






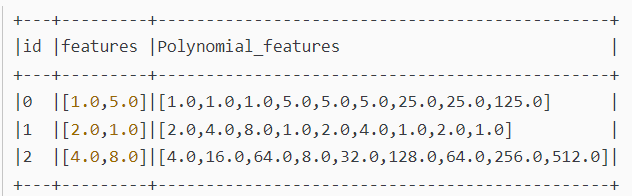
多项式转化 PolynomialExpansion
degree=3 时,x ,xx ,xxx ,y ,xy ,xxy ,yy ,xyy ,yyy
类别型数据常用独热编码:
字符转换成数字索引 StringIndexer
在转换成独热编码 OneHotEncoder
使用stringindex将category转换成categoryIndex 之后,本来a,b,c是没有大小顺序的,但是转换成数字索引后数字0,1,2有了大小关系,因此使用onehotencoder再次转换

一般只在测试集上进行独热编码,测试数据中可能会出现新的类别,比如‘e’,因此,编码时可以先预留一种‘rare’类别,新的类别都归进去
文本处理
基于DataFrame的StopWordsRemover处理
停止词的词表一般不需要自己制作,有很多可选项可以自己下载选用。中文暂时没有词表。
remover.transform(sentenceData).show(truncate=False)
truncate=False:结果show的时候太长也不会做截断,属性为True时会截断

Tokenize 将一句话转换成一个单词的序列


Count Vectorizer

说明features中第一行id为1 的数据[0,1,2],[1,1,1],含义,左边是值,右边是出现次数,表示0出现1次,1出现1次,2出现一次。
要先使用fit对数据进行扫描,才知道数据的出现次数,进行编码,然后才能transport
TF-IDF

from pyspark.ml.feature import SQLTransformer
df = spark.createDataFrame([
(0,1.0,2.0 ),
(1, 3.0,2.0),
(2,4.0,7.0 )],
["id", "v1","v2"])
sqlTrans = SQLTransformer(statement="SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__")
sqlTrans.transform(df).show()
spark.stop()
+---+---+---+----+----+
| id| v1| v2| v3| v4|
+---+---+---+----+----+
| 0|1.0|2.0| 3.0| 2.0|
| 1|3.0|2.0| 5.0| 6.0|
| 2|4.0|7.0|11.0|28.0|
+---+---+---+----+----+
















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









