雷达最出圈的表达。
到今天,激光雷达仍然是绝大部分头部车企新车的标配。从蔚小理,再到华为(问界、阿维塔)、极氪、零跑,激光雷达在国内能够快速量产上车,很大程度上是由他们直接或间接推动的。
激光雷达的风靡,来自其带给消费者的科技感和安全感。
而当「降本」的旋风刮来,在特斯拉跑通纯视觉方案之后,「去激光雷达」的声音又此起彼伏。
短期看,拿掉激光雷达,「降本效果」立现。
然而从长期看,车企需要为这一选择投入更多的研发资源。
禾赛科技战略负责人施叶舟认为,「在考虑成本的时候,不能够只看到硬件成本,实际上更要考虑背后所需要各种研发服务和资源投入,也就是『全成本』——除了冰山上面的显性成本(硬件、BOM 成本),还有大量被忽视的隐性成本。」
这里所称的纯视觉技术路线中的「隐性成本」,包括算法、路测、云计算、数据标注、仿真训练和系统软件等。
特斯拉前 AI 高级总监 Andrej Karpathy 曾在公开演讲时说到:「纯视觉能够精准感知深度、速度、加速度信息,实现纯视觉是一件困难的事情,还需要大量数据。」
换句话说,特斯拉作业并不好抄,门槛和壁垒极高。

这主要体现在三个方面:
一是海量数据。
特斯拉的自动驾驶算法是业内公认能力最强、投入最大、研发最早的。截至目前,特斯拉 FSD 累积行驶里程已超 5 亿英里,Autopilot 使用里程已经超过 90 亿英里。
特斯拉的自动驾驶系统每天可以接收到车队回传的 1600 亿帧视频数据,支持神经网络训练。众所周知,数据积累取决于累计交付量和行驶里程,如此大的数据体量,也意味着需要投入大量的时间成本。
其次是自研芯片。
特斯拉自 2014 年开始自研芯片之路,2019 年发布了 FSD 自研芯片。
为了提升数据处理能力,为进一步的深度学习量身定制,2021 年 8 月,特斯拉发布了用于神经网络训练的自研芯片 D1,D1 芯片基于 7nm 工艺打造,算力可达 362TFLOPS。
D1 芯片具备较强的可扩展性,25 个芯片可组成一个计算模块,而 120 个计算模块可以组成外界熟知的「Dojo ExaPOD」超级计算机。
第三是围绕算法训练搭建的超算中心。
在特斯拉自建的大数据中心中,使用了 14,000 片 GPU 芯片,其中 10000 片用于 AI 训练的 H100,4000 片用于数据标注。
据了解,一片 H100 芯片官方售价 3.5 万美元,尽管在黑市被炒到 30~40 万元人民币,依然是「一片难求」。
特斯拉上线 H100 GPU 集群的同时,还激活了自研的超级计算机群组 Dojo ExaPOD,开启云端算力竞赛,以支持自动驾驶技术的更新迭代。
Dojo 于 2023 年 7 月开始生产部署,马斯克曾表示,到 2024 年,特斯拉还将向 Dojo 再投资 10 亿美元。预计到 2024 年 10 月,Dojo 算力会达到 100Exa-Flops。
从这个角度看,光是算法训练的芯片投入就十分惊人,达到数十亿元。
基于这样的数据,我们可以做一个简单的数学推算:
假设要开发一个特斯拉式纯视觉路线的高阶智能驾驶系统,这个方案总投入大约在 200 亿元。
试想一下,要压低这个成本需要多大规模的销量?
——当汽车销量到 2000 万辆时,每辆车的自动驾驶成本可以降到 1000 元。
——而当汽车销量只有几十万、上百万辆时,这笔投入该如何摊销?
当前,特斯拉累计销量超过 400 万辆,其所释放的规模效应让友商们难以企及。因此,特斯拉选择视觉路线,不只是「算法能力强」,更是建立在巨大的保有量、车载芯片自研、数据回环和自动化标注、自建超算中心训练模型等一系列能力之上的综合实力。
02 占用网络不是「万能钥匙」激光雷达仍是「最佳助攻」
2016 年 1 月 20 日,在辅助驾驶状态下,一辆特斯拉撞上了一堵静止的水泥隔离墙上。这是特斯拉首起「自动驾驶」事故。
当时,对特斯拉的唱衰之声不绝于耳。但经过 7 年探索,特斯拉如今在自动驾驶领域一骑绝尘。当特斯拉跑通自动驾驶之后,其他车企开始转向了「大模型」路线,沿着特斯拉从 BEV 向占用网络迭代之路进化。
不过,即便不惜成本投入堆起来的「占用网络」,对于通用障碍物的识别仍然无法做到「天衣无缝」。
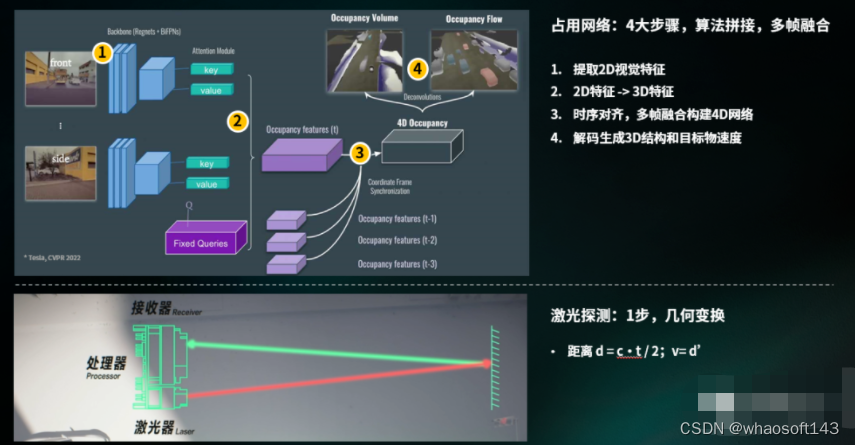
占用网络,是一套基于神经网络的算法,是在时序对齐、多帧数据融合下构建的 4D 网络。
「因为拼接了很多算法,涉及到多帧融合。不可避免就会有一定程度的延时。」对于国内车企来说,在车端有限的算力之下,如何兼顾「高精度」和「低延时」存在诸多考验。
更重要的是,占用网络技术会因视觉缺失 3D 信息而导致漏检、误检。
为了视觉算法输出结果比较准确,需要源源不断的数据输入和迭代以提高精准度。
在车辆覆盖没有到一定规模前,尚且无法获得更多数据——这正是不少车企现阶段对「去掉激光雷达」保持谨慎,而选择「摄像头+激光雷达」融合感知路线的原因。
相比于算法,激光雷达具备「硬件本能」,不需要经过大量复杂的计算和假设,以及数据训练就可以得到纯视觉方案需要的某些数值。
相比纯视觉方案,激光雷达能够应对不易处理的 corner case(边缘场景),弥补摄像头可能出现的误判。

在融合方案中,激光雷达存在多个公认的核心优势:
一是「抗干扰」,不惧夜间环境。
据 MIT 团队 2022 年的研究结果表明,配备了激光雷达的融合方法将夜间的感知精度提高 3 倍。
二是「真三维」,精度更高。
激光雷达基于三维坐标,能精确到厘米级别为算法提供地面和物体的相对位置。地面上的高低不平的路况,一些低矮物体,激光雷达也能够捕捉到。

三是「高置信度」,识别物体数量更多。
纯视觉方案会建立覆盖常见「道路物体」(机动车、行人、两轮车、锥桶、水马、路面、树木等)的白名单。白名单之外,可能「视而不见」。
通过激光雷达直接获取实时 3D 数据后,车辆可以直接判断障碍物是否存在,为占用网络提供真值输入,在融合方案里作有力补充,提升系统安全性。

此外,激光雷达的反应速度更快。在中国城市内存在复杂路况,比如闹市区里车辆突然的加塞、变道等,激光雷达相比摄像头的反应速度更快,能够准确判断对方移动速度。
值得一提的是,在最近行业大热的话题「如何降低 AEB 的误触发率」上,激光雷达也可以帮助避免一些常见的安全隐患。
施叶舟表示,「AEB 的误触发,背后的本质原因是感知精度不够高。在激光雷达加持下,周围感知精度的提升,误触发可以大大减少」。以搭载激光雷达的理想 L9 Max 为例,采用多传感器融合方案之后,每 10 万公里的误触发次数远远低于行业均值。
综合来看,占用网络技术不是一个解锁通用障碍物识别的万能钥匙,而激光雷达在提升安全性的过程中,有着举足轻重的作用。
03 激光雷达融合方案 高阶智能驾驶落地的「助跑器」
城市 NOA 正在迎来一个高光时刻——问界新 M7 累计大定已超过 8 万台,其中超过 60% 用户选择了智驾版(激光雷达版);小鹏新 G9 激光雷达版本选配比例高达 80%。
在此之前,一款车的智能驾驶搭载率只能达到 20%~30% 左右。问界和小鹏新车的智能驾驶选配率,远远超过了行业预期。
城市 NOA 迅速落地的背后,给广大的消费者体验带来根本变化是最主要的驱动力。
要实现更大范围的自动驾驶的覆盖,要切入真正的高频和刚需场景,先走到距离用户最近的地方。
数据显示,汽车平均有 71% 的里程是在城市道路行驶,对应时间占车主总驾车时长的 90%。而华为和小鹏得以更快落地城市 NOA,激光雷达功不可没。
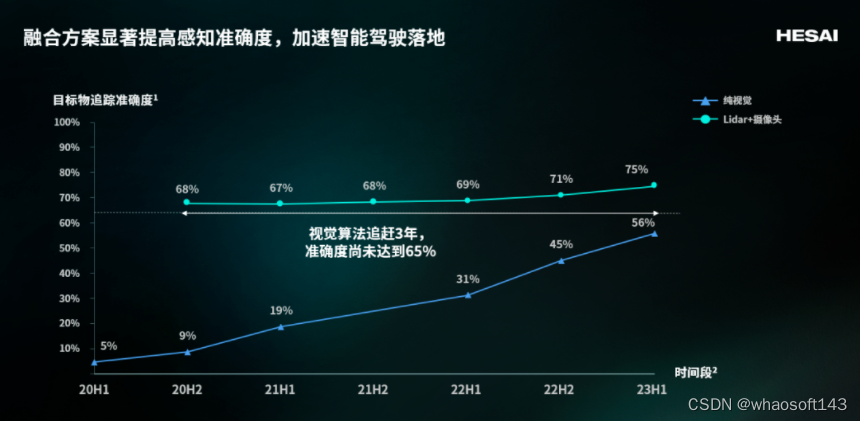
智能驾驶权威测评机构 nuScences 的数据显示:
截止 2023 年上半年,纯视觉方案(摄像头)和融合方案(激光雷达+摄像头)对目标物追踪准确度(AMOTA)上仍有较大差距:二者相差接近 20 个百分点(56% VS. 75%)。
预计到 2025 年,纯视觉方案准确度的均值会达到 70%~71%。这一数字相比配备激光雷达的融合方案在 22 年的准确度落后了 3 年时间。
换个角度来看,激光雷达融合方案可以让高阶智能驾驶落地时间缩短 3 年。

轻舟智航产品负责人许诺直言,现阶段单纯依靠视觉方案,很难应对中国城市道路中的各类 Corner Case。「激光雷达,是以投入换时间,加速城市 NOA 落地的捷径。」
「当你做视觉方案时,系统遇到未知或者通用障碍物识别时,激光雷达方案的优势是突出的。像路上突然掉下来的物体,例如纸箱、木箱等,通过激光雷达能够感应到。而且激光雷达可以告诉你,前面有障碍物,也会告诉你做分类处理。」许诺说道。
由此看来,激光雷达不仅是智能汽车里的「隐形安全气囊」,更是辅助车企量产落地城市 NOA 的捷径。
在国内市场,蔚来、理想、小鹏、仰望、智己、极氪、问界、阿维塔等汽品牌,在已经量产或即将上市的车型中,都配备了激光雷达。
在海外,布局 L3 智能驾驶功能的头部车企也都配备了激光雷达,包括已经获得 L3 监管批准的奔驰,以及正在布局的宝马、沃尔沃等。
下一步,高阶辅助驾驶若要向大众市场持续渗透,系统成本有望继续下探。
施叶舟表示,禾赛正在通过核心零部件芯片化等技术降本手段,以及放大规模效应的优势,为城市 NOA 持续落地服务。目前,禾赛已将激光雷达的价格从几年前的几十万元,降到了现在的几千元,做到了十倍以下。
到那时,激光雷达的高成本,或许也不再是阻碍其大规模上车的门槛。
车企是否都要走特斯拉的纯视觉方案,最终要量力而为。而从现阶段来看,激光雷达不仅可以成为城市 NOA 落地的「助跑器」,在未来也能够继续发挥其独特价值,做自动驾驶领域的「最强助攻」。
