







什么是AutoEncoder
自编码器(AutoEncoder)是神经网络的一种,传统的自编码器用于降维或特征学习。
其中包含编码和解码两部分,简单地说编码器将原始数据进行改编,尽可能保留有用信息,去除或尽可能减少无用信息。解码器利用编码器编码后的结果,解出原始信息。
在训练时,目的就是让原始数据与输出数据尽可能得相似。不过为了不让输入输出做y=x得恒等映射,会加入约束条件。
欠完备得自编码器
欠完备指加入编码过后的维度小于原始数据,即做了减少维度的约束。

实现
在这里使用MNIST手写体数据集,它含有60000张(1, 28, 28)的单通道灰度图片
网络结构
使用线性映射,编码器每次经过线性变换维度减少,解码器每次经过线性变换维度倍增。
编码器将数据映射到(1, 3),解码器从(1, 3)解回(1, 28*28)。
AutoEncoder(
(encoder): Sequential(
(0): Linear(in_features=784, out_features=128, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=128, out_features=64, bias=True)
(3): ReLU(inplace=True)
(4): Linear(in_features=64, out_features=16, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=16, out_features=3, bias=True)
)
(decoder): Sequential(
(0): Linear(in_features=3, out_features=16, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=16, out_features=64, bias=True)
(3): ReLU(inplace=True)
(4): Linear(in_features=64, out_features=128, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=128, out_features=784, bias=True)
(7): Tanh()
)
)读取数据
使用pytorch下载数据,也可自行搜索下载。读取数据先设置一下标准化变换。
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]) # 以均值0.5, 方差0.5, 进行标准化
])root = '../AutoEncoder'
train_data = torchvision.datasets.MNIST(root = root, train = True, download = True, transform = transform)
test_data = torchvision.datasets.MNIST(root = root, train = False, download = True, transform = transform)
# download = False则不自动下载数据读取出数据后要将数据变为训练时用的iter格式
batch_size = 128 # 批处理数据 每批数据个数
train_iter = torch.utils.data.DataLoader(train_data, batch_size = batch_size, shuffle = True) # 读取时打乱顺序
test_iter = torch.utils.data.DataLoader(test_data, batch_size = batch_size, shuffle = False) # 测试集不需要打乱顺序实现网络
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, 16),
nn.ReLU(True),
nn.Linear(16, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 16),
nn.ReLU(True),
nn.Linear(16, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28*28),
nn.Tanh()
)
def forward(self, x):
encoder = self.encoder(x.view(x.shape[0], -1)) # 将数据拉直 (batch_size, 1, 28, 28) -> (batch_size, 28*28)
decoder = self.decoder(encoder)
decoder = decoder.view(x.shape) # 将数据变为矩阵形式 (batch_size, 28*28) -> (batch_size, 1, 28, 28)
return encoder, decoder # 返回编码和解码结果训练
这里使用adam优化器,均方差损失函数,损失计算用原始数据和解码后数据。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 优先使用GPU计算
net = AutoEncoder().to(device) # 实例化网络
criterion = nn.MSELoss() # 均方差损失函数
LR = 0.01 # 学习率
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3) # adam优化器
EPOCH = 20 #遍历数据集次数
for epoch in range(EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train() # 打开梯度
# 每轮训练后显示下loss即运算时间
sum_loss = 0.0
batch_count = 0
start = time.time()
for inputs, labels in train_iter:
inputs = inputs.to(device) # 转换为GPU计算
optimizer.zero_grad() # 梯度清零
_, outputs = net(inputs) # 训练时取解码后的数据即可
loss = criterion(outputs, inputs) # 计算解码后数据与原始数据的损失
loss.backward() # 计算梯度
optimizer.step() # 反传更新
sum_loss += loss.cpu().item() # 计算损失
batch_count += 1
print('[epoch:%d] Loss:%.4f Time: %.2fsec'% (epoch + 1, sum_loss/batch_count, time.time() - start))我们进行20轮训练,能得到一个较好的效果,训练时输出如
Epoch: 1
[epoch:1] Loss:0.2500 Time: 19.19sec
Epoch: 2
[epoch:2] Loss:0.1797 Time: 22.97sec
Epoch: 3
[epoch:3] Loss:0.1594 Time: 18.59sec
Epoch: 4
[epoch:4] Loss:0.1509 Time: 17.16sec
Epoch: 5
[epoch:5] Loss:0.1463 Time: 18.69sec
Epoch: 6
[epoch:6] Loss:0.1432 Time: 18.61sec测试
我们看一下解码后的图片效果,不过在那之前先反标准化一下,将数据变回图片的数据形式。
# 转回图片
def to_img(x):
x = 0.5 * (x + 1) # 反标准化
x = x.clamp(0, 1) # 将数值限制在(0-1) 即小于0的置为0 大于1的置为1
x = x.view(1, 28, 28) * 255 # 转换为RGB数值格式
return x写一个测试函数,展示原始图片与编解码后的图片
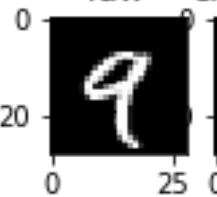
def test(x):
net.eval() # 关闭梯度训练
with torch.no_grad():
_, decoder = net(x) # 获取编解码后的数据
x = to_img(x) # 转回图片形式
decoder = to_img(decoder) # 转回图片形式
fig, axes = plt.subplots(1,2, figsize = (2, 2)) # 建立两个子画布
axes[0].set_title('raw')
axes[0].imshow(x.view(28, 28).numpy(), cmap='gray') # 第一个画布展示原始图片
axes[1].set_title('en-decoder')
axes[1].imshow(decoder.view(28, 28).numpy(), cmap='gray') # 第二个展示编解码后的图片
plt.show()
net.train() # 打开梯度训练调用一下效果
for i in range(3):
test(train_data[i][0])















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









