






什么是feed流系统
移动互联网时代,Feed流产品是非常常见的,如朋友圈、微博、抖音等,除此之外,很多App的都会有一个模块,要么叫动态,要么叫消息广场,这些也是Feed流产品。只要大拇指不停地往下划手机屏幕,就有一条条的信息不断涌现出来。就像给宠物喂食一样,只要它吃光了就要不断再往里加,故此得名Feed(饲养)。
feed流系统分类
Feed流的分类有很多种,但最常见的分类有两种:
| 分类 | 例子 | 阐述 |
|---|---|---|
| Timeline | 微信朋友圈 | 按发布的时间顺序排序,先发布的先看到,后发布的排列在最顶端。这也是一种最常见的形式。 这种一般假定用户Feed流中的Feed不多,但是每个Feed都很重要,都需要用户看到 |
| Rank | 抖音、今日头条 | 按某个非时间的因子排序,一般是按照用户的喜好度排序,用户最喜欢的排在最前面,次喜欢的排在后面。 这种一般假定用户可能看到的Feed非常多,而用户花费在这里的时间有限,那么就为用户选择出用户最想看的Top N结果 |
Feed流中的基本概念
- Feed:Feed流中的每一条状态或者消息都是Feed,比如微博中的一条微博就是一个Feed。
- Feed流:持续更新并呈现给用户内容的信息流。每个人微博主页都是一个Feed流。
- Timeline:Timeline其实是一种Feed流的类型,微博,朋友圈都是Timeline类型的Feed流,但是由于Timeline类型出现最早,使用最广泛,最为人熟知,有时候也用Timeline来表示Feed流。
两种Timeline
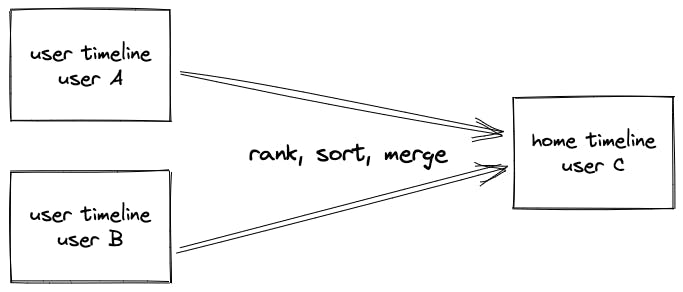
- 关注页Timeline(也叫home timeline):展示多个用户的Feed消息的聚合页面(收集自当前用户所关注的其他用户的feed),比如朋友圈,微博的首页等。
- 个人页Timeline(也叫user timeline):展示单独某个用户(自己或其他用户)发送过的Feed消息的页面,比如微博的个人页等。
比较常见的场景是,一个用户在home timeline里看到了某个很感兴趣的feed,然后进一步点开这个发布者的user timeline,查看这个发布者的其他feed内容。
实现
如果要设计一个Feed流系统,最关键的两个核心,一个是存储,一个是推送。
虽然我们只是以设计一个feed流系统来学习它的原理,但是也应该对标顶级的feed流系统来设计,通过考虑他们所面对的大数据量、高并发场景问题,来使我们能够进行更有价值的思考。
那么最顶级的feed流系统是什么样的呢?以facebook为例,2019年第四季度,facebook有16.6亿日活用户(daily active users),相当于21%的世界人口。25亿月活用户,相当于32%的世界人口。
ok,那我们的目标就是设计一个10亿日活的feed流系统,平均每个用户关注了500个其他用户。
流量预估
假设每个用户平均每天拉取10次feed流,那么每天就有100亿次拉取请求,QPS大约为116K。