#BEV车道线落地
看过BEV障碍物故事的同学应该清楚,我们组是在21年10月左右开始做BEV 障碍物的。那个时候不敢想着去做BEV 车道线,因为没有人力。但是我记得在12月左右的时候,我们面到了一个候选人,在面试的过程中听到他们做了差不多半年多的BEV 车道线,整个技术路线是通过高精地图来作为BEV 车道线网络的训练真值,并说效果还不错。很遗憾,那个候选人最后没有来我们这里。结合21年Telsa AI day 讲的车道线内容,一个要做BEV 车道线的种子就这样在组内埋下了。
整个22年,我们组内人力都是很紧张的,我记得在6,7月份的时候,我们刚好有人力去探索一下BEV 车道线。但是当时我们组只有一个同学(我们就先叫他小轩同学吧)有2个月的时间去做这件事。然后21年的那颗种子开始发芽了,我们准备先从数据下手,小轩同学还是很给力的(很有想象力,后续小轩同学也做了更多令大家惊喜的东西),差不多用了2月的时间,我们可以通过高速高精地图来提取对应的车周围的车道线数据。当时做出来的时候,我记得大家还是很激动的。

图1: 高精地图车道线 投影到图像系的效果
大家从图1上可以看出,贴合对还是有一些问题,因此小轩同学又做了系列的优化。2个月后,小轩同学去做其他任务了,现在回头看,我们的BEV 车道线探索之路,已经走对了第一步。因为在21年,22年已经逐步有很多优秀的BEV 车道线论文和代码相继开源。看到这里,你可能以为23年一定有一个完完美美的BEV 车道线落地的故事,然后理想往往都很丰满,现实却是很残酷。
由于我们BEV 障碍物已经证明BEV 这条路是可以走下去了,并且在路测也表现出了不错的效果。组内开始有了更多的资源来考虑车道线这件事,注意这里不是BEV了。为什么呢?因为在这个时候,我们面临了很大的上线压力,BEV 车道线又没有足够的经验,或者说整个组内做过2D 车道线量产的人都几乎没有。23年前半年,真的可以用跌跌撞撞来形容,我们内部激烈的讨论了很多次,最后决定形成2条线,一条线为2D 车道线: 大部分的人力在2D 车道线这条线上,重后处理,轻模型,通过2D 车道线这条线来积累车道线后处理量产经验。一条线为BEV 车道线:只有一小部分人力(其实就1-2个人力),注重BEV 车道线的模型设计, 积累模型经验。BEV 车道线的网络已经有很多了,我在这里贴2篇对我们影响比较大的论文供大家参考。《HDMapNet: An Online HD Map Construction and Evaluation Framework》 和 《MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction》
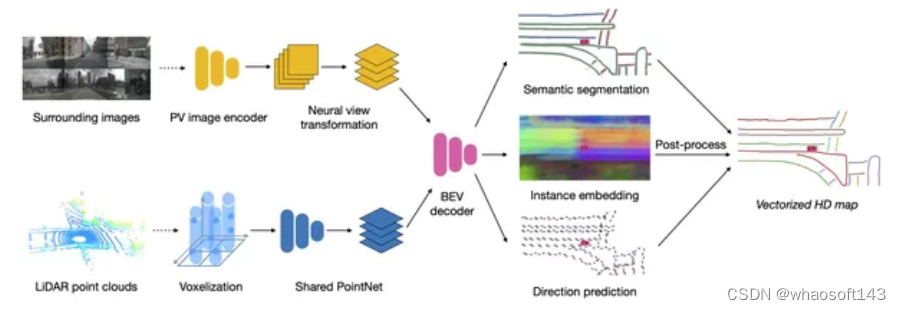
图2: HDMapNet
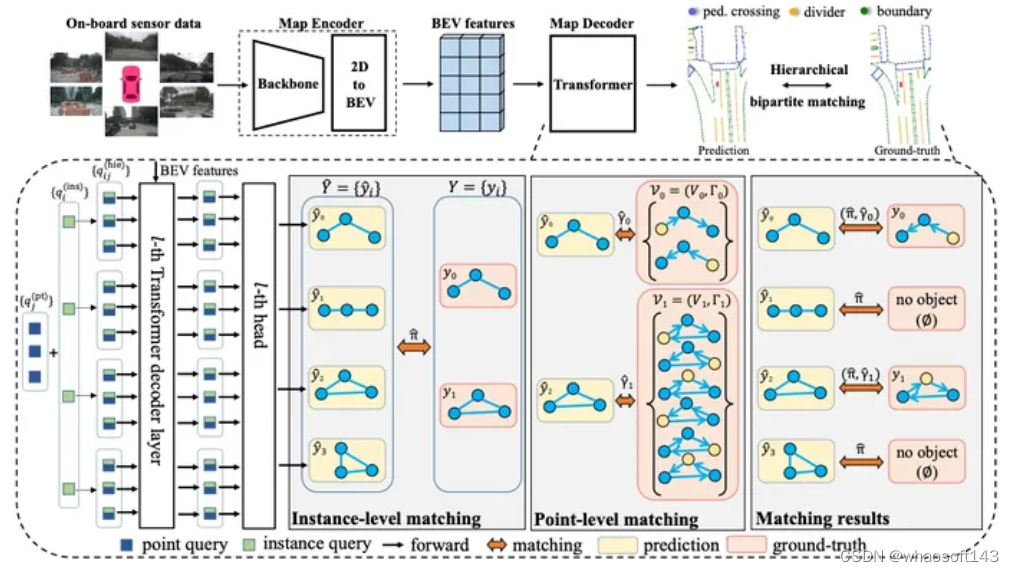
图3 MapTR
很幸运,在4,5月份的时候,我们在2D 车道线这条线积累了大量的车道线后处理量产经验,我们的BEV 车道线网络也设计出来了,在5月底,很快BEV 车道线顺利上车。在这里不得不说一下我们负责车道线后处理的大海同学,还是很给力的。然而当你觉得很顺利的时候,往往噩梦就要开始了。BEV 车道线部署后,控车效果不理想,这个时候大家陷入了自我怀疑阶段,到底是因为BEV 车道线3次样条曲线拟合的问题,还是下游参数没有适配好的问题。万幸的是,我们车上有供应商的效果,我们在路测时把供应商的车道线结果保存下来,然后在可视化工具里面在和我们的结果对比。当控车效果不好的时候,先证明我们自己的车道线质量是没有问题,这样驱动下游来适配我们的BEV车道线。一个月,整整一个月的时间,我们才稳定控车。我记得很清楚,我们还从上海跑到苏州,那天还是周六,大家在群里看到高速的控车效果都很激动。
然而一个故事往往都是一波三折的,我们只能利用高速高精地图来生产车道线数据。城市怎么办,还有那么多badcase 需要解决。这个时候重要人物终于要出现了,我们就先叫他小糖同学吧(我们数据组的大管家)。小糖同学他们利用点云重建来给我们重建出来重建clip(这个过程还是蛮痛苦,我记得那两个月是他们压力最大的时候,哈哈,当然我们和小糖同学经常相爱相杀,毕竟经常在开会时常常说又没有数据了。)。然后重建出来后怎么标注,放眼当时手里的供应商们,都没有这样的标注工具,别说什么标注经验了。又是和小糖同学他们一起,经历了漫长的1个月时间,标注工具终于和供应商打磨好了。(我们经常开玩笑说,我们这是在赋能整个自动驾驶的标注行业,这个过程是真痛苦,重建clip 加载是真慢 )。然而整个标注还是比较慢的,或者比较贵,这个时候小轩同学带着他的车道线预标注大模型闪亮登场(车道线预标注的大模型效果还是杠杠的),大家看他的眼神都在闪闪发光。这一套组合拳打下来,我们的车道线数据生产终于是磨合的差不多了。8月份的时候我们的BEV 车道线控车道线已经迭代的不错了,对于简单的高速领航功能。现在小轩同学在大模型预标注方向依旧不断的给我们带来更多的惊喜,我们和小糖同学依旧在相爱相杀中。
然而一个故事都不是这么容易结束,我们在9月份的时候,开始动手做多模态(Lidar,camera,Radar)多任务(车道线,障碍物,Occ)前融合模型,并后续支持城市领航功(NCP), 也就是所谓的重感知,轻地图的方案。基于BEV障碍物和BEV 车道线的经验前融合网络我们很快就部署上车了,应该是在9月底的时候。车道线也加了很多子任务,路面标识别,路口的拓扑等等。在这个过程中,我们对BEV 车道线的后处理进行了升级,抛弃了车道线3次样条曲线拟合,而采用点的跟踪方案,点的跟踪方案和我们的车道线模型的输出可以很好的结合在一起。这个过程也是一个痛苦的,我们连续2个月,每周开一次专项会,毕竟我们已经基于拟合的方案做的不错了,但是为了更高的上限,只能痛并快乐着。最终目前我们已经把基础的功能进行路测了。
稍微给大家解释一下图4,左边是车道线点跟踪的效果目前我们模型的感知范围只有前80米,大家可以看到车后也有一些点,这是跟踪留下的。右边是我们的建立的实时感知图,当然现在还在一个快速迭代的过程,还有很多问题正在解决中。
时刻,站在24年回看我们从21年到现在的一路成长和积累,很庆幸在21年那个点,有机会去做BEV, 也很庆幸有一群志同相合的小伙伴一路相辅相成。24年,对我们来说,有很多东西需要去追寻,前融合模型的量产上线,数据方向的发力,时序模型的探索,端到端的畅想等等。
#基于神经辐射场的(NeRF-based) SLAM
随着2020年NeRF[1]的横空出世,神经辐射场方法(Neural Radiance Fields)如雨后春笋般铺天盖地卷来。NeRF最初用来进行图像渲染,即给定相机视角,渲染出该视角下的图像。NeRF是建立在已有相机位姿的情况下,但在大多数的机器人应用中,相机的位姿是未知的。所以随后,越来越多的工作应用NeRF的技术同时估计相机位姿和对环境建模,即NeRF-based SLAM (Simultaneously localization and mapping)。
将深度学习与传统几何融合是SLAM发展的趋势。过去我们看到SLAM中一些单点的模块,被神经网络所替代,比如特征提取(super point), 特征匹配(super glue),回环(NetVlad)和深度估计(mono-depth)等。相比较单点的替代,NeRF-based方法是一套全新的框架,可以端到端的替代传统SLAM,无论是在设计方法还是实现架构上。
相较于传统SLAM,NeRF-based 的方法,优点在于:
- 没有特征提取,直接操作原始像素值。误差回归到了像素本身,信息传递更加直接,优化过程所见即所得。
- 无论是隐式还是显式的map表达都可以进行微分,即可以对map进行full-dense优化 (传统SLAM基本无法优化dense map,通常只能优化有限数量的特征点或者对map进行覆盖更新)
由此可见,NeRF-based的方法上限极高,可以对map进行非常细致的优化。但这类方法缺点也很明显:
- 计算开销较大,优化时间长,难以实时。
但无法实时也只是暂时性的问题,后续会有大量的工作,来解决NeRF-based SLAM实时性的问题。
SLAM学术界的泰斗,Frank Dallaert(https://dellaert.github.io/),gtsam的作者,也开始转行研究NeRF,可见NeRF的价值和对视觉SLAM的意义。Frank大佬写了一系列NeRF相关文章的综述。
https://dellaert.github.io/NeRF/
https://dellaert.github.io/NeRF21/
https://dellaert.github.io/NeRF22/
由于NeRF方向博大精深,文章众多,我重点挑选SLAM方向,结合自己粗浅的理解,总结一下NeRF-based SLAM工作。该领域发展较快,文章持续更新中... (有遗漏的经典工作请在评论区提醒补充)
首先是一张框架图,梳理了这几篇工作各自的创新点和之间的关联关系,帮助大家有个宏观上的概念。[2][3][4][5]是和SLAM有关的工作,[6][8]和[7][9]分别是渲染加速和训练加速的工作,与SLAM无直接关系,但其加速的部分可能被SLAM用到。
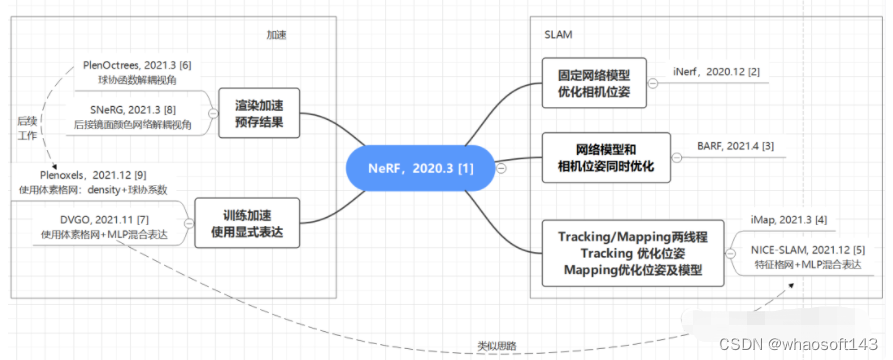
几篇Nerf-based SLAM工作的时间线:
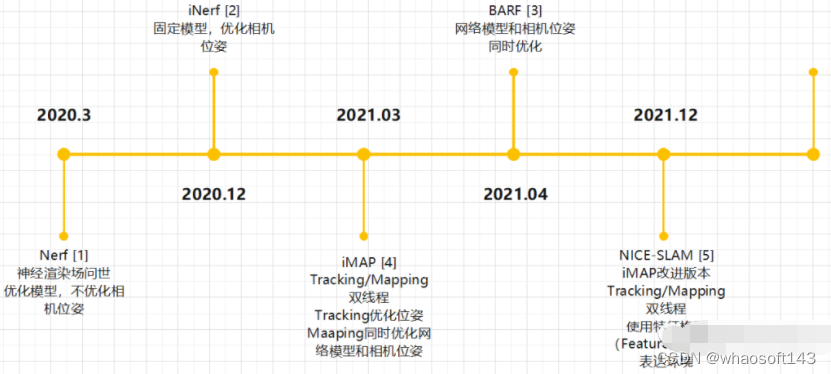
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. 2020.03 [1]
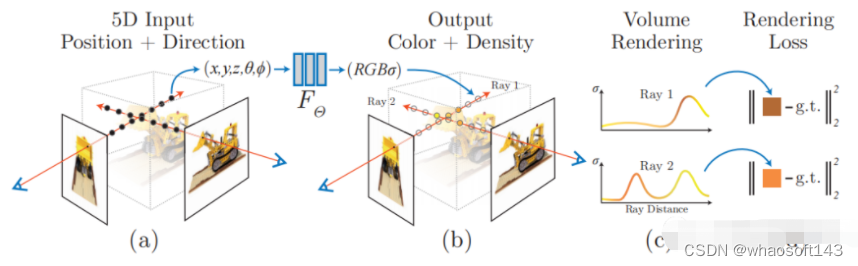
首先还是回顾一下经典的NeRF。NeRF选取一系列图片,这些图片的位姿已知。对像素射线上的点进行采样,每条射线采样几十个点(x,y,z,theta,phi),送入MLP网络(F_theta)。网络预测出该采样点的RGB和density(sigma)。再对射线上的点做辐射积分,得到该像素点的RGB值,和真值计算loss,梯度反传训练网络(F_theta)。该方法的优化的变量是MLP网络参数(F_theta),即场景表达隐含在网络当中。对相机的位姿不进行优化调整。
- iNeRF: Inverting Neural Radiance Fields for Pose Estimation. 2020.12 [2]
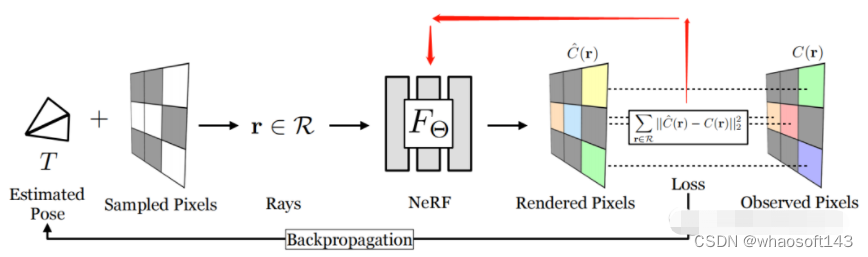
iNeRF是第一个提出用NeRF model来做位姿估计的工作。iNeRF依赖一个已经提前建好的NeRF模型,F_theta。所以iNeRF并不算SLAM,而是一个已有模型下的重定位问题。和NeRF的区别在与,NeRF固定位姿,优化模型,loss反传到F_theta(如图红线所示);iNeRF固定模型,优化位姿,loss反传到pose 。
- BARF : Bundle-Adjusting Neural Radiance Fields. 2021.04 [3]
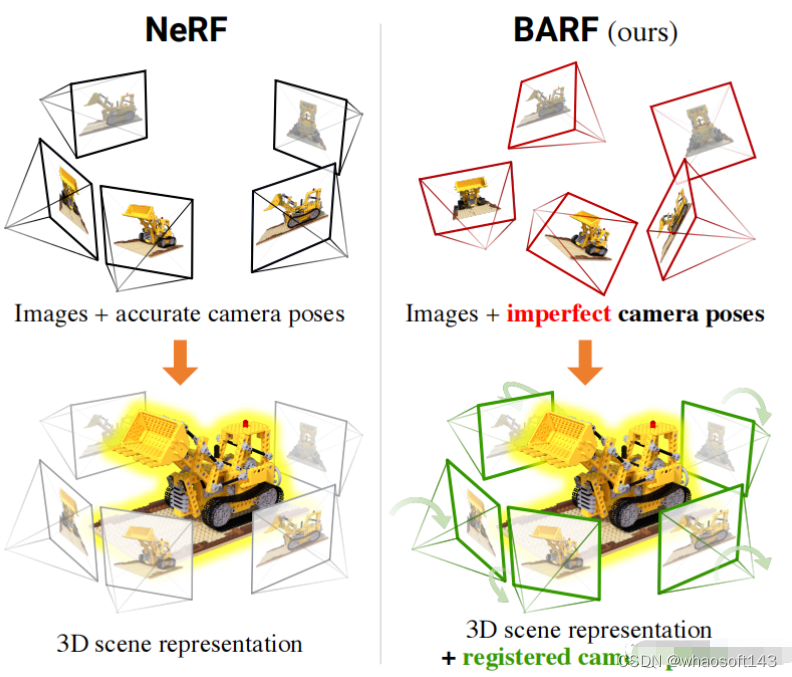
BARF这边篇文章同时优化网络模型和相机位姿,用神经渲染网络的方法实现了Bundle Adjustment。确切的说,该方法解决的是SfM (structure from motion)问题。该方法依赖一个粗糙的相机初始位姿,这个位姿可以通过col map等方法获得。通过网络迭代对模型和相机位姿进行精修。如果引入时序和帧间tracking,这将是一个不错的slam工作。
- iMAP: Implicit Mapping and Positioning in Real-Time, 2021.03 [4]
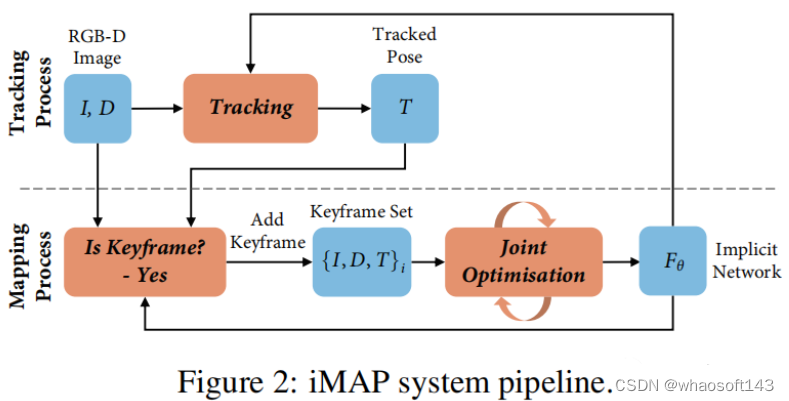
iMAP是真正意义上第一个NeRF-based SLAM 工作。iMAP使用的RGB-D图片,分为Tracking和Mapping两个线程。Tracking线程使用当前的模型,F_theta, 优化当前的相机位姿;判断该帧是不是关键帧,如果是关键帧,则关键帧的位姿和模型F_theta一同优化。iMAP的框架和传统SLAM类似,但核心的tracking和联合优化都有神经网络优化来完成。遗憾的是iMAP并未开源,但好消息是后面的工作nice-slam把iMAP的实现一同开源出来了。
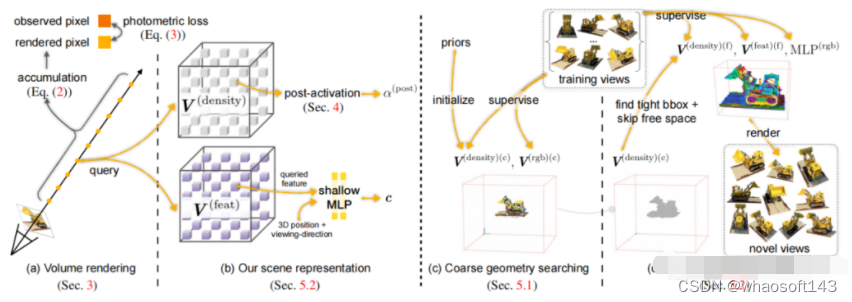
- NICE-SLAM: Neural Implicit Scalable Encoding for SLAM. 2021.12 [5]
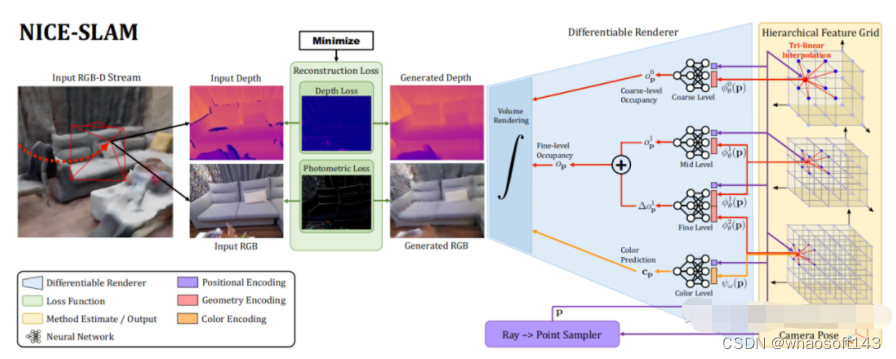
NICE-SLAM在iMAP的基础上做改动,作者不仅开源了自己这部分,也把iMAP的实现开源了出来。作者的主要改动是使用了特征格网(Feature Grid)+MLP这种显式+隐式混合的方法来表达环境。环境信息放在体素特征格网内,MLP作为decorder,将特征格网内蕴含的信息解码成occupancy和rgb。同时,作者还用了course-to-fine的思想,将特征格网分成粗、中和精细,以便更细致的表达。该方法比iMAP快了2-3倍,虽然具备了一定的实时性,但真正用起来还是离实时有一些距离。这是当前看到的最好、最完善的NeRF-based SLAM工作。
--------------------------渲染加速----------------------------
- PlenOctrees for Real-time Rendering of Neural Radiance Fields, 2021.03 [6]
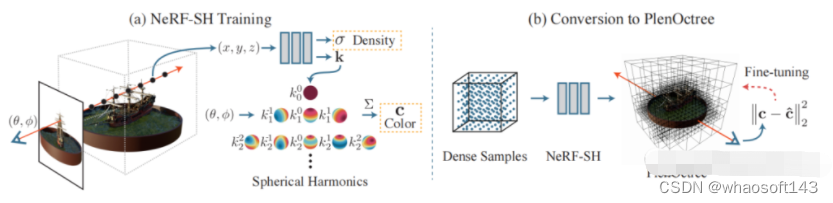
PlenOctrees是一种对渲染加速的方法。加速的方法是训练好mlp这种隐式表达之后,将空间中所有点以及所有视角观察都放到网络中推理,保存记录下来。这样下次使用时,就不必在线使用网络推理,查找表即可,加快渲染速度。但由于网络输入有x,y,z,theta,phi五个自由度,穷举起来数量爆炸。所以作者改造网络,将视角theta,phi从网络输入中解耦出来。网络只输入x,y,z,输出density和球协系数。颜色通过视角乘以球协函数得到。这样网络变量的自由度从5下降到3,可以进行穷举保存。
- SNeRG:Baking Neural Radiance Fields for Real-Time View Synthesis, 2021.03 [8]
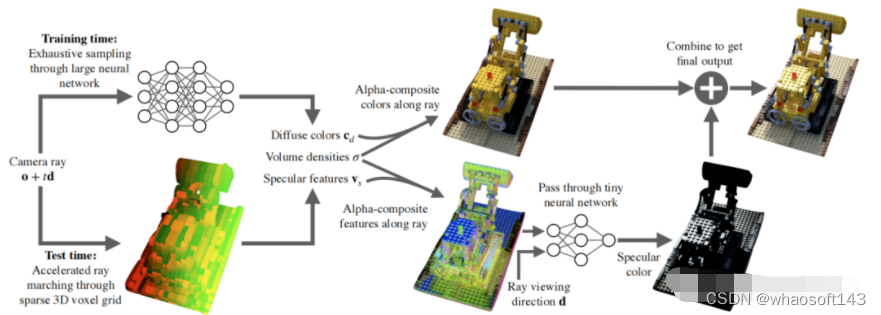
SNeRG和PlenOctrees类似,都是一种加速渲染的方法。Mlp训练好后,把与视角独立的信息存入3D体素格网内。在这篇文章中,作者把颜色分成固有颜色和镜面颜色,固有颜色与观察视角无关。网络输入3d坐标位置,输出体素密度,固有颜色,和镜面颜色特征向量。镜面颜色特征向量在通过一个小的网络,结合视角,解码成镜面颜色,加到最终的颜色上。与PlenOctrees一样,主干mlp网络都与视角解耦。PlenOctrees通过球协函数恢复视角颜色,SNeRG通过后接一个小网络恢复镜面颜色,在叠加到固有颜色上。
--------------------------训练加速----------------------------
- DVGO: Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction. 2021.11 [7]
DVGO提出了对网络训练进行加速的方法。作者发现,使用MLP这种隐式表达,训练速度慢但效果好;使用体素格网这种显式表达,速度快但效果差。所以DVGO提出了混合的体素格网的表示方法。对于占据密度(density),直接使用体素格网,插值就可以得到任何位置的占据密度;对于颜色,体素格网里面存储多维向量,多维向量先经过插值,后经过MLP解码成rgb值。这样网络在训练过程中,用到MLP的次数减少;MLP只翻译颜色,也可以做的很轻量化,所以训练速度大幅提升。
- Plenoxels: Radiance Fields without Neural Networks. 2021.12 [9]
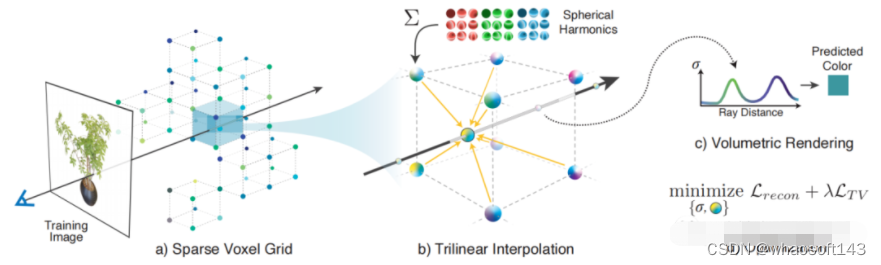
Plenoxels 是PlenOCtrees的后续工作。作者使用显式的格网来代替MLP。格网里面存储一维的density和球协系数。当有光线经过时,光线上的采样点的density和球协系数可由三线性插值得到。这样整个过程就摆脱了对神经网络的依赖,变成了完全显式的表达。由于去掉了神经网络MLP部分,训练速度大幅增加。作者强调神经辐射场的关键不是在于神经网络,而是在于可微分的渲染过程。
#大模型真能解决一切
今年是自动驾驶非常卷的一年。无论是工业界还是学术界,都不断有新技术新发现新思想「涌现」出来。一方面,关于自动驾驶的研究正逐渐趋同——无论是之前做感知、决策、规控的同事,都想拿大模型来试一试;但另一方面,任何新技术的出现都将意味着格局的重新洗牌,大家又回到了同一起跑线上开始。如果从趋势上来说,我认为2023年自动驾驶包括但不限于以下的一下演进:
首先,传统的感知正在向认知转变:如同深度学习时代的CV领域早期,以图像分类、目标检测、语义分割等任务为主。其本质是通过下游任务来(我最近很认同的一句话:评价方式引导发展方向。)来让整个系统具备「智能」的表现。然而,能够很好完成这些视觉任务的模型,真的是「智能」的模型吗?从行为主义上来说,大量工作确实能够很好地完成这些任务,甚至其性能可以达到甚至超过人类水平,体现出了智能的行为。但诸如一些对抗攻击在内的工作让我们发现:原来这些SOTA在对抗样本面前是如此的不堪一击,这里真正意义上的「人工智能」还很遥远。于是在2010年前后,CV界逐渐有一波热潮开始探索「认知」,包括一些更加神奇的任务、以及引入了文本等其他模态的数据,来完成Image Captioning,Grounding,VQA甚至是Scene Graph这种复杂结构支持下的复杂任务。还记得好像是16年左右,有些好事者分析过当时的顶会标题,如果带着「semantic」这个词,中稿几率大大提升。可见学术界对于「认知」、「语义」、「理解」、「知识」等等这些概念的追捧。而现在,我深刻感觉到自动驾驶也在经历这个类似的时刻。前两年自动驾驶感知方向,大家关注的还都是检测、分割之类的经典任务。而近期大家的关注点开始向更加「Fancy」的方向倾斜,例如大家开始注意到自动驾驶场景的描述(Captioning)、问答(VQA)等与「理解」密不可分的任务。
