







 本文详细介绍了如何利用OpenCV的级联分类器实现车道线检测,从数据标记、模型训练到测试结果分析。通过数据扩增,提升了模型的检出率,但同时也增加了训练时间和可能对数据质量的影响。
本文详细介绍了如何利用OpenCV的级联分类器实现车道线检测,从数据标记、模型训练到测试结果分析。通过数据扩增,提升了模型的检出率,但同时也增加了训练时间和可能对数据质量的影响。
1 摘要
在ADAS辅助自动驾驶系统中感知算法扮演着十分重要的作用,但是由于L2级的ADAS系统出于成本的考虑,导致处理芯片的算力十分有限,因此对于常规的目标检测问题无法使用最佳的深度学习方法进行推理分析,主要能使用的还是传统算法opencv来解决实际问题,本文就介绍一种使用开源opencv库中的级联分类器来实现车道线检测的方法。
2 opencv 级联分类的训练过程
2.1 数据标记
图片标记可以使用opencv中自带的标记工具也可以使用其他标记工具如labelme,这里使用的是opencv中自带的opencv_annotation.exe,为了使用方便可以把调用命令写成一个bat文件,标注工具的调用方式如下:
.\opencv_annotation.exe -a=D:\cascade\train\positives.txt -i=D:\\cascade\\sourceImage
其中-a 表示的是标注后生成的txt文件的路径,-i 表示的是源图片的路径。

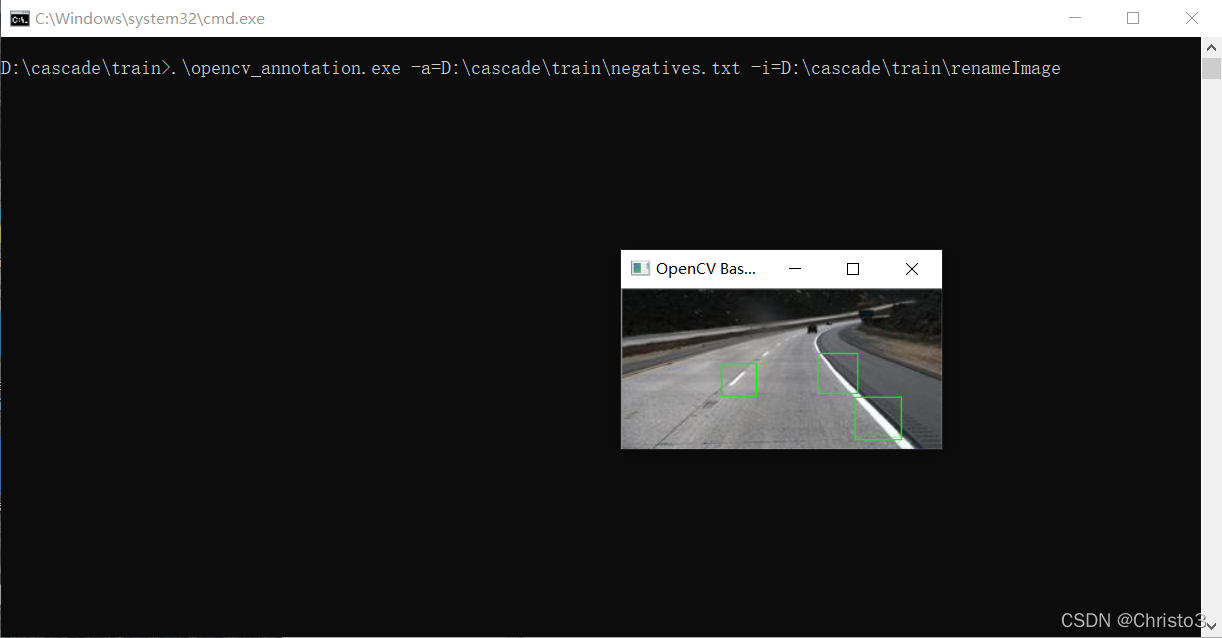
运行命令后会弹出图像框,然后用鼠标点击左上和右下两个点,会选定一个红色框,按C确认后红色框变为绿色,如图所示,如果需撤回之前的操作则键入D,如果当前图片标记完成则键入N,进入到下一张图片的标记。
- 由于为了方便整理正样本数据,这里是根据标记产生的