存储预估
假设我们为每个用户用缓存存储500条feed以供快速浏览(这500条feed会实时更新,只有极少数人会每天刷超过500条feed),每条feed大约1KB,那就是每人500KB,总共500TB。
我们这里只讲理论,不讲具体的技术选型。具体落地时再考虑使用什么技术组件来满足流量和存储预估的容量。
存储
数据库模型
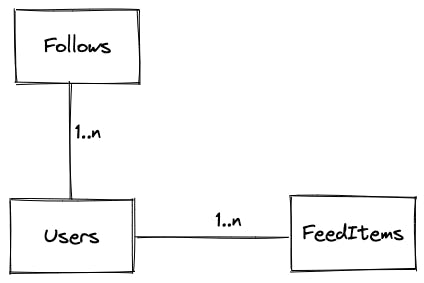
大致可以分为三种信息:
- Users:记录每个用户的个人信息(是否活跃用户、是否大V)
- Follows:记录不同用户之间的关系(用户A关注了用户B)
- FeedItems:记录每条Feed的内容
不同数据之间的关联:一个用户可以关注多个人,一个用户可以发布多条Feed。
数据和存储介质
不同的数据有不同的特性,各自需要单独的存储服务,各自使用合适的存储介质。
持久化存储
| 数据 | 特性 | 存储介质 | 数据服务简称 | 数据内容 |
|---|---|---|---|---|
| Feed中的媒体内容,如图片和视频 | 占用空间大 | 对象存储 | Object store | Video, image file |
| 用户的个人信息,用户之间的关系 | 占用空间小,信息维度多,需结构化存储 | SQL数据库(如MYSQL) | SQL database | user metadata |
| 用户个人主页的feed数据 | 数据结构简单,KV结构,V为列表。需持久化存储。 | NoSQL数据库 | NoSQL data store | user timeline |
feed流系统的所有数据都在持久化存储中保存,也是最原始的数据。但是还需要将一些数据放在缓存中,以应对高并发业务请求。
缓存
存储介质都是NoSQL缓存(如Redis)
| 数据 | 数据服务简称 | 数据内容 |
|---|---|---|
| feed数据 | feed items cache server | Feed_id:metadata |
| 个人页Timeline | user timeline cache server | User_id:( list(feed_id), updated_at ) |
| 关注页timeline | home timeline cache server | Rank,sort,merge user_id: ( list(feed_id), updated_at ) |
推送
推拉之争
Pull Model(读扩散)
拉模型就是在查询时首先查询用户关注的所有创作者 uid,然后查询他们发布的所有文章,最后按照发布时间降序排列。用户每打开一次「关注页」系统就需要读取 N 个人的文章(N 为用户关注的作者数), 因此拉模型也被称为读扩散。

-
优点:逻辑清晰直观,实现简单
-
缺点:每次阅读「关注页」都需要进行大量读取和一次重新排序操作,若用户关注的人数比较多一次拉取的耗时会长到难以接受的地步。
Push Model(写扩散)