第二,大家期待的端到端自动驾驶,正在以一种知识驱动的方式到来:我个人认为,端到端自动驾驶还是可以再细分为两种。一种是如2023年CVPR Best Paper之一的UniAD一样,由多个模块的级联实现。其整体构型属于一种能够损失传导的Multi-Task Learning:通过将多个模块级联+每个模块的损失作为约束,使得各个模块在训练过程中朝着「整体最优」的方向进行,有更大的可能在整体优化过程中找到端到端的流形空间。另一类则是完全端到端,从训练端即实现data-in、policy(control)-out。这个过程和人类驾驶行为相似:以眼睛作为视觉输入信号,直接作用在方向盘和刹车油们踏板上。但这种端到端最大的挑战在于如何实现持续学习?这种直接端到端变相地扩大了模型的搜索空间,需要用更多的数据、更大的模型、更强的算力才能防止系统过拟合在特定的场景中。
第三,大模型的出现为自动驾驶打开了更多的研究机会。尤其是大模型在海量开放领域数据训练所获得的通用感知能力具备很强的泛化性,甚至具有解决自动驾驶场景各种Corner Case的能力。现在逐渐有一种声音(以工业界为主),就是很多人认为大模型将会是实现端到端的一种可能。但我感觉不能简单地将大模型与端到端划等号,甚至大模型到底能否被用来进行自动驾驶,也是一个需要考虑的问题。但大模型真的能解决一切问题吗?有朝一日我们能否见到由大模型控制的自动驾驶系统?我其实是比较悲观的,因为大模型存在太多太多问题了。与其期待教会大模型直接开车,还不如多关注一下大模型在AI Agent和具身智能方面的进展。
我和我的团队目前所研究的方向我们管他叫「知识驱动自动驾驶」,这也是这篇文章主要的话题:重新思考自动驾驶——从知识驱动到数据驱动。
首先介绍一下背景,现在的自动驾驶系统仍然存在诸多挑战。

比如长尾难例问题一直困扰着高阶自动驾驶在开放场景的应用。
例如,如左图所示,当我们从零构建一个自动驾驶系统的感知模块。冷启动的算法期初无法分辨工程车辆。但识别到桩桶,可能会让自动驾驶系统误以为在修路。最终,错误的感知做出错误的决策。
为了解决长尾难例,我们可以增加数据采集的覆盖性。例如通过采集更多的工程车辆并标注成车来提高车辆样本的数量。随着数据的增加,我们可能确实能够handle这种装满交通锥的工程车辆的识别问题。但如果样本是右边这张图呢?总会有无穷无尽的corner case的出现,甚至很多corner case在直到发生之前,我们都难以想象的。
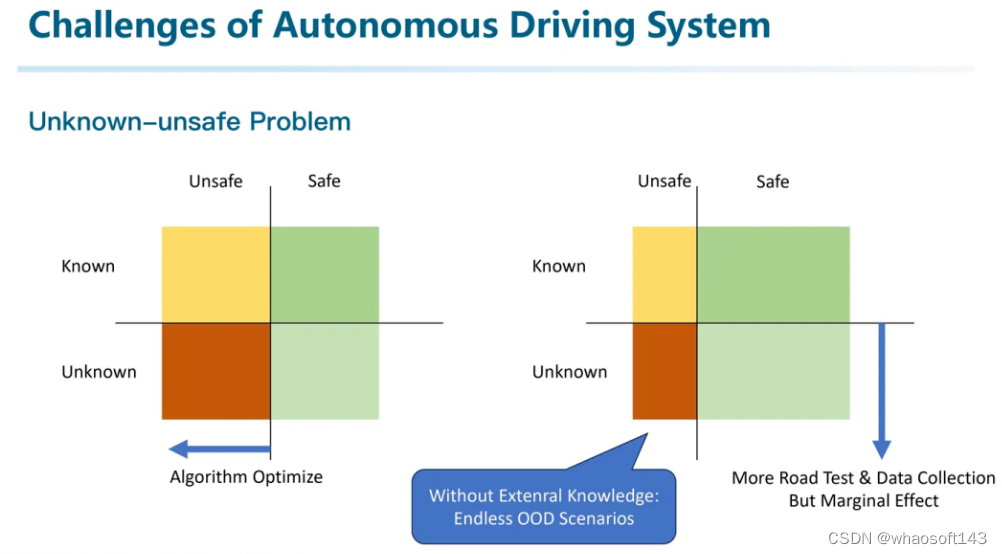
这张图来源于ISO 21448 SOTIF关于自动驾驶预期功能安全的标准。横轴分为安全、不安全;纵轴分为已知、未知。
对于Safe-known的绿色区域,是算法能够解决的问题。而Unsafe是指我们算法仍然无法解决的问题。我们希望调整算法,通过更好的学习,来让很多Unsafe的场景变得Safe。另一方面,为了压缩Unknown的区域,我们可以通过进行更多的路测来提高数据覆盖度。但「提高覆盖度」这件事是有边际效应的,在没有外部知识参与的情况下,我们总会有无穷无尽的Out-of-distribution的场景,也就是一些偶发的Corner Case,导致整个系统的失效。
而自动驾驶不同于其他很多领域,是存在木桶效应的。所以如何解决这些甚至在设计算法时都未曾考虑到的场景将会是至关重要的。例如如果一个目标检测系统从设计上只考虑了人、车、非机动车。那他可能就无法区分地上的桩桶和塑料袋。所以后来出现的一些针对开放词表目标检测的研究,或者像Tesla针对Occupancy的研究,都试图想从感知问题的定义上,让他有足够大的解空间,才能覆盖尽可能多的解。
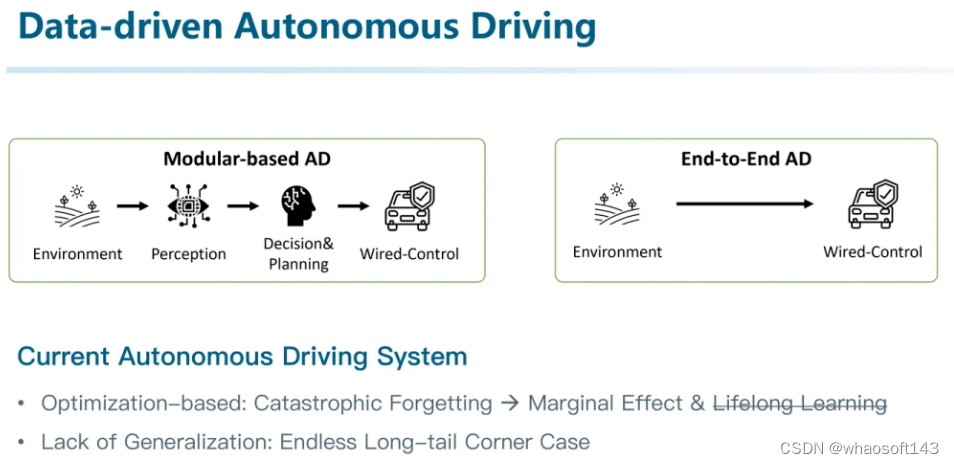
我们可以说,现在绝大多数自动驾驶系统,都是基于这样数据驱动的模式构建的。与此也伴生出了像数据闭环等重量级的中间件:就是通过反复的路测、数据采集、数据标注、模型训练,再进行路测,重新采集数据训练模型,循环往复不断进行。通过将这些流程制度化来降低成本。但从本质上仍然未解决问题。
为什么?因为除了无穷无尽的corner case以外,还有很关键的一个因素:现有的很多系统都是基于优化的方法。而优化就存在一个问题,遗忘灾难。所有优化的本质就是当我们找不到一个全局最优解的情况下,只能妥协地达成一个局部最优解。这就意味着那些经常出现的common case才会主导因素,而偶尔发生的corner case甚至要被当做是异常的离群点忽略掉,从而才能使整个系统处于一个低熵的稳定状态。反过头来,如果太关注corner case,当模型capacity不够大的时候,有可能反而让common case变得更差。按下葫芦起了瓢的效果。而这与自动驾驶系统追求安全的事实是相反的。
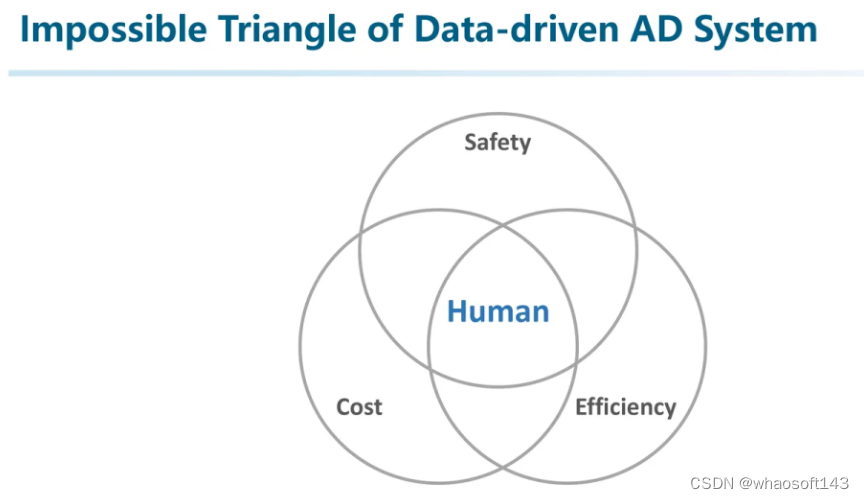
所以我们能够总结出数据驱动自动驾驶系统的不可能三角:想要一个又安全又便宜的自动驾驶系统,那一定效率不高(例如扫地机器人?);想要便宜高效,那一定很不安全(横冲直撞那效率可杠杠的);又安全又高效那一定非常贵。
尽管数据驱动不可以三者兼得,但人类却能在这三者之间找到平衡。
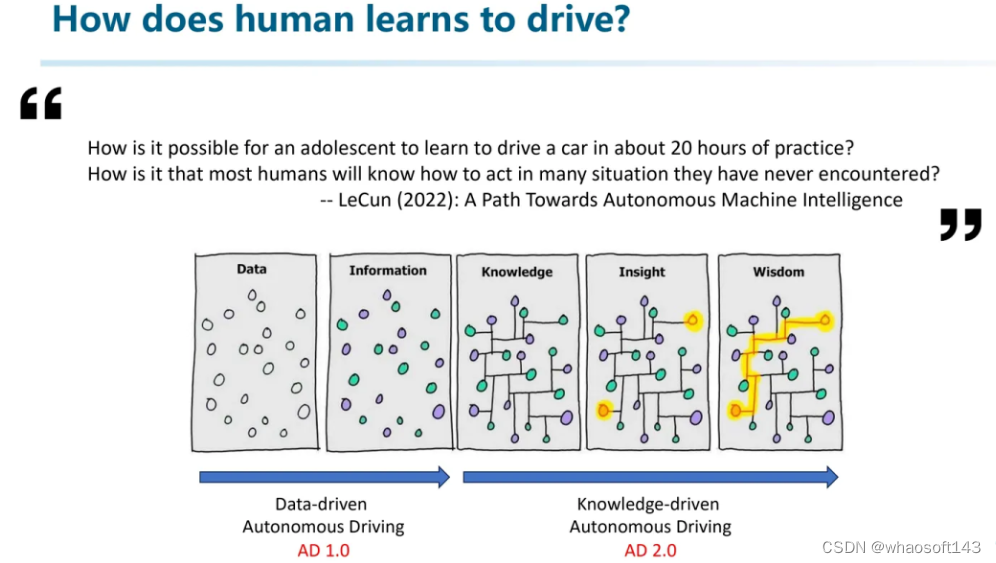
所以我们需要分析为什么人类这么厉害?
2022年LeCun在他的一项关于通用人工智能的工作中开篇即提了这样两个问题:1. 为什么一个人类青少年能够在大约20分钟的练习里就可以学会基本的车辆驾驶技能?2. 而为什么人类能够在遇到一些之前从来没见过的场景时仍然能做出正确的反应和决策?
其实这里面的关键因素就在于知识和推理的运用。例如上图里那5张图很多人都见过:数据通过打标签成为信息,而后融会贯通从知识逐渐变成智慧。
如果将自动驾驶系统与之相对应,我大概认为。之前的数据驱动自动驾驶仅仅能运用数据和信息,难以挖掘信息之间的关联性。因为关联性才决定了是否具备举一反三的能力。所以我们觉得,现在正是一个好的时机,从知识驱动自动驾驶的视角出发,探索AD2.0。(当然,AD2.0这个概念不是我们提的,是Wayve等一些公司题的)。
总的来说,现阶段我认为,自动驾驶的第一性原理是知识。
如何直接和间接地利用好人类的知识,跨域的知识,通用的知识,来处理好各种各样的问题,来让自动驾驶系统有更高的泛化性、Robust,是我们团队一直以来的研究方向,也是这篇文章的主题。
那接下来就介绍一下我认为什么是知识驱动的自动驾驶。
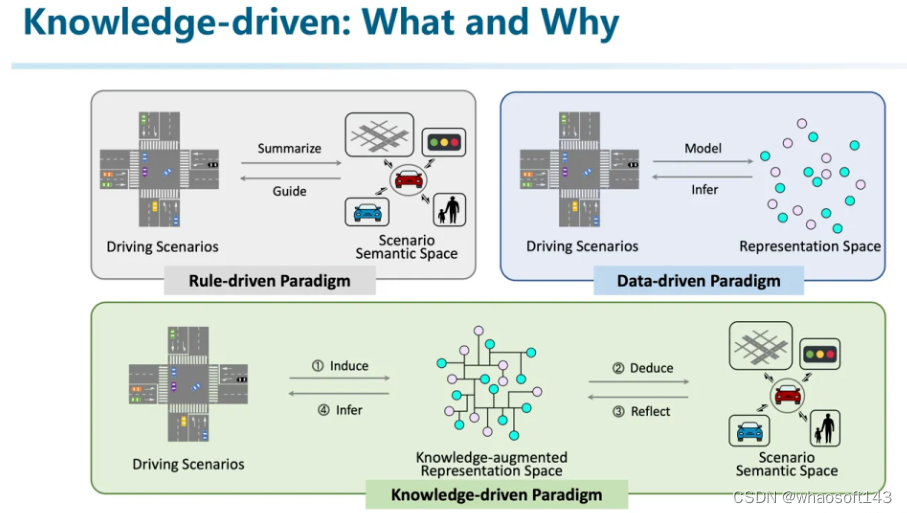
规则驱动的方法是由人类通过观察真实场景,融入自己的思考之后将其抽象成一些可解释可执行的规则。这种方法能够很好地反应驾驶场景的本质。但由于规则编写本身是一件复杂,互相牵制的事情。完全由人工来进行则难以规模化。
而数据驱动的方法则是试图建立从输入到输出的映射关系。在这个过程中,通过将驾驶场景转换到压缩的表征空间来尽可能提取。因为有一个说法是压缩即智能。但这个空间很有可能因为下游任务的限制,overfit到了任务空间而不是真正的理解了交通场景。Data-driven更像是一种行为主义(behaviorism),只是体现了智能行为,但并不是真的理解了场景,所以性能存在边界。
而知识驱动的自动驾驶首先需要具备场景理解的能力,归纳出通用的一般性规律,再进而推演到真实的理解空间中。但由于「知识」这个概念就像「智能」一样很难定义,所以我们只能从行为主义的角度来观察如何才能实现知识驱动自动驾驶。

我们认为,知识驱动自动驾驶的三个关键特征是:泛化性、可解释性和终身学习的能力。
想要实现知识驱动自动驾驶并落地,可能需要满足这三个特征。
首先来说说泛化性

如前面所述,由于数据驱动的方法在面对out-of-domain问题时难以解决。例如我们很难在任务设计时就考虑路上有飞机迫降这种极端的cornercase。

而知识驱动的方法通过大量在Open Domain数据上预训练所获得的通用知识,使得我们有可能对out-of-distribution的数据进行理解。
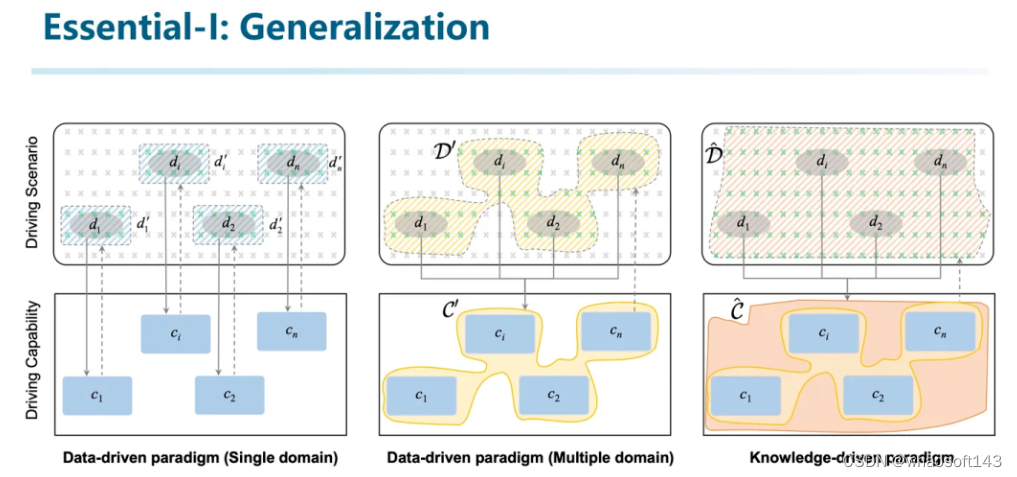
泛化性是解决Unknown的关键,能把工程师从处理Corner Case的重复性劳动中解放的希望。我们用这张图来解释一下。上面一排指场景空间,下面一排是驾驶能力的空间。
对于Single Domain的数据驱动方法来说,我们从场景空间中采集数据并训练模型,学会其到驾驶能力空间的映射,同时对该domain产生一些泛化性的外溢,举个不严谨的例子:只用高速公路数据训练的模型,在高架上可能同样适用。但对于domain外的泛化性还是较弱。例如只用高速数据训练的模型,在梧桐区(上海某个开车停车都很费劲的开放街道)就不能用了。
于是大家从数据采集的角度入手,增加数据覆盖率,并将各种数据混合到一起,形成了Multiple Domain的数据。然后得到的模型不但能够处理各自domain的能力,还具备了一些初步的泛化性。例如收集了晴天、雨天数据训练的模型,在阴天可能仍然能用。然而这种数据采集也只是解锁了一些不同的场景,对于非常偶然出现的corner case,仍然不能像人一样从场景理解的角度出发来给出正确的分析和解释。
而第三列表示的是知识驱动的方法。如果我们有一种方法能够挖掘到海量不同domain的数据内在的关联,具备一些初步的通用理解能力,那就有可能对偶尔出现的场景如同人类一样实现举一反三。实现最终的泛化能力。
所以说,泛化性不但是自动驾驶领域研究关注的重点,也会是知识驱动的一个特性和体现。
再来说说第二点,可解释性。为什么可解释性重要?
