







目录
常用元素定位方式
为什么要学习元素定位方式
- 让程序操作指定元素,必须先找到此元素
- 程序不像人类用眼睛直接定位到元素
- webDriver提供了八种定位元素的方式。
|
|
|
|---|---|
| id | find_element(By.ID,“id”) |
| name | find_element(By.NAME,“name”) |
| class name | find_element(By.CLASS_NAME,“class name”) |
| tag name | find_elemnt(By.TAG_NAME,“input”) |
| link text | find_element(By.LINK_TEXT,“text”) |
| partial link text | find_element(By.PARTIAL_LINK_TEXT,“partailtext”) |
| xpath | find_element(By.XPATH,“//div[@name=‘name’]”) |
| css selector | find_element(By.CSS_SELECTOR,“#id”) |
使用BY模块定位
- 导入By类
- from selenium.webdriver.common.by import By
- By类的方法
- 示例:find_element(By.ID,“id”)
- 需要两个参数,第一个参数为定位的类型,由By提供,第二个参数为定位的具体方式。
定位方式总结
- id、name、class_name、tag_name:根据元素的标签或元素的属性来进行定位
- link_text\partial_link_text:根据超链接的文本来进行定位(a标签)
- xpath:为元素路径定位
- css:为css选择器定位(样式定位)
1、ID定位
说明:HTML规定id属性在整个HTML文档中必须是唯一的,id定位就是通过元素的id属性来定位元素;
前提:元素有id属性
id定位方法:find_element(By.ID,“id”)
实行案例-1需求:打开百度首页(https://www.baidu.com/),通过id定位,搜索框输入内容“id定位演示”
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.ID,'kw').send_keys('id定位演示')
sleep(2)
driver.quit()
2、name定位
说明:HTML规定name属性来指定元素名称,name的属性值在当前文档中可以不是唯
一的,name定位就是根据name属性来定位。
前提:元素有name属性
name定位方法:find_element(By.NAME,“name”)
实行案例-2需求:打开百度首页(https://www.baidu.com/),通过name定位,搜索框输入内容“name定位演示”
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.NAME ,'wd').send_keys('name定位演示')
sleep(2)
driver.quit()
3、class_name定位
说明:HTML规定class来指定元素的类名,class定位就是根据class属性来定位,用法
和name,id类似。
前提:元素有class属性
class_name定位方法:find_element(By.CLASS_NAME,“class_name”)
实行案例-3需求:打开百度首页(https://www.baidu.com/),通过class定位,搜索框输入内容“class定位演示”
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.CLASS_NAME ,'s_ipt').send_keys('class定位演示')
sleep(2)
driver.quit()
4、tag_name定位
说明:HTML本质就是由不同的tag(标签)组成,而每个tag都是指同一类,所以tag定位效
率低,一般不建议使用;tag_name定位就是通过标签名来定位。
tag_name定位方法:find_elemnt(By.TAG_NAME,“input”
实现案例-4需求:打开百度首页(https://www.baidu.com/),通过tag定位input标签,搜索框输入内容“tag_name定位演示”
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.TAG_NAME, 'input').send_keys('tag_name定位演示')
sleep(2)
driver.quit()
#这里搜索到的input标签太多,运行是定位不到的,仅做演示
5、link_text定位
说明:link_text定位于前面4个定位有所不同,它专门用来定位超链接文本(文本值)
前提:定位的元素是链接标签(a标签)
link_text定位方法:find_element(By.LINK_TEXT,“text”)
实现案例-5需求:打开百度首页(https://www.baidu.com/),通过link_text(链接文本"hao123")定位到hao123按钮,并进行点击操作
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.LINK_TEXT,"hao123").click()