txt,将框选出来的目标从原图中抠出来保存,其次这里对正样本数据进行了扩增处理,然后再重新生成txt文件,生成的txt文件表示如下:
positives.txt的内容如下:
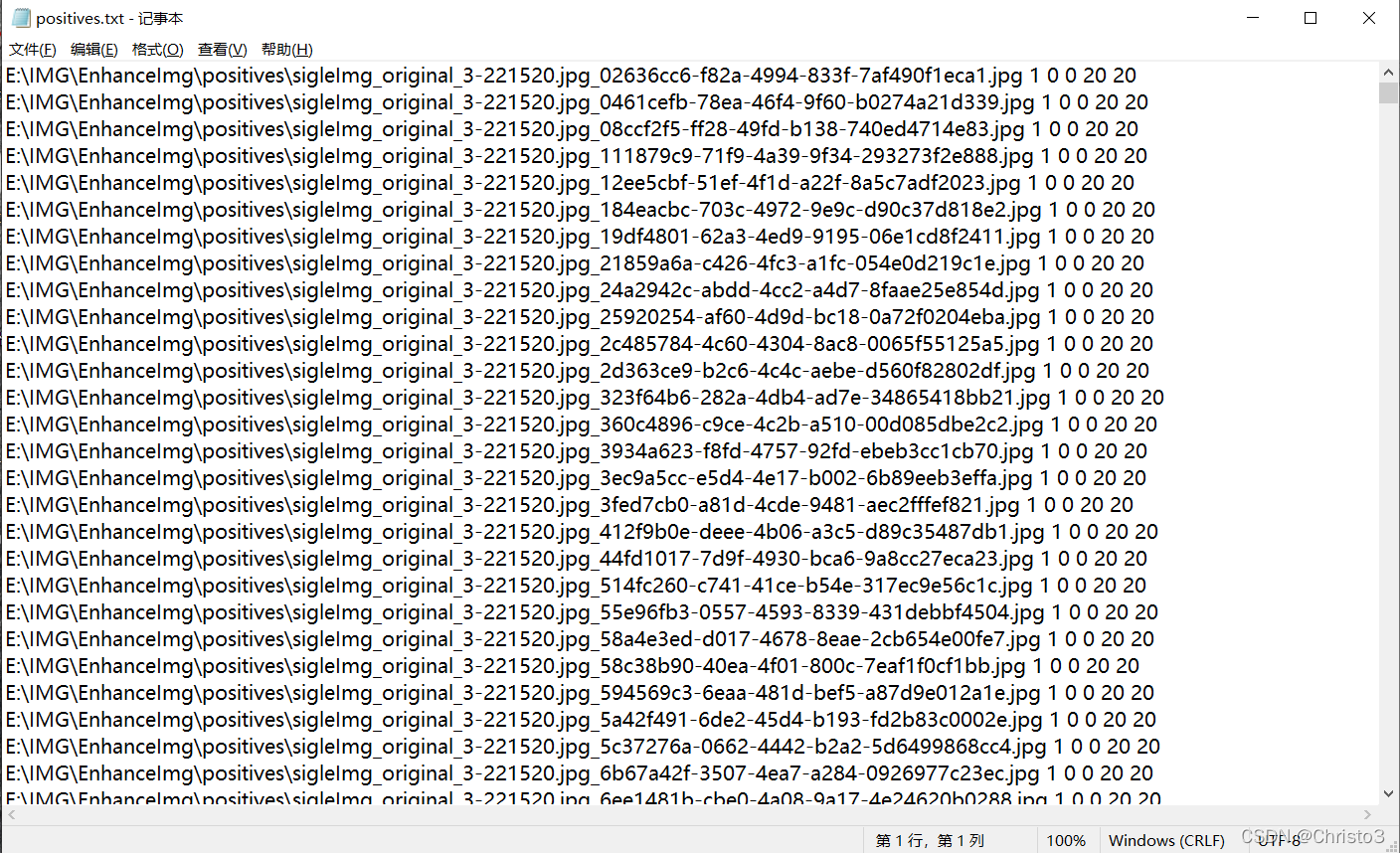
内容格式为:图片路径 图片中目标个数 目标物体的横纵坐标 目标物体的宽 目标物体的高
正样本图片如下:

负样本图片只需不包含目标物体即可,对尺寸大小以及类型无要求
负样本的txt文件
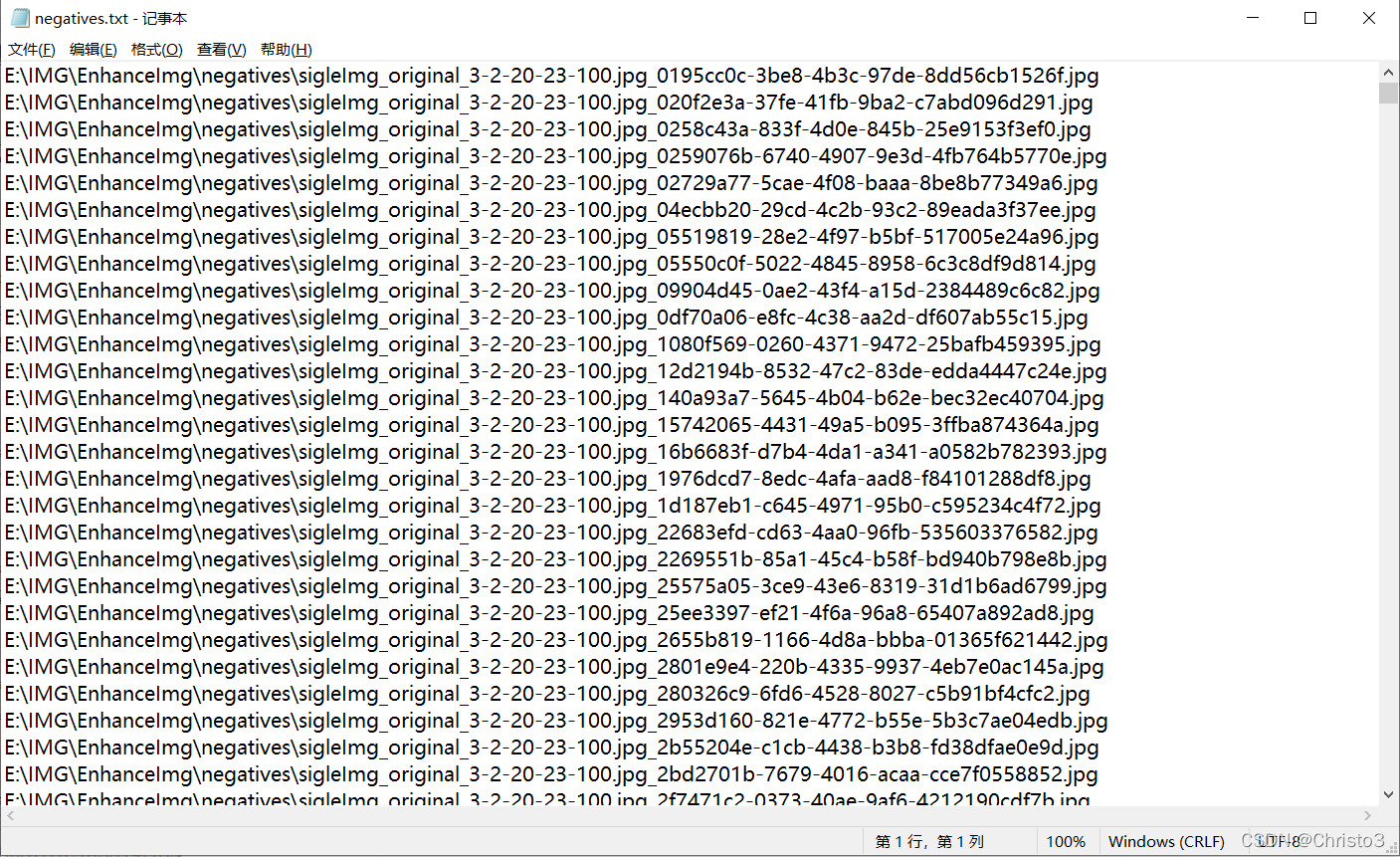
这里同样对负样本进行了数据扩增增加样本数量,才导致文件名过长。
2.2 生成pos.vec用于训练
由于训练级联分类需要将正样本生成特定的.vec格式,opencv已经提供了生成的程序,这里我们只需要调用即可,调用命令如下:
@echo off
.\opencv_createsamples.exe -vec pos.vec -info positives.txt -num 891 -w 20 -h 20
pause
2.3 训练模型
模型训练调用命令
@echo off
.\opencv_traincascade.exe -data xml -vec D:\cascade\train\pos.vec -bg D:\cascade\train\negatives.txt -numPos 6000 -numNeg 10000 -numStages 20 -featureType HAAR -minHitRate 0.995 -maxFalseAlarmRate 0.5 -w 20 -h 20 -precalcValBufSize 8000 -precalcIdxBufSize 8000
pause

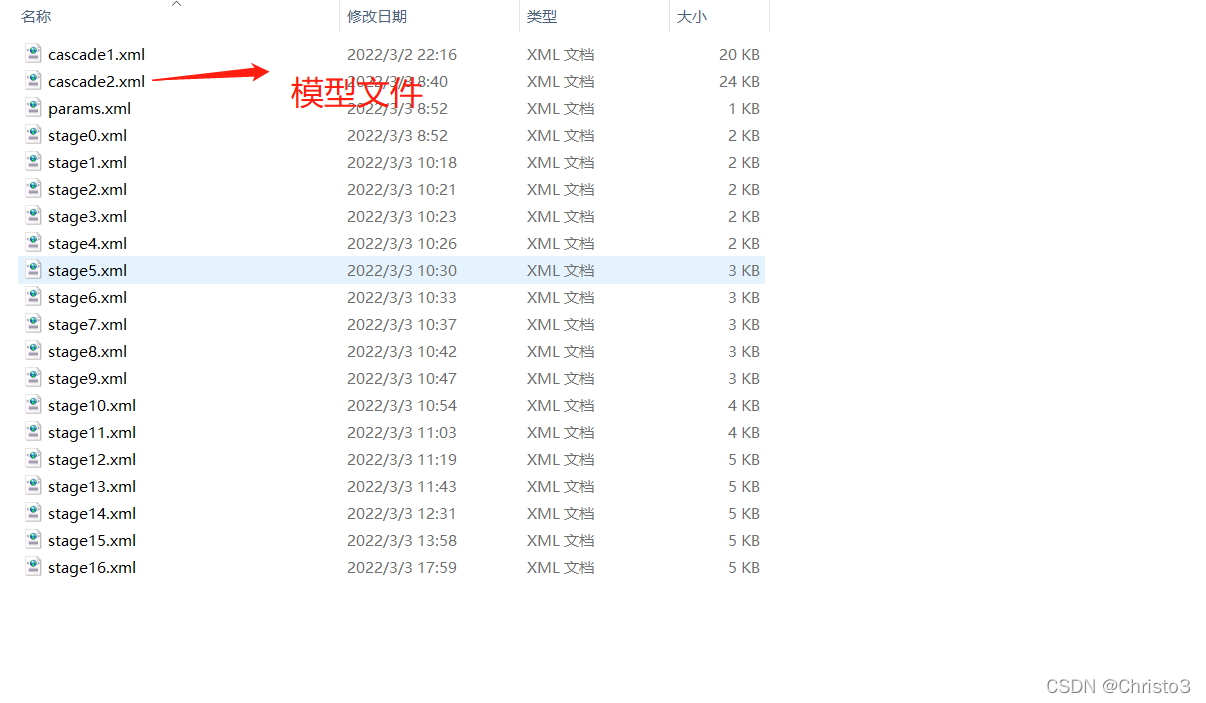