- 首先,它可以作为「理解」和「知识」的佐证:可解释是智能的充分不必要条件。可以联想到图灵测试。
- 第二,一个完全的黑盒只能通过数据驱动来训练,又走回了老路。所以完全端到端,我个人反而是不太相信的。
- 第三,对解释的反思能够更直接地修正模型:非梯度方法。例如当我们让模型自己反思哪里做错了,如果能解释出个所以然来,说明模型具备了很强的能力。
- 第四,我们认为可解释性是实现Life-long Learning的一种显式的方式和先决条件。
例如我们尝试利用大模型来描述一下之前的场景,我们发现一旦操作变得可解释,那这些决策就会变得可信且合理起来。(这个是比较早的尝试,当时用的LLaMA-Adapter实现图片描述,用GPT3.5试试做决策和判断)
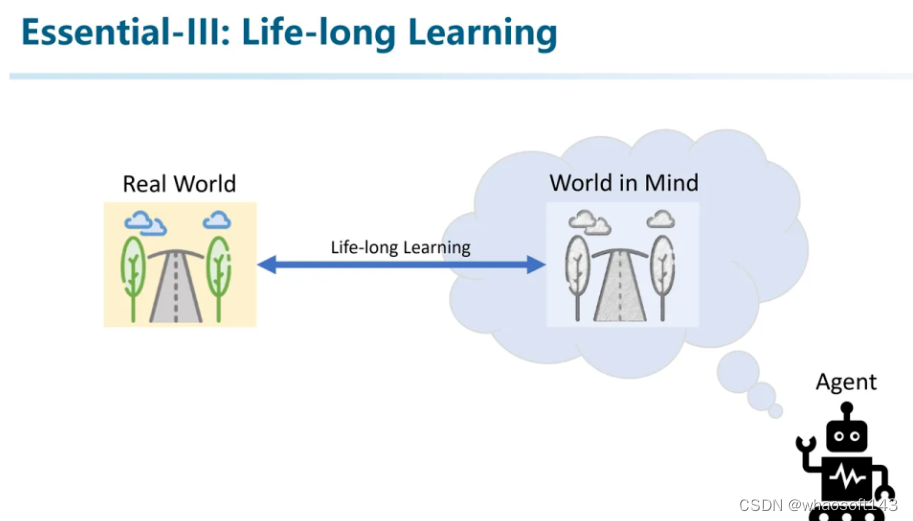
第三点,Life-long Learning。
为什么Life-long Learning非常重要?因为从机器人或者具身智能的角度出发,一个Agent的脑中其实蕴含了对真实环境的建模。而Life-long Learning的能力决定了这个脑中世界和真实世界的差异程度。
像是现在的数据驱动方法,由于人工框定的任务限制了它施展能力的范围,导致其只能用「管中窥豹」的方式来建模世界,最终只能成为一个井底之蛙,认为的世界就和别人让他看到的世界一样。
而参考人类的思维方式,经验只会随着年龄不断积累。新司机可以通过积累经验成为老司机。并且很多驾驶经验并不来源于驾驶本身,而是从很多其他领域持续学习得来经验。
而Life-long Learning也是将整个系统落地上车的决定性因素。在这里插一句,我感觉像之前特斯拉展示的End-to-end的一些方法看起来很fancy,但实操起来会有很多挑战。最大的挑战是,在缺乏对中间过程的supervise的情况下,如何对规模庞大的模型实现持续学习/终身学习?所以可能UniAD这种中间可以插入supervise的方法举例落地会更现实一些。(除非World Model真的实现,后面再细聊)
在介绍完知识驱动自动驾驶基本定义之后,再来聊一下最近出现的LLM是否对知识驱动自动驾驶能有所帮助。
其实一直以来我的一个思想是:知识驱动是第一性原理,但LLM不是。LLM只是在现阶段能够实现体现出知识运用能力的一种工具,它虽然具备基础的通用理解能力,但不见得所有事情都要靠LLM。让LLM开车并不是一个长久的方向。
首先来统一一下术语。
我们发现工业界引入「大模型」这个概念的时候发生了大量的术语混淆。难道「大号的模型」就是大模型吗?比如像SAM算大模型吗?BEV算法属于大模型吗?甚至一些人在到处讲,Transformer就是大模型。
但从学术上,LLM其实是有着明确的指向的。
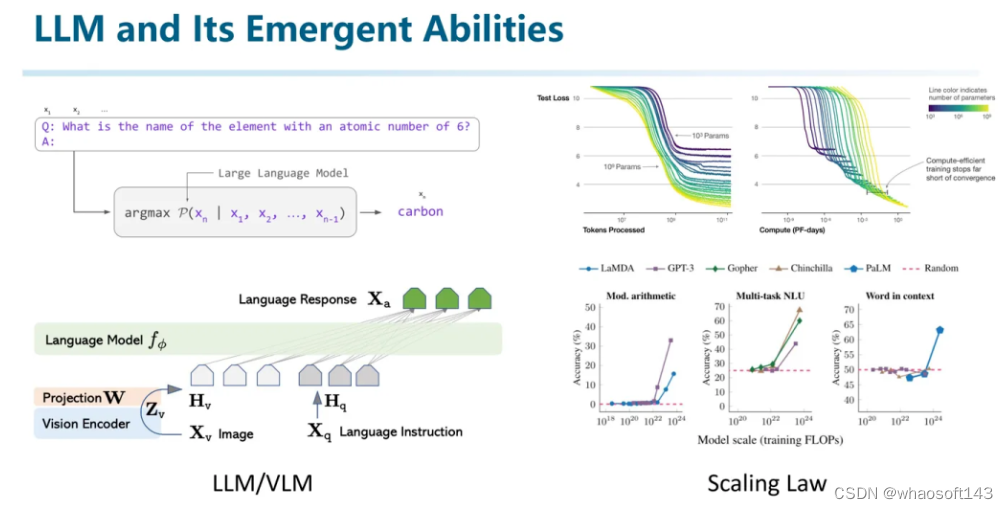
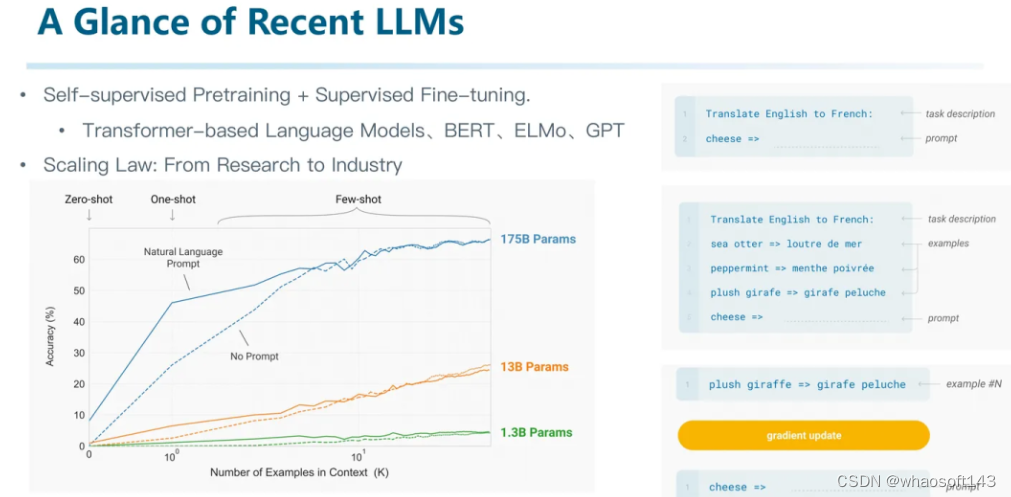
(下面这段关于LLM的整理不是很严谨,请批判性阅读)
并不是用了transformer或者数据量大就是LLM,应该是采用LLM或者VLM架构且在大规模数据上进行训练,并且跟随scaling law出现了涌现的现象,才是我们讨论的LLM。
想要解释清楚LLM发展的来龙去脉需要比较长的篇幅,也不是本文要讲的重点。所以这里就简要概述一下。
早期的大模型,是在Transformer之后出现的如BERT、ELMo、GPT等在内的语言模型。其本质就是一个语言模型,用来建模一句话的发生概率。其训练方式是输入第1到t-1个token,预测第t个token应该是什么。并且在那个时候利用海量纯文本数据,通过随机对一些词进行mask,或者对两句话交换顺序等各种各样的下游任务,迫使模型能够更好地理解一句话内包含的语义。那个时候是NLP的黄金时代,因为大模型通过海量的数据获得了基本的语言理解能力,使得很多任务都利用大模型实现了突破。
而后大模型也面临一个life-long learning的问题。之前很多大模型还是以研究为主,直到后来出现了一些工作,发现大模型是可以随着堆料性能不断增加的。这就刺激到了工业界。工业界就喜欢这种力大砖飞的模式,因为每一分钱的投入都有可以计算的预期收益。然后就掀起了现在大模型研究的热潮。随后又出现了In-Cotext Learning, Chain-of-Thought等等各种技术,甚至催生了提示词工程这个行业。
时至今日,大模型的范式基本是统一的,首先就一个参数量巨大的Foundation Model,再利用部分和任务相关的数据进行Instruct-tuning。像ChatGPT就是在GPT这个Foundation Model中用少量高质量的对话数据对齐的能够对话的模型。后面这个过程通常不被称为是训练而是对齐,我个人感觉可能是因为,Foundation Model已经具备了很强的能力,而少量的Instruction-tuning只是为了向大模型展示任务需要,让大模型的表现对齐到人类预期的行为之上。
解释一下大模型的一个有趣的现象,就是可以通过In-context-learning实现few-shot来完成一些任务。而我们也可以通过SFT来将这些能力内化到大模型内部。
近期出现了大量的LLM+AD的工作,这里快速介绍一下,不是本文的重点。
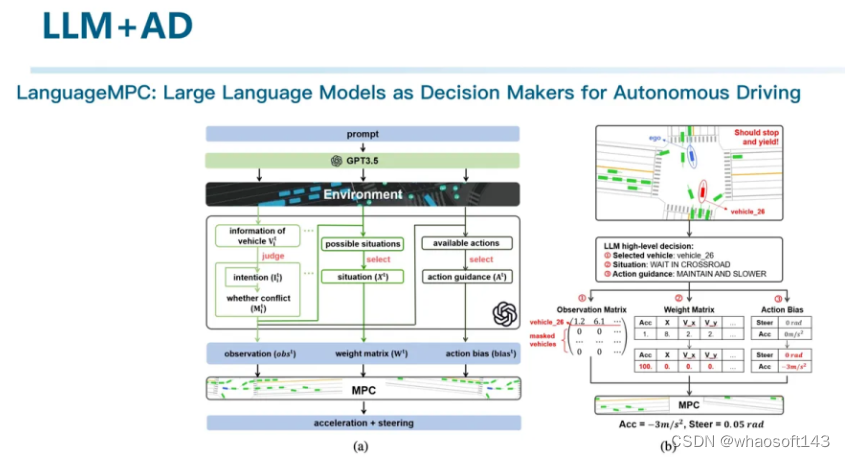
LanguageMPC利用LLM进行了细粒度的决策,通过将场景结构化成文本送入大模型,来和环境进行交互。通过接了一个具体的行为控制模块实现具体的驾驶行为的输出。其主要是利用了大模型对场景进行编码的能力。