sleep(2)
driver.quit()
6、partial_link_text定位
说明:partial_link_text定位是对link_text定位的补充,partial_link_text为模糊匹配;link_text为全部匹配。
前提:定位的元素是链接标签(a标签)
partial_link_text定位方法:find_element(By.PARTIAL_LINK_TEXT,“partailtext”)
通过传入a标签你局部文本或全部文本来定位元素,要求输入的文本能够唯一找到这个元素
实现案例-6需求:打开百度首页(https://www.baidu.com/),通过link_text(链接文本“hao”)定位到hao123按钮,并进行点击操作
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.LINK_TEXT,"hao").click()
sleep(2)
driver.quit()
7、元素组定位
元素组定位方式:find_elements(By.xxx,“xxx”)
- 查找返还定位所有符合条件的元素
- 返还的定位元素格式为列表格式
说明:
列表数据格式的读取需要指定下标(下标从0开始)
案例要求:打开读书屋登录界面(http://43.139.38.222:18001/user/login.html),通过元素组定位输入用户名和密码
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('http://43.139.38.222:18001/user/login.html')
eles = driver.find_elements(By.TAG_NAME, 'input') #这里element需要使用复数
user = eles[1].send_keys('19162274227')
pwd = eles[2].send_keys('123456')
sleep(2)
driver.quit()
#这里整个逻辑是:运行一共定位到5个input标签,这里分别取下标为1和2对应手机号和密码的input标签
xpath和css定位
为什么要学习xpath和css定位
-
在实际项目中标签没有id/name/class属性
-
id/name/class属性值为动态获取,随着刷新或加载而变化
**xpath、css定位可以解决以上两类问题**
xpath定位
xpath概述:–位置定位(路径方式)
- xpath即为xml path的简称,它是一种用来确定XML文档中某部分位置的语言。
- HTML可以看你做是XML的一种实现,所以selenium用户可以使用这种强大的语言来定位元素
- xpath为强大的语言,是因为它有非常灵活的定位策略
定位方法:find_element(By.XPATH,“//div[@name=‘name’]”)
xpath定位策略(方式)
- 路径定位–绝对路径、相对路径
- 利用元素熟悉性定位
- 层级与属性结合定位
- 属性与逻辑定位结合
1、路径定位(绝对/相对路径)
绝对路径:从最外层元素到指定元素之间所有经过元素层级路劲;如/html/body/div/p[2]
提示:
- 绝对路径是以/开始
- 通过浏览器查看元素属性,右击复制xpath快速生成
相对路径:从第一个符合条件元素开始(一般配合属性来区分);如//*[@id=“searchKey”]
提示:
- 相对路径以//开始
- 通过浏览器查看元素属性,右击复制xpath快速生成
- 语法://标签名[@属性=’属性值‘]
2、利用元素属性
快速定位元素,利用元素唯一属性
示例:find_element(By.XPATH,“//input[@id=‘kw’]”)
案例要求:打开论百度首页(https://www.baidu.com/),通过xpath定位搜索框,输入“xpath定位”
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.XPATH,"//input[@id='kw']").send_keys('xpath定位')
sleep(2)
driver.quit()
3、层级与属性结合
要找到的元素没有属性,但是它的父级有;
示例:find_element(By.XPATH,“//label[@id=‘btnSearch’]/i”)
案例要求:打开读书屋首页('http://43.139.38.222:18001/)直接点击搜索图标
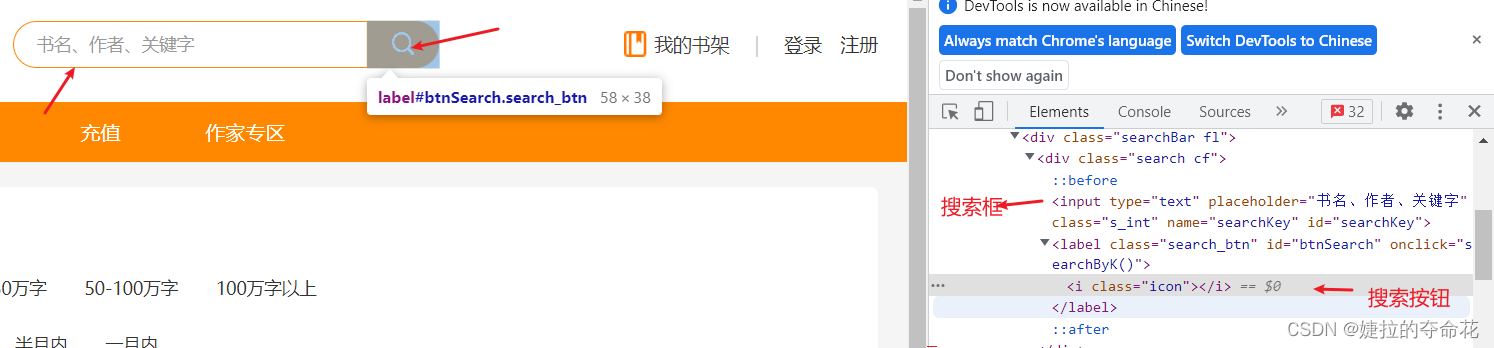
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('http://43.139.38.222:18001/')
driver.find_element(By.XPATH,"//label[@id='btnSearch']/i").click()
sleep(2)
driver.quit()
4、属性与逻辑结合
解决元素之间相同属性重名问题;
示例://input[@id=‘name’ and class=‘pwd’]
css定位
css概述:
- css是有一种语言,它用来描述HTML和XML的元素显示样式
- css语言中有css选择器,在selenium中也可以用这种选择器来进行元素定位
- css定位方式比xpath快,而且css的语法非常强大,所以非常推荐这种方式定位
