






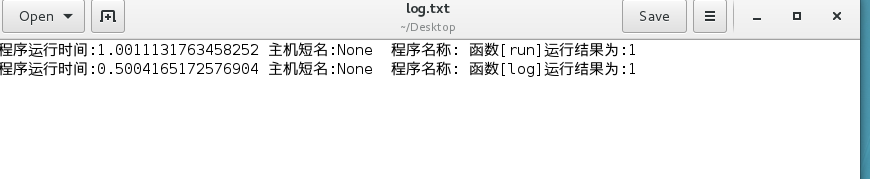
一. 记录日志装饰器练习题
好的日志对一个软件的重要性是显而易见的。如果函数的入口都要写一行代码来记
录日志,这种方式实在是太低效了。 那么请你创建一个装饰器, 功能实现函数运
行时自动产生日志记录。 日志格式如下:
程序运行时间 主机短名 程序名称: 函数[%s]运行结果为[%s]
产生的日志文件并不直接显示在屏幕上, 而是保存在 file.log 文件中, 便于后期
软件运行结果的分析.
def log(fun):
def wapper(*args,**kwargs):
start_time = time.time()
content = fun()
stop_time = time.time()
run_time = stop_time - start_time
os_name = os.getenv('computername')
def_name = fun.__name__
s = '程序运行时间:'+ str(run_time) + ' 主机短名:' + str(os_name) + ' 程序名称: 函数[' + str(def_name) +']运行结果为:'+str(content)
logs = print(s)
with open('log.txt', 'a+') as f:
f.writelines(s + '\n')
return content
return wapper
@log
def run():
print('测试')
time.sleep(1)
return 1
@log
def log():
print('log')
time.sleep(0.5)
return 1
run()
log()
.
二. 斐波那契数列的装饰器练习: 实现高速缓存递归
在数学上,费波那契数列是以递归的方法来定义:
用文字来说,就是费波那契数列由 0 和 1 开始,之后的费波那契系数就是由之前的两数相
加而得出。首几个费波那契系数是:
0,1,1,2,3,5,8,13,21,34,55,89,144,233……(OEIS 中的数列 A000045)
装饰器 1: 添加高速缓存的装饰器 num_cache
如果第一次计算 F(5) = F(4) + F(3) = 5
第二次计算 F(6) = F(5) + F(4)
显然 F(5)已经计算过了, F(4)也已经计算了, 我们可否添加一个装饰器, 专门用
来存储费波那契数列已经计算过的缓存, 后期计算时, 判断缓存中是否已经计算过了, 如
果计算过,直接用缓存中的计算结果. 如果没有计算过, 则开始计算并将计算的结果保存在缓
存中. 装饰器 2: 程序运行计时器的装饰器 timeit
该装饰器用来测试有无高速缓存求斐波那契数列, 它们两者运行的时间效率高低
import os
import time
def timmer(fun):
def wrapper(*args, **kwargs):
start_time = time.time()
result = fun(*args, **kwargs)
end_time = time.time()
print("%s run %.5f" % (fun.__name__, end_time - start_time))
return result
return wrapper
def num_cache(fun):
import json
cache_filename = 'cache.txt'
if os.path.exists(cache_filename):
with open(cache_filename) as f:
try:
cache = json.load(f)
# print(cache)
except:
cache = {}
def wrapper(num):
if num in cache:
result = cache.get(num)
return result
else:
result = fun(num)
cache[num] = result
return result
return wrapper
@num_cache
def fib(num):
if num <= 2:
return 1
else:
return fib(num - 1) + fib(num - 2)
@timmer
def fib1():
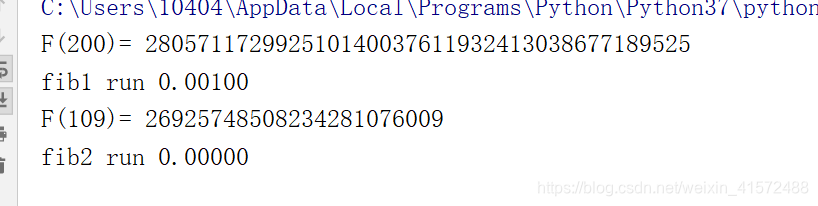
result = fib(200)
print('F(200)=', result)
@timmer
def fib2():
result = fib(109)
print('F(109)=', result)
fib1()
fib2()


def cmp_str(s1='',s2=''):
edition1 = s1.split('.')
edition2 = s2.split('.')
if len(edition1) > len(edition2):
num = len(edition1)
for i in range(len(edition2),len(edition1)):
edition2.extend('0')
else:
num = len(edition2)
for i in range(len(edition1), len(edition2)):
edition1.extend('0')
for i in range(num):
if int(edition1[i]) > int(edition2[i]) :
return 1
elif int(edition1[i]) == int(edition2[i]) :
if i == num-1:
return 0
else:
continue
elif int(edition1[i]) < int(edition2[i]) :
return -1
edition1 = ['0.1','1.0.1','7.5.2.4','1.01','1.0']
edition2 = ['1.1','1','7.5.3','1.001','1.0.0']
for i in range(5):
s = cmp_str(edition1[i],edition2[i])
print(s)

四. 模块与包练习题: 微信好友数据分析与展示1. 已知 itchat 可以获取好友的信息, 此处统计好友的省份分布;2. 获取分布好友最多的 5 个省份;3. 将省份分布的数量基于 pyecharts 模块以条形图的方式展示;附加需求: 将每个省份的好友备注名(RemarkName)存入依次存入对应省份的件中;e.g.文件: 陕西省.txt文件: 山东省.txt4. 将上述 编写的代码封装为模块, 并实现模块的制作与发布;
import itchat
from collections import Counter
#from pyecharts import Line
from pyecharts import Bar
province_list = []
all_pro = []
def friend_get():
itchat.auto_login(hotReload=True)
friends = itchat.get_friends()
for friend in friends:
all_pro.append(friend['Province'])
province_list.append([friend['RemarkName'], friend['Province']])
def provice_max(pro_list):
max_provice = counter(all_pro)
print(max_provice)
list = []
for i in range(5):
list.append(max_provice[i][0])
print(list)
# for i in pro_list:
# if i[1] in list:
# with open(i[1], 'r') as f:
# f.write(i[0]: i[1])
# print(i[0], i[1])
def counter(arr):
return Counter(arr).most_common(5)
def table():
max_provice = counter(all_pro)
sortedFriend = {}
for i in len(max_provice):
sortedFriend[max_provice[i][0]] = max_provice[i][1]
bar = Bar("好友省份分布")
bar.add("", list(sortedFriend.keys()), list(sortedFriend.values()))
#bar.render('doc/province.html')
friend_get()
provice_max(province_list)















 956
956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