推模型就是在创作者发布文章时就将新文章写入到粉丝的关注 Timeline,用户每次阅读只需要到自己的关注 Timeline 拉取就可以了。使用推模型方案创作者每次发布新文章系统就需要写入 M 条数据(M 为创作者的粉丝数),因此推模型也被称为写扩散。

- 优点:拉取操作简单、耗时短,用户体验良好。
- 缺点:粉丝量大的博主发布feed时,写入量巨大。
在线推,离线拉
推拉模型的对比
| - | 优点 | 缺点 |
|---|---|---|
| 推 | 读取快 | 1、逻辑复杂,占用大量存储空间 2、粉丝量大的博主发布feed时写入量巨大 |
| 拉 | 逻辑简单,不占用多余存储空间 | 读取慢,尤其是关注人数多的用户读取feed的速度非常慢 |
看起来推拉模型各有优缺点,但是在实际上,Feed 流是一个极度读写不平衡的场景,一般读写比例在10:1,甚至100:1以上。虽然推模型占用更多的存储空间,但是拉模型消耗的cpu资源也不逞多让。而且用户很难容忍打开页面时需要等待很长时间才能看到内容。因此无论是从资源消耗还是从用户体验出发,推模型都更有实用价值。
在确定要使用推模型的情况下,如何优化写扩散问题呢?实际上不一定需要把作者的新feed推给每个粉丝,因为粉丝中活跃用户数量是有限的,只需要推给活跃用户即可,而不活跃的用户则是等到他们回归的时候,再使用拉模型来构造feed流即可。
因此目前的feed流系统一般混合使用pull模型和push模型
- 非活跃用户的feed流,使用pull模型生成
- 活跃用户的feed流,使用push模型生成
下面的feed发布和feed读取也是以推拉混合模型为基础。
feed发布
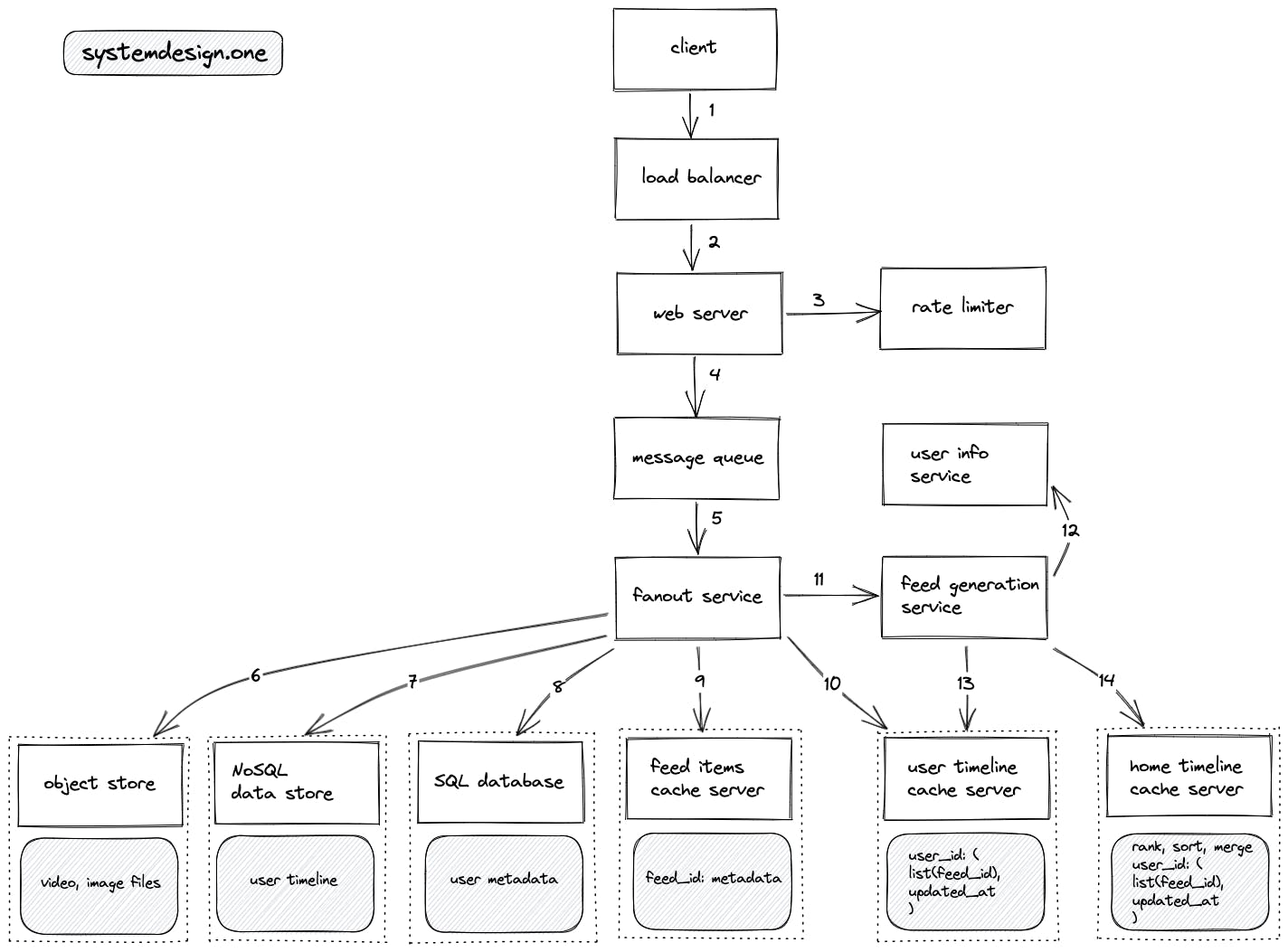
用户(作者)创建一个新feed的写流程如下:
- 客户端向负载均衡服务器发起一个http请求来创建一个新的feed
- 负载均衡服务器选择一个负载较低的web服务器,传递http请求
- web服务有限流功能
- web服务把新feed推到消息队列中做异步处理,并直接返回即时响应
- fanout(扩散)服务从消息队列中消费消息,把feed分发给多个服务器,来给该名作者的粉丝们的feed流里新增该feed
- object store:存储新feed中的图片、视频等资源
- NoSQL data store:把新feed存储在用户的个人主页timeline中(按时间顺序存储)
- SQL database:存储用户信息,不过在写新feed的场景下应该不会涉及用户信息的修改。
- feed items cache server:对于每一个超过一定粉丝量的用户,会存储他们的一部分最新的feed items内容(不包含图片、视频等媒介)在缓存中。
- user timeline cache server:为每个用户缓存他们的个人主页timeline的feed id。
- fanout服务请求feed生成服务
- feed生成服务请求user info服务获取用户信息,包括:作者是否名人、作者的关注者是哪些用户、关注者们的活跃状态(user info服务把用户信息缓存在内存中)
- ?