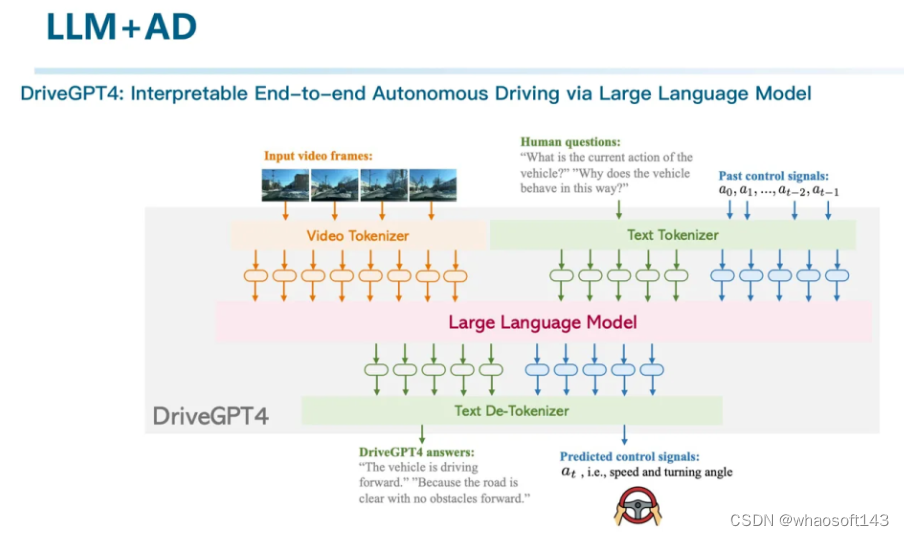
DriveGPT4则是试图引入一个带有视觉的VLM,实现对输入视频的理解,并且能够根据prompt完成一些QA任务。包括生成控制信号等等。
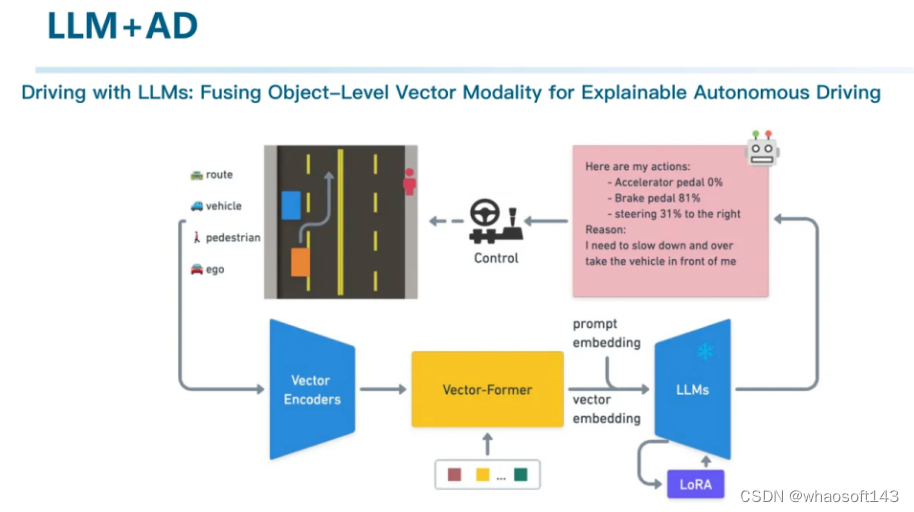
↑这篇工作则同样是利用大模型来处理控制的工作。通过将场景向量化表征,并且通过一些数据对大模型进行了SFT使其变成了能够输出控制信号的大模型。
和上面这些LLM+AD的工作区分开,下面这页Slides才是我想表达的重点:
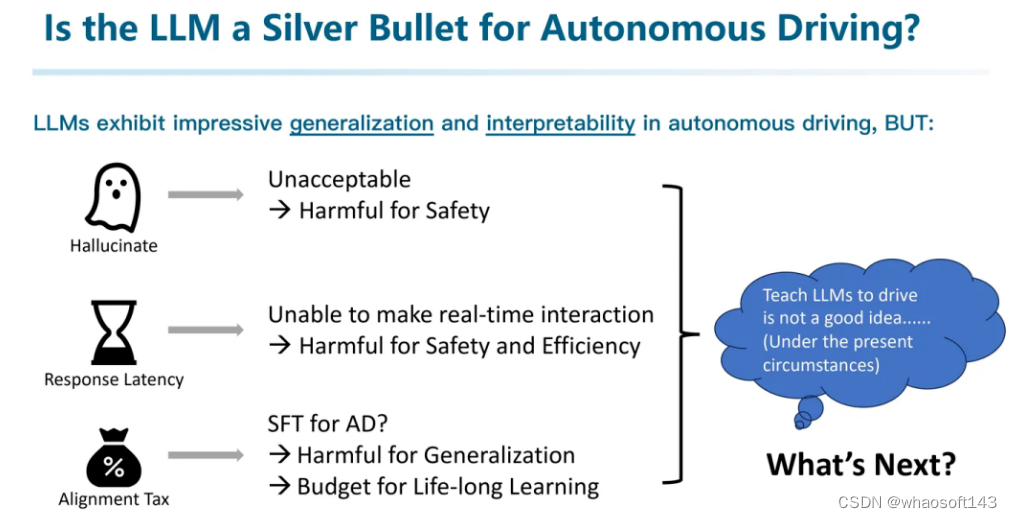
这些LLM+AD的工作真的能解决一切问题吗?我不认为。
我觉得大模型尽管能展现出generalization和interpretability。但仍然存在诸多问题:
- 幻觉:因为LLM的训练方式导致其必然会输出一些文本。直接影响安全性和正确性。
- 响应速率低下:影响实时性,最终导致安全和效率都会受损。
- 对齐税:朝着自动驾驶任务SFT,反而会丧失一部分通用性和泛化性。
- 并且SFT成本高,难以通过SFT的方式实现Life-long Learning。
其实一直以来我的一个思考是:知识驱动是第一性原理,但LLM不是。LLM只是在现阶段能够实现体现出知识运用能力的一种工具,它虽然具备基础的通用理解能力,但不见得所有事情都要靠LLM。让LLM开车并不是一个好主意。所以我们需要的是借助LLM的能力,而不是all in在LLM上,让LLM成为一个万能的工具。
受到最近一些Multi-agent和Embodied AI研究的启发,我们认为,LLM可以作为一个CPU,利用好它的generalization和interpretability,配合memory实现life-long learning,结合外部的专家系统、Retrieval Augmented Generation技术来解决幻觉问题,共同构建成一个Driver Agent。
所以接下来介绍一个我心目中的知识驱动自动驾驶的架构
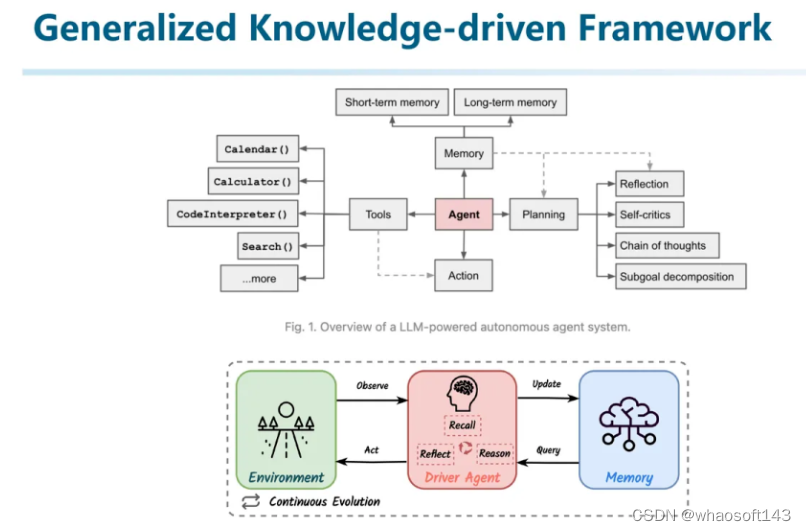
让我们先跳出LLM的制约,从认知的角度先来讨论一个通用的知识驱动的框架。它更像是一种Embodied AI的架构在AD的应用。
上图展示了一种利用Agent来操作工具、进行规划,并结合Memory机制最终产生Action的架构。这个架构和人类认识世界和做决策的框架是类似的。
更进一步,我们认为其实知识驱动的自动驾驶也可以利用这样的框架进行(如上图下部分)。其核心是Driver Agent,通过对环境进行Observe,并从Memory中Query一些过往的经验,最终综合做出决策,并利用决策的执行情况作为修正信号来修正Memory。
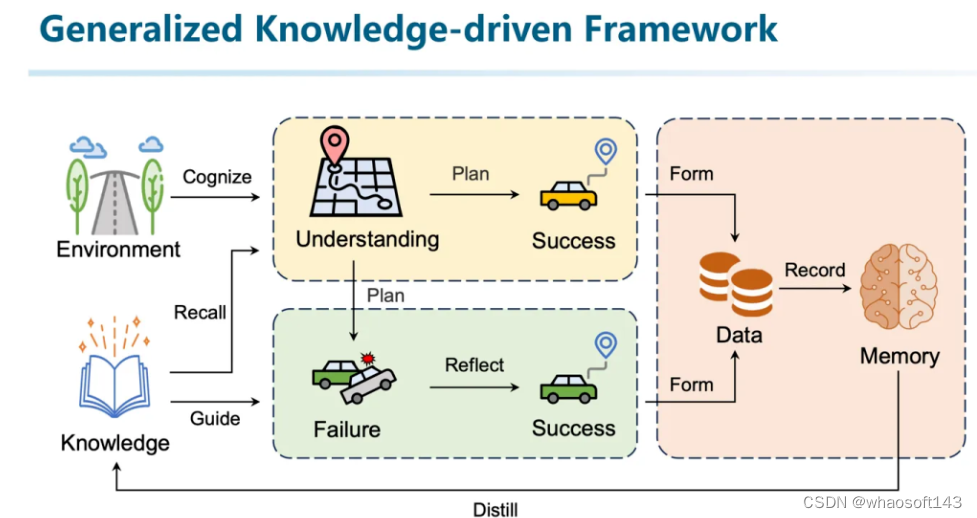
我们再进一步将其对应到自动驾驶场景中。首先我们利用场景理解系统来进行场景表征。并且基于这些表征进行决策。在决策过程中将会有过去的经验参与。如果决策是正确的,则会将其作为经验的一部分积累到记忆模块中。如果决策发生了错误,则也会要求系统能够反思错误,并将纠正好的正确经验重新加回到记忆系统中。整个系统不断迭代。最终记忆就成为了知识的一种表现。
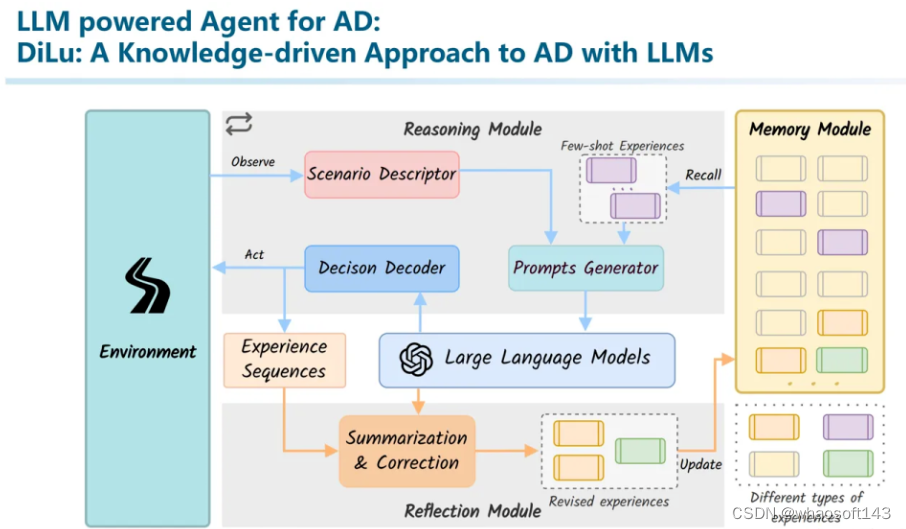
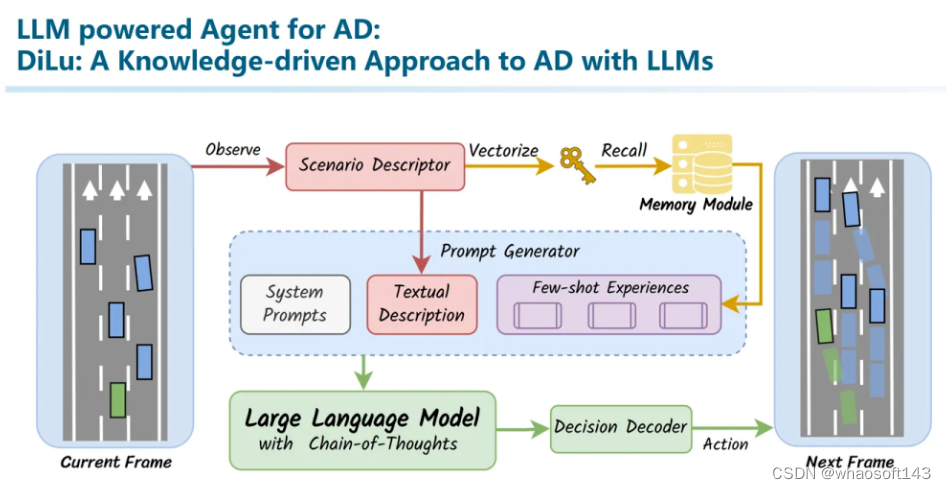
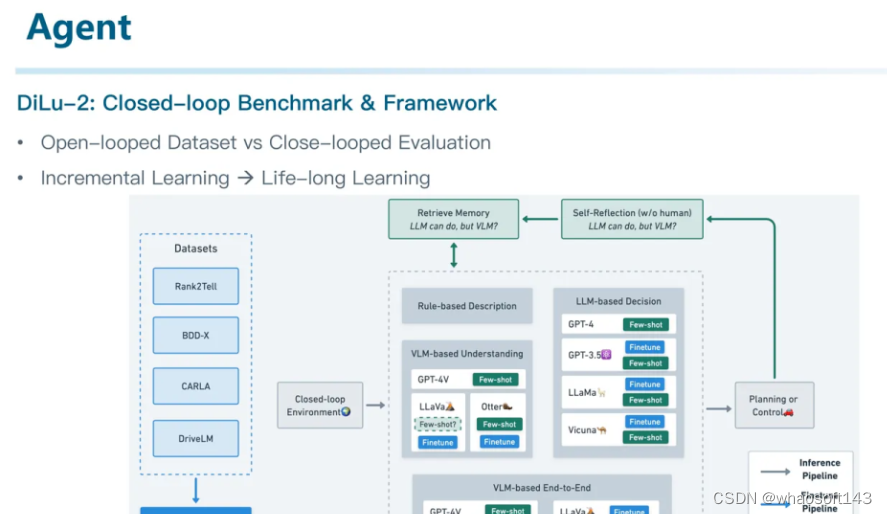
在整个系统中,我们可以让LLM参与到部分工作,但是并不是仅仅依赖LLM,于是我们构建了这样的系统。这篇叫做DiLu: A Knowledge-driven Approach to Autonomous Driving with Large Language Models。(To the best of our knowledge, 这篇应该算是非常早期探索LLM+Agent+AD的工作了,还有我们另一篇工作Drive Like A Human可能是第一篇探索大模型是否能和自动驾驶相结合的工作。)
整个系统包括了Reasoning、Reflection、Memory三个模块。首先在Memory模块中保存了一些驾驶经验行为。本质上是一个向量数据库。其中Key是场景的语义向量化表征(相似场景vector相似,不同场景vector不相似)。而Value则保存了这个场景曾经做出的决策,以自然语言文本来描述的。
在推理模块中,我们首先对环境进行编码,利用这个编码从记忆模块中query相似场景。并将这个信息作为prompt,和当前场景一起输入到大模型中。也就是说,此时大模型既输入了当前场景的描述,又输入了记忆中相似场景和当时所作出的决策作为共同信息,并且最终给出一个决策意见。我们将这个决策转换成Environment的控制信号,控制一个在虚拟环境中的车辆进行驾驶。
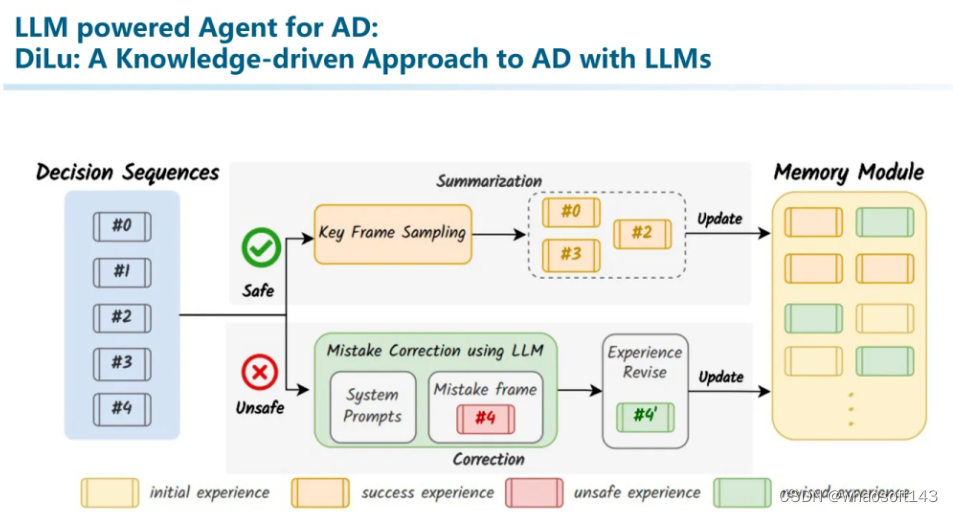
在驾驶过程中,我们可以知道这个决策是否正确。如果决策正确,我们会将这里的场景表征向量作为key,决策说明作为value来更新记忆模块中的经验。另一方面,如果决策出错,例如发生了碰撞或者其他危险行为,我们会借助大模型进行自我反思,并将整个反思过程一起加入到记忆模块中。