定位方法:
css点位策略(方式)
- id选择器
- class选择器
- 元素选择器
- 属性选择器
- 层级选择器
ID选择器
根据元素id属性来选择
格式:**#id属性值 **如:#kw选择id属性值为kw 的所有元素)
案例要求:打开百度首页(https://www.baidu.com/),通过css定位,输入
“css定位”
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys('css定位')
sleep(2)
driver.quit()
class选择器
根据元素class属性来选择
格式:**.class属性值 **如:#kw选择class属性值为kw 的所有元素)
案例要求:打开百度首页(https://www.baidu.com/),通过class定位,输入
“class定位”
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.CSS_SELECTOR,".s_ipt").send_keys('class定位')
sleep(2)
driver.quit()
元素选择器
根据元素标签名来选择
格式:element 如:input ==>find_element(By.CSS_SELECTOR,“input”)(选择所有input元素)
属性选择器
根据元素的属性名和值来选择(一般不考虑id和class属性,i的属性用#id值,clsss属性用.class值)
格式:[attribute = value] 如:
案例要求:打开百度首页(https://www.baidu.com/),通过属性定位,输入
“属性定位”
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.find_element(By.CSS_SELECTOR,"[name='wd']").send_keys('属性定位')
sleep(2)
driver.quit()
层级选择器
根据元素的父子关系来选择
格式:element>element 如:label> i(返还所有p元素下所有i元素
提示:>可以用空格代替,如input 或者p [type = ‘password’
案例要求:打开读书屋首页(http://43.139.38.222:18001),通过层级定位,方式一:实现定位搜索按钮,方式二:实现定位搜索框并输入文字
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('http://43.139.38.222:18001/')
driver.find_element(By.CSS_SELECTOR,"label i").click()
#方式二:
#driver.find_element(By.CSS_SELECTOR,"div [name='searchKey']").send_keys("利用标签/[属性='属性值']定位搜索框输入这段文字")
sleep(2)
driver.quit()
总结
| 选择器 | 例子 | 描述 |
|---|---|---|
| #id | #wk | id选择器,选择id="wk"的所有元素 |
| .class | .wk | class选择器,选择class="wk"的所有元素 |
| element | input | 选择所有input元素 |
| [attribute=value] | [type=“password”] | 选择type="password"的所有元素 |
| element>element | p>input | 选择所有父元素为p的input元素 |
下拉列表的定位
下拉列表定位
下拉列表常见的前端表现形式:Select+Option 和 ul+li
Select类型的下拉框
案例1:https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=wf,定位发车时间中的日期
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from time import sleep
driver = webdriver.Chrome()
driver.get('https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=wf')
eles = driver.find_element(By.ID,"cc_start_time")
#1.用Select类方法select_by_visible()定位选项
Select(eles).select_by_visible_text("18:00--24:00")
#2.select_by_value
Select(eles).select_by_value("18002400")
#3.select_by_index
Select(eles).select_by_index("4")
sleep(2)
driver.quit()
ul+li类型的下拉框
待补充。。。。。。。。。。
元素常用属性与方法
webElement常用属性和方法
待补充。。。。。。。。。。
案例
待补充。。。。。。。。。。















 955
955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