- feed生成服务为关注者们的home timeline新增feed_id,缓存在home timeline cache server中,生成逻辑的详情写在下面
- 对于非名人作者,feed生成服务用推模型以O(n)复杂度为每个关注者(不管是否活跃)的home timeline中新增一个新的feed_id(n为关注者数量)
- 对于名人作者,feed生成服务使用推拉混合模型,只为活跃关注者生成feed流,不需要管非活跃的关注者,因为他们是使用拉模型来生成home timeline的。
- 生成新feed后,更新每个相关的用户的home timeline,对其进行rank、sort和merge。
feed读取
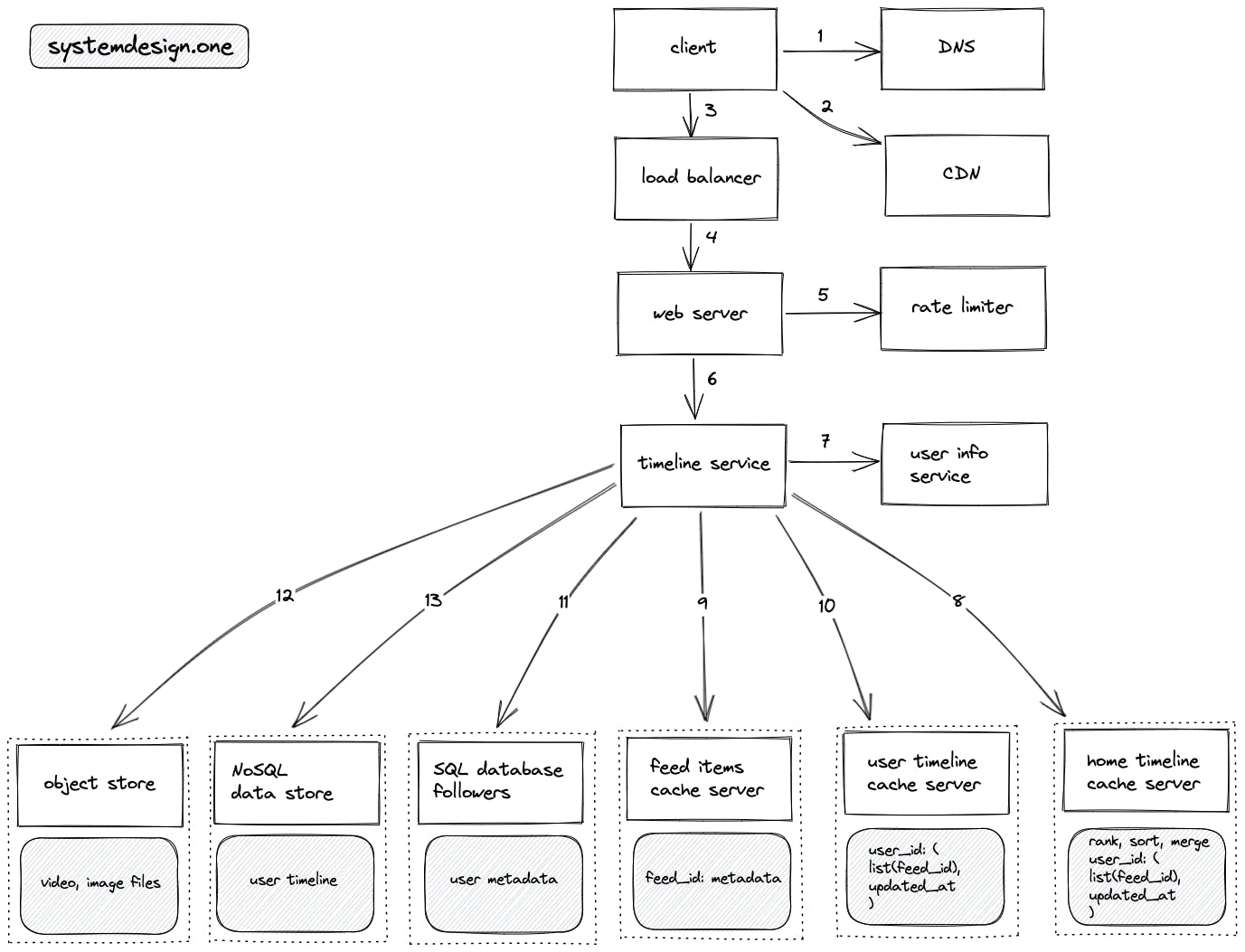
用户拉取feed流的读流程如下:
- 客户端查询DNS服务来做解析域名
- 客户端查询CDN来看目标timeline的feed是否有被缓存
- 客户端向负载均衡服务发起http请求
- 负载均衡服务器选择一个负载较低的web服务器,传递http请求
- web服务有限流功能
- web服务向timeline服务请求timeline内容
- timeline服务请求user info service获取用户信息,包括:当前用户是否活跃、当前用户关注了哪些人、当前用户是否关注了名人。
- 假如用户请求的是home timeline,则timeline服务请求home timeline cache server来获取当前用户的home timline的feed_id列表
- timeline服务请求feed items cache server,根据feed_id列表获取feed内容
- 假如用户请求的是user timeline,则timeline服务请求user timeline cache server来获取目标用户的user timeline的feed_li列表,并且同样到feed items cache server,根据feed_id列表获取feed内容
- 前面请求user info service获取用户信息时,如果cache miss了就请求SQL database来获取用户信息
- timeline服务请求object store补充feed中的图片和视频数据
- feed items cache server缓存不命中时,访问NoSQL data store获取feed内容
- 非活跃用户请求home timeline时,不访问home timeline cache server,而是直接用拉模型来实时计算和获取feed流














 3447
3447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