从这里就能看出之前我们提到的三个特性:generalization、interpretability、life-long learning的重要性。首先,泛化能力保证了对各种out-of-domain的场景的通用理解能力。而我们利用可解释的信息作为记忆系统,一方面能够追溯所有做出的决策,另一方面也能够用人类能够理解的方式来完成反思等复杂的内容。另外,也正是因为经验是以自然语言定义的可解释的文本,而这些文本常常是放之四海皆准的信息,不随domain变化而产生太大的漂移的。而整个经验库是在不断积累的,从而实现一个Life-long Learning。
还有就是这篇文章的Reasoning模块和Reflection模块,具体细节我就不介绍了,可以看看论文。
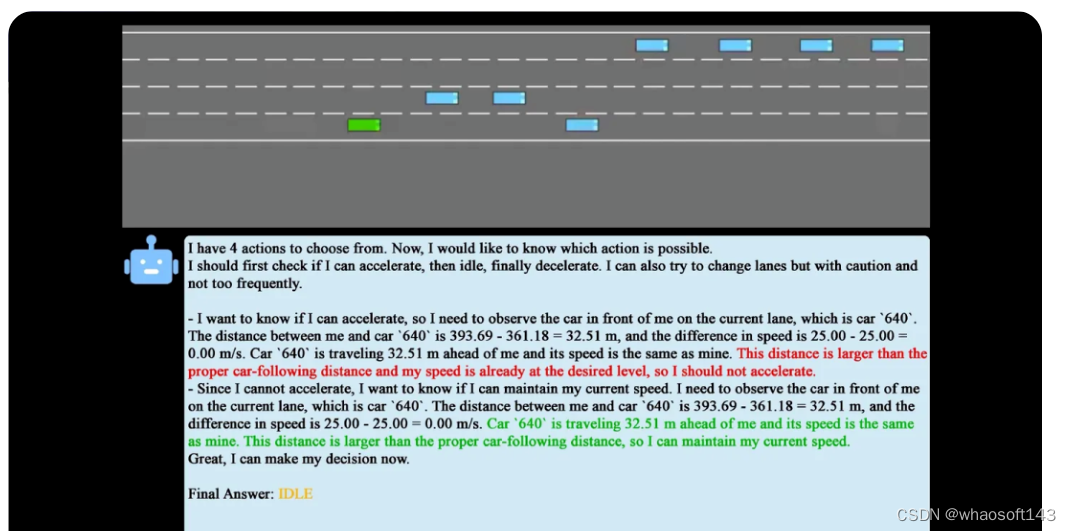
这里有一个缩时演示的视频。我们采用了Highway Env作为仿真环境,每一步都是由大模型参与进行决策并交给仿真器来执行的。
只是张图片动不了的,视频请点下面的链接
视频请点击链接:DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Mode_哔哩哔哩_bilibili
Slides后面有一些实验分析,这里我就不具体展开了不然文章篇幅太长了。(写到现在已经快1w字了)。一句话总结就是我们有这样几个发现:
- Memory机制真有用,这种类似于RAG(Retrieval Augmented Generation)的方法能够在不SFT模型的情况下,实现Continuous Learning的功能(但Life-long Learning还没试过,主要是Highway Env太toy了)。
- 真有泛化性:我们用Domain A的场景得到的Memory,直接在Domain B中用,发现
- 真有可解释性:Memory中的key是场景表征向量,value可就是纯文本啊。无论决策做对了还是做错了都是一目了然的,甚至可以reflect来修正记忆。
这里我们展示了反思模块的一些能力。例如这里进行了一个错误的决策。
此时我们让大模型分别针对碰撞原因、其中的经验教训进行解释,并产生一份revised decision。我们会将整个这些文本都作为经验保存到记忆模块中。

这篇工作作为一个非常初步的工作,其所选择的环境、能进行的决策空间等等非常有限,属于一个早期的toy性质的研究。所以也留下了很多Open Problems:
- 场景理解:Key该如何构建?
- 记忆该如何表征:显式地用自然文本?图像?还是隐式的representation?
- 是记答案?还是记「决策过程」?
- 进一步从人类思考的视角出发,如何与System I(快系统)和System II(慢系统)相结合?
另外再提一个我觉得很有意思的工作Agent-Driver([2311.10813] A Language Agent for Autonomous Driving (arxiv.org)),也是采用了Agent而非教大模型开车的模式。不过当时做Slides的时候忘记介绍了,后面有机会再补上。
除了DiLu以外,再介绍一些我们认为和Knowledge-driven相关的工作。其中部分工作也是我们团队正在进行的。
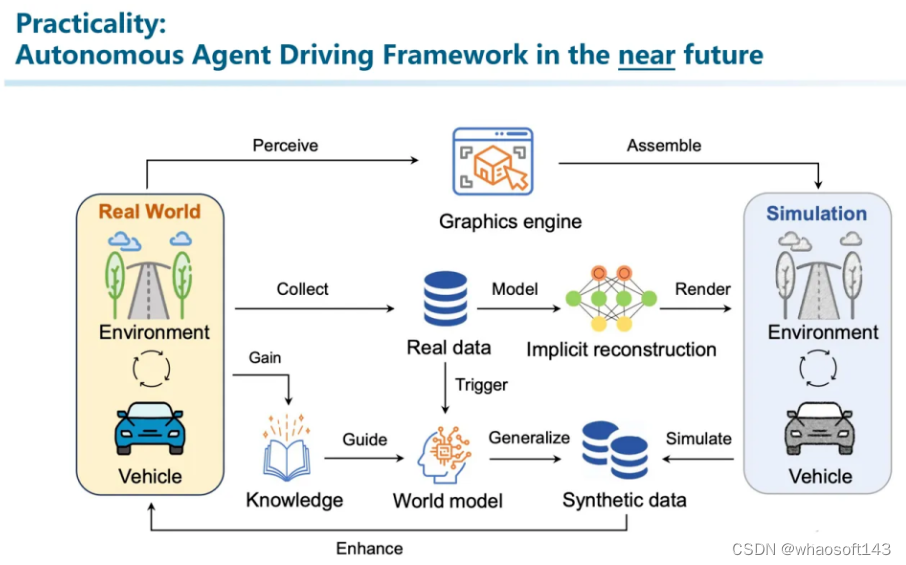
首先,畅想一下未来,我们认为未来的自动驾驶系统有可能发展成这个样子。这张图来自于我们最近的一篇Survey(说是Survey,但其实也包含了我们很多思考):Towards Knowledge-driven Autonomous Driving。
一方面从真实世界中提取信息积累常识知识。另一方面利用真实世界的数据,构建高质量的虚拟的仿真引擎。并通过在仿真引擎中积累交互知识。反复重复这个过程实现life-long learning。
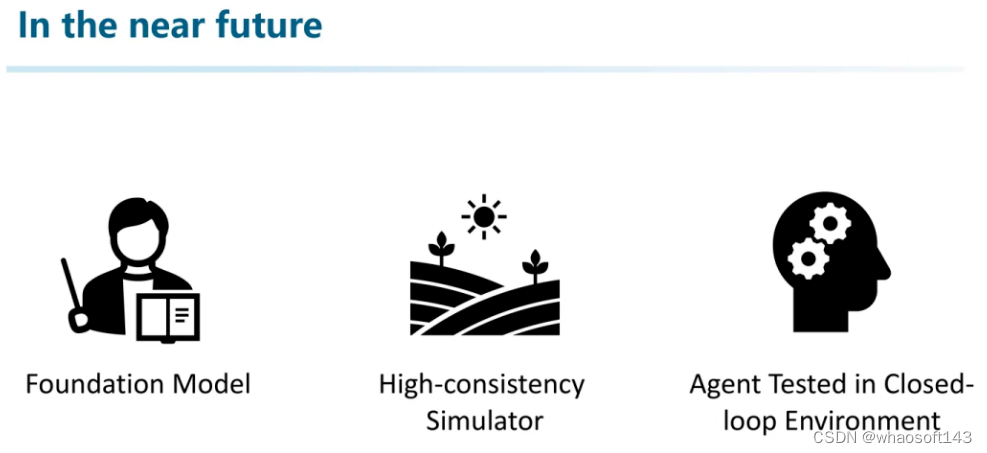
所以这就引发了三个探索的方向,我们认为是目前学术界比较火热的方向(换句话说:很卷的方向):自动驾驶的Foundation Model(完成场景理解、辅助决策)、知识驱动的Autonomous Driver Agent(Memory机制、RAG)、高一致性的仿真引擎。

首先是我们该如何利用Foundation Model?这可能依赖于通用大模型的理解能力,也需要一些利用大模型针对自动驾驶追至领域SFT的探索。
但我觉得大模型在这个环节的参与可能体现在场景理解和Decision Making上。因为这些功能充分体现了大模型处理out-of-distribution问题的能力,以及宏观决策能力。并且由于不是直接将方向盘交给大模型,所以能够从一定程度上缓解幻觉的问题。
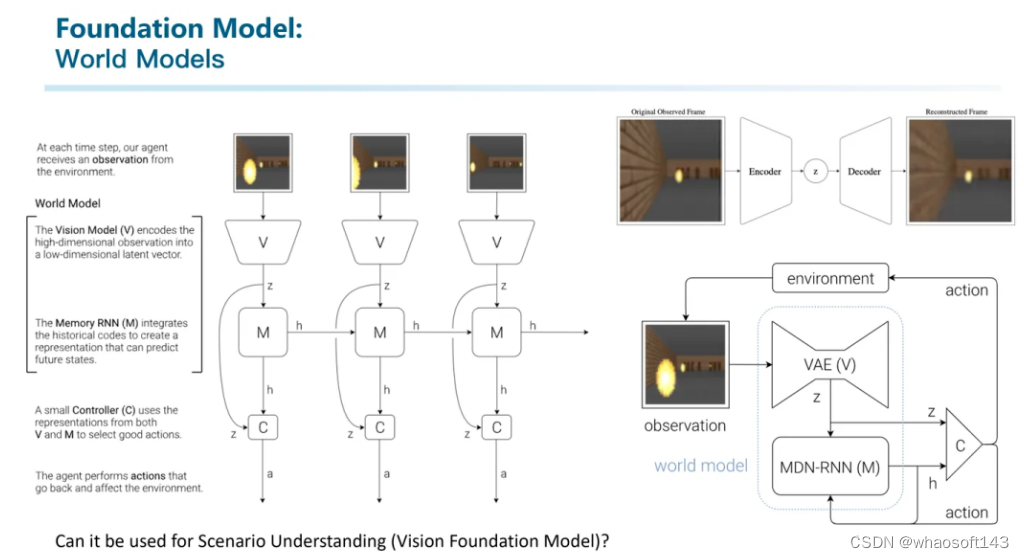
另一块我觉得非常有趣且有潜力的方向就是世界模型。
世界模型早在2018年甚至更早就被已提出,其架构的本质是利用下一帧预测来让模型理解整个世界。我觉得世界模型的一个应用点在于场景理解:因为能正确预测出下一帧的样子,说明中间的vector包含了对整个场景的编码表征。
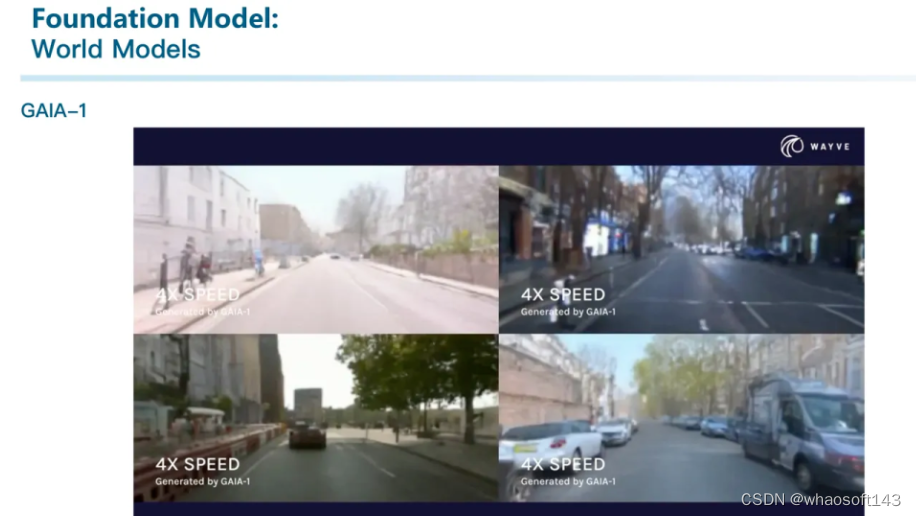
基于世界模型的思路,Wayve提出了GAIA-1,可能是第一个自动驾驶领域的世界模型。
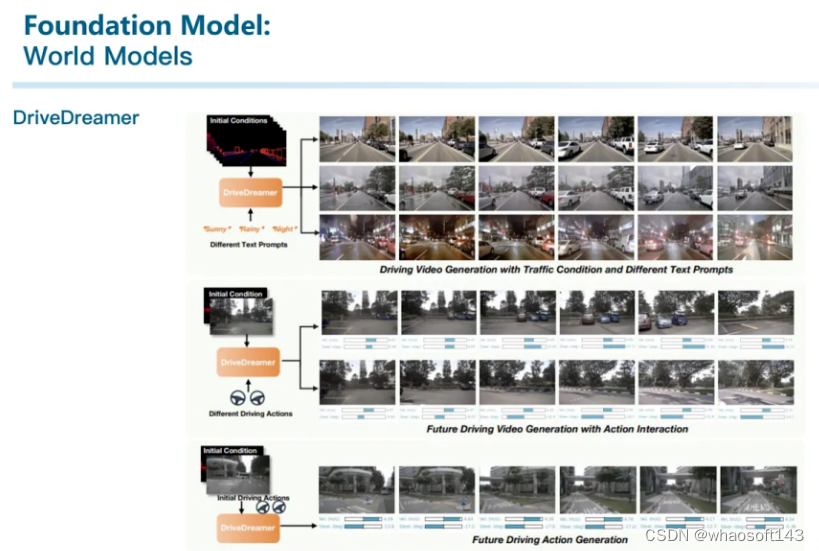
还有国内一家叫做极佳科技和清华大学合作推出的DriveDreamer。我们跟他们交流比较多,不过目前看来不得不屈服于市场:用World Model来生成数据卖。