模型训练完成后会生成一个xml文件,也就是最终需要调用的模型文件。
2.4 测试结果
- 测试
demo
// cascade.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <opencv2/opencv.hpp>
#include <iostream>
#include <string>
using namespace cv;
using namespace std;
int main(int argc, char** argv) {
String fileName = "D:\\cascade\\train\\xml\\cascade1.xml";//设置文件路径
CascadeClassifier face_classifier;//创建分类器
if (!face_classifier.load(fileName))
{//加载分类数据
printf("could not load face feature data...\n");
return -1;
}
//string imagePath = "D:\\temp\\cascade\\test";
string imagePath = "D:\\cascade\\train\\laneDataset\\image\\0531\\1492627520493208456\\*.jpg";
vector<String> vecImage;
glob(imagePath, vecImage);
for (int i = 0; i < vecImage.size(); i++)
{
Mat src = imread(vecImage[i]);
if (src.empty())
{
printf("could not load image...\n");
return -1;
}
//imshow("input image", src);
Mat gray;
cvtColor(src, gray, COLOR_BGR2GRAY);
vector<Rect> faces;
face_classifier.detectMultiScale(gray, faces, 1.2, 3, 0, Size(20, 20));//在多尺度上检测
for (size_t t = 0; t < faces.size(); t++)
{
rectangle(src, faces[static_cast<int>(t)], Scalar(0, 0, 255), 2, 8, 0);
}
imshow("detect faces", src);
waitKey(0);
}
return 0;
}




上图测试的结果是正样本数为891,负样本数为1200训练的模型,从图中可以看出,虽然模型能够正确检出车道线的位置,但是每一帧的检出率不高,因此怀疑是训练样本太少的问题,为了提高每一帧的检出率,通过尝试数据扩增增大训练的数据集数量进行模型训练再观察效果。
3 扩增数据重新训练模型
3.1 数据扩增并训练
采用数据扩增方法,对样本集进行扩增,扩增后的数据集为正样本为8910张图片,负样本为17682张图片,然后采用同样的方式进行训练。训练时间一共花费了1天13小时。测试效果如下




3.2 总结
增大数据集的确可以提高检出率,但是相对应的训练时间也会增长不少,而且数据集数量越大,每一阶段的训练会更加困难,同时采用数据扩增的方式虽然丰富了数据的类型,但是对其数据质量可能会产生一定的影响。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