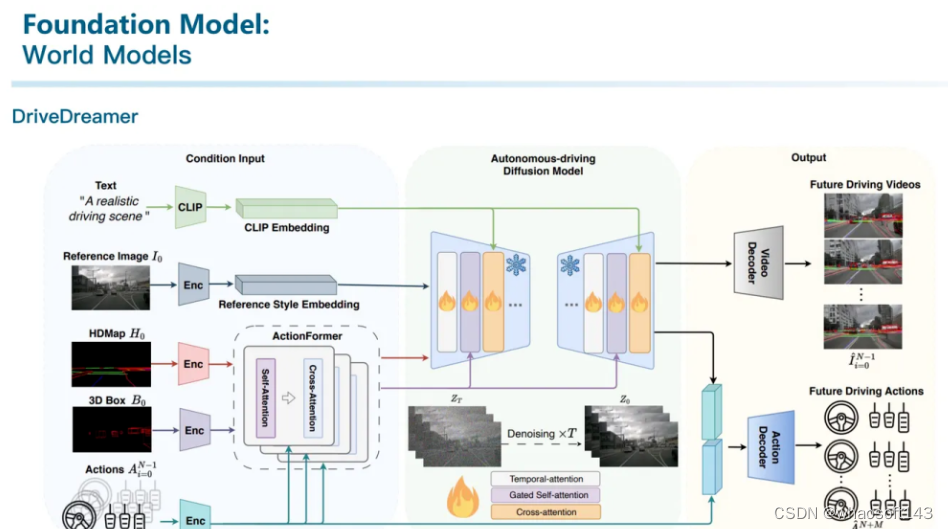
DriveDreamer主要是支持多种prompt输入,包括文本、参考图像、HDMap和3D Box与对应的action。而后由模型在这些信号进行控制的情况下输出未来帧的视频。
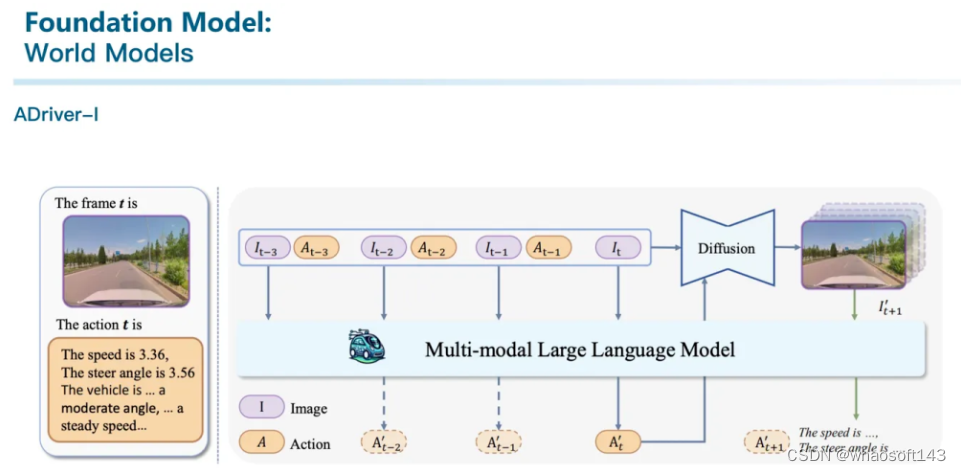
还有上个月刚公开的ADriver-I则是利用VLM进行图像生成的工作。有种把世界模型和LLM相结合的感觉。
第二个值得重点关注的方向就是仿真。
自动驾驶的仿真引擎并不算一个很新的topic。其实目前也有很多仿真引擎被广泛应用,例如Carla、VTD等等。但这些仿真引擎仍然存在诸多问题。比如传感器仿真不够逼真、交通流很多也是基于规则或者机理模型,导致难以进行端到端的闭环仿真测试。
所以其实我们团队过去两年中花了大量的精力在构建一个高质量的端到端闭环仿真引擎。
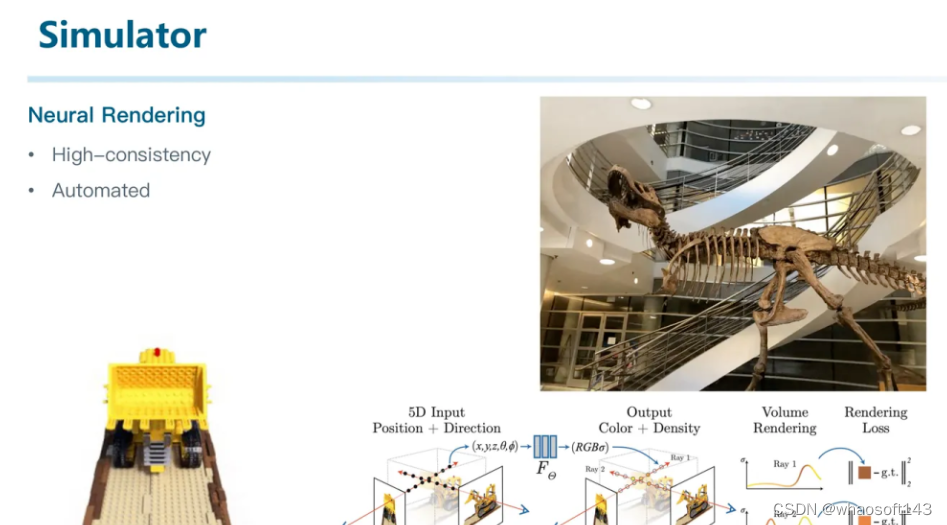
为了获得高一致性的仿真传感器数据,我们采用了神经渲染的思路。这种方法能够用自动化的方法高质量地对场景和物体进行三维重建。

我们构建了名为OASim的基于神经渲染的自动驾驶仿真器(将会在近期开源)。
它能够进行相机、激光雷达等在内的传感器仿真。并且由于我们的技术路线不同于NeRF的体渲染,而是采用了SDF-based的表面渲染,使得我们能够同时重建好形状和外观,甚至可以用来进行数据生成并帮助感知模型训练。
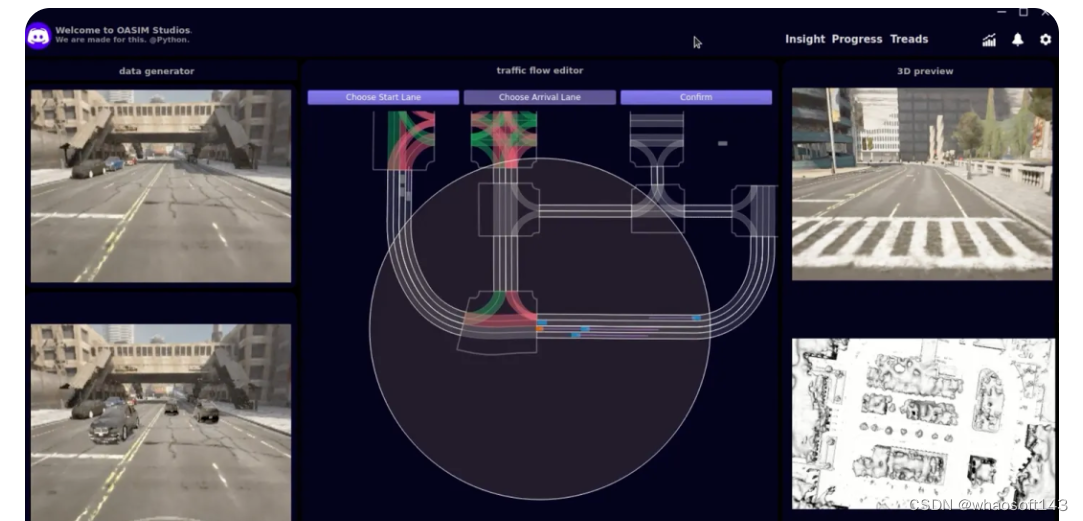
本来是段Demo的录屏的,后面有机会开源的时候再release
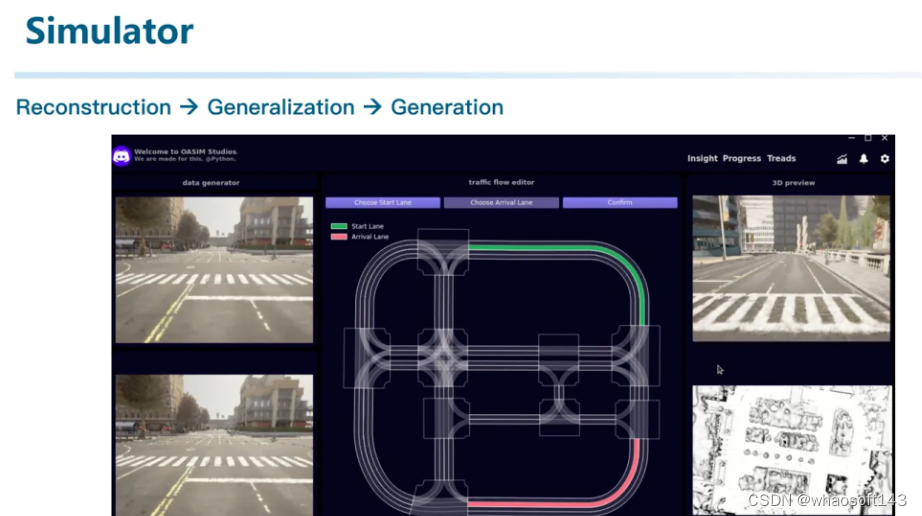
所以我们打通了从重建,到泛化,再到生成的整个链路。甚至我们可以仿真生成激光雷达的数据:
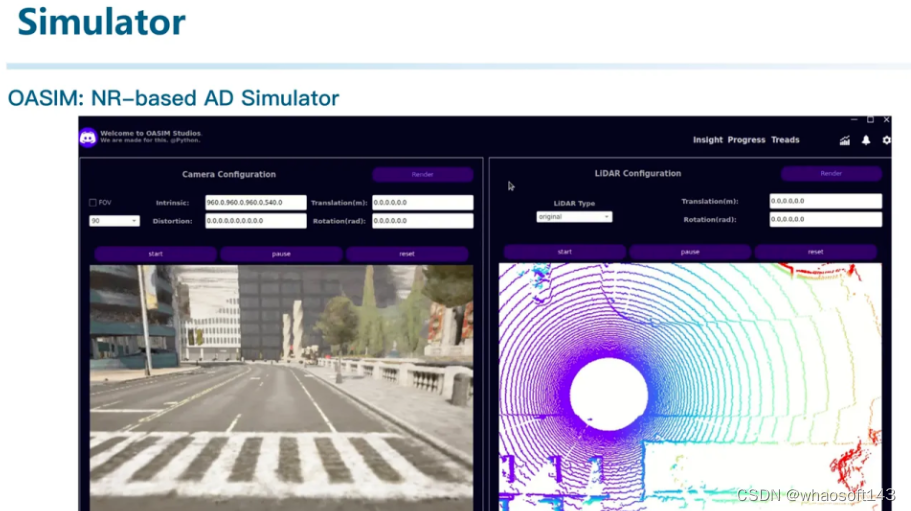
第三点,就是将Agent与自动驾驶相结合,也是我们DiLu的后续研究方向。并不是简单地教大模型开车,而是利用大模型的通用理解能力,通过各种外部工具,务实地实现自动驾驶。不能为了用LLM而用。
目前我们在探索闭环评测,因为我觉得只在开环数据集上进行训练和评测已经略显疲态。尽管有一些基于仿真引擎做闭环训练的工作已经出现,但评测终究是开环的。我们目前正在尝试构建一套基于全功能Agent的pipeline,实现自动驾驶的incremental learning甚至是life-long learning。
最后再介绍一些我觉得和Knowledge-driven AD相关,但可能还需要一些时间才能看到的工作和方向。

首先:小大模型的上车,比如一些1B的模型可能已经具备了在边端推理(甚至训练)的能力。以及一些线性Transformer的工作,如果真有一天能够上车就有趣了。因为现在大模型动辄规模这么大还是因为其本质是个通用模型。但如果我们只需要通用模型在某个子领域的一小部分能力,是不是不需要这么大也可以了?
第二,最近的一个概念:Superalignment。就是我们是否有空了能用小尺寸的大模型来supervise大尺寸的大模型。因为相比用小模型生成合适的语料喂给大模型来训练,可能用小模型来为大模型的训练提供supervise可能是个更容易的任务。OpenAI可能会用它来取代RLHF等简单任务中的人力,但仔细想想,这是不是下一代的「影子模式」?
第三,直接在世界模型中训练AD算法:其实这才是我觉得World Model的本质啊。一个能够建模整个世界的模型,一定能够完美地理解世界,也能够用来将自己对世界的理解拿来supervise自动驾驶算法本身?
第四,重建即感知:这也是最开始入坑多模态传感器融合感知时候的思考。即:其实无论多模态传感器融合、环视相机融合还是什么融合算法,其实本质就是在做「对齐」。这些算法的目标就是把各种不同位置不同模态的数据对齐到一个Unified Space。然后后面的算法再从这个Unified Space出发。其实仔细想想,无论是Pillar、Voxel,还是后来的BEV,和Occupancy,其本质都是一个一个用来对其的Unified Space。既然space这么多,究竟哪个Space最好?通常意义上来说,我们期待学习一种从输入空间到流形空间(关于流形空间很多年前我有过一个回答大家可以看看:求简要介绍一下流形学习的基本思想?)的映射。那么什么空间是最标准的对齐空间呢?我觉得就是3D空间啊。不同模态的传感器,都对齐到同一的3D空间。其实这件事本质就是做三维重建了。。。所以我觉得冥冥之中,「三维重建」和「场景理解」这两件事情总有一天会合二为一。重建即感知。
写到这里,这篇文章基本就结束了。可能废话有些多,主要都是我最近一段时间的思考,和我们团队的一些努力。最后回顾一下主旨
- LLM+AD的出现,意味着大家意识到了这是一个从数据驱动到知识驱动的时机
- 知识驱动可能有三个特性和目标:泛化性、可解释性、持续学习
- 我个人认为,没必要非要追求用LLM实现端到端的自动驾驶。因为大模型存在幻觉、推理速度慢等非常多的问题。我们应该利用的是LLM的知识运用能力、推理能力,并从Agent的角度出发,探索出一种能够利用LLM但不依赖LLM的架构,渐进式地构建新一代的自动驾驶系统。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









