










警告: 本篇博客是记录一个学习的过程,中间会有很多弯路
kettle中可以使用多种输入输出, 常用的有:表输入,文件输入,表输出,文件输出等, 本文用到的输入为txt文本文件输入, 输出类型为输出到kafka
这里解释一下为什么要是用kafka而不是直接生成文件到本地
因为需要处理的数据是比较多的, 一般是几亿条, 或者几十亿条, 文件大概是几个G到几十G, 如果生成的文件落地到磁盘, 那将会非常耗费资源
kettle清洗数据建立快速索引
kettle从数据源获取数据, 这里是从txt文件中获取
首先新建一个转换
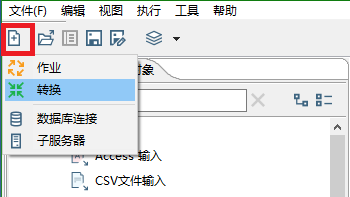
在输入目录中, 找到"文本文件输入",拖动到右侧编辑页面中

按住"shift"键 , 将两个图标连接起来, 双击图标对"文本文件输入"进行编辑, 点击"浏览"选择文本文件, 选择后点击"增加"即可添加到输入文件目录中,最后点击"确定"

随后还需要对输入的数据的字段进行设置, 再次双击打开, 点击"字段" – > “获取字段” --> “Manimal width”,这里我只有一个字段, 处理完结果如下, 点击确定即可

对文件中数据进行格式化加工,输出json格式数据
在左侧目录中,选择"输出" --> "JSON output"输出,双击打开设置页面

目前kettle自带的json Output 可以支持三种输出模式
- 输出json字符串的值
- 以json格式写入到文件
- 输出json格式的值,同时写入数据到指定文件

在操作中可以设置应该如何输出, 是只需要输出值? 还是需要写入到文件? 还是需要既输出值又需要写入到文件?
设置中:
- Json条目名称, 这个是用来配置生成的json数据的键的, 可参考下面的json格式, 这里默认是data
- 一个数据条目的数据行:用来配置data中有多少个json串,如果设置为不为0的数, 那么就会生成多个文件,每个文件中的json有指定数量的子json串,如果不设置值, 所有数据都会在同一个文件中
- 输出值: 生成json串在后面使用时如何调用, 这里配置的是变量字段的名称
- 兼容模式没啥大用, 影响不大
- 文件名: 如果设置为写入到文件或者既输出值又写入到文件, 那么需要在这里指定输出位置和文件名
- 扩展名:在这里指定文件的类型, 常用的也就是js和txt
但是存在一个问题就是我们需要写入kafka中, logstash对kafka中的topic进行读取,这时kafka中topic的每条记录都应该是json格式,例如
{"name":"tomcat"}
而kettle中自带json Output插件输出的json格式为:
"{""data"":[{""pwd"":""aol.com""},{""pwd"":""mail.ru""},{""pwd"":""mail.ru""},{""pwd"":""plews.com""},{""pwd"":""mail.ru""},{""pwd"":""rambler.ru""},{""pwd"":""aol.com""},{""pwd"":""gmail.com""},{""pwd"":""gmail.com""},{""pwd"":""hotmail.com""}]}"
这明显不是我们要求的样子啊,哪来那么多的引号啊???
然后看一下使用json Output的输出到文件的效果,这里可以设置生成文件类型为js
这时
输出到js文件中格式是:
{"data":[{"pwd":"aol.com"},{"pwd":"mail.ru"},{"pwd":"mail.ru"},{"pwd":"plews.com"},{"pwd":"mail.ru"},{"pwd":"rambler.ru"},{"pwd":"aol.com"},{"pwd":"gmail.com"},{"pwd":"gmail.com"},{"pwd":"hotmail.com"}]}
这个格式好像不错啊, 是不是可以考虑文本文件输入, 然后使用json格式化处理, 输出为js格式, 然后用另一个转换文件读取这个js文件, 使用javaScript脚本进行处理, 那不就成了嘛!
但是! 因为需要落地生成js文件, 会造成大量的文件冗余(每处理一次数据, 就会生成一个很大的文件),所以kettle自带的json生成工具摒弃,只好使用最不智能的工具了:使用js来控制生成json数据,在左侧目录找到"脚本" --> “JavaScript代码” 拖到右侧编辑区

将"文本文件输入"与"JavaScript代码"连接起来, 双击打开编辑就可以看到在左侧的Input fields中有字段, 这个字段就是在"文本文件输入"中进行设置的
在右侧的代码区域可以直接使用, 类似于这些变量就是方法中的参数, 拿过来直接用就行了,
我们把拿过来的参数进行组装
var jsonResult = '{"pwd":"'+pwd+'"}';
点击"获取变量"就可以获取到我们自己定义的josnResult变量,随后确定即可

预期结果就是上面说到的我们需要的一个json格式,这时候应该配置一个"文本文件输出",这样才能在文件中获取到这个变量, 看一下js处理的结果是什么格式
在左侧目录中找到"输出" – > “文本文件输出” 进行配置,

选择"浏览", 设置输出的位置和名称,“扩展名"设置文件格式
在设置字段中点击"获取字段” --> “最小宽度” 获取我们刚才定义的变量jsonResult

这个时候保存运行, 看一下执行的结果!..啊哦???
"{""pwd"":""aol.com""}"
"{""pwd"":""mail.ru""}"
"{""pwd"":""mail.ru""}"
"{""pwd"":""plews.com""}"
"{""pwd"":""mail.ru""}"
"{""pwd"":""rambler.ru""}"
"{""pwd"":""aol.com""}"
"{""pwd"":""gmail.com""}"
"{""pwd"":""gmail.com""}"
"{""pwd"":""hotmail.com""}"
怎么会是这样呢?
思考一下! 思考一下! 为什么呢?
可能输出到txt文件中, 就是长这样的吧, 那是不是上面json Output工具生成的格式也是没有问题, 只是这个落地到txt文件之后, 才多了那么几个引号的, 那我们来验证一下, 如果数据不落地, 直接写入到kafka的topic中去呢? 格式是不是就是正确的了呢? 试一试 试一试…
json格式数据写入到kafka中
在kettle中使用kafka需要先下载kafka的插件, Producer下载地址, Consumer下载地址
这两个需要单独下载, 解压之后将文件夹中的文件复制到如下路径, 重启kettle即可看到
# steps文件夹需要自己新建
你的安装路径\data-integration\plugins\steps\
找到plugins文件夹, 新建一个"steps"的文件夹, 将下载的两个解压包中的文件都放在steps中, 重启kettle即可

此时在搜索框中输入"kafka"就可以看到Consumer和Producer了
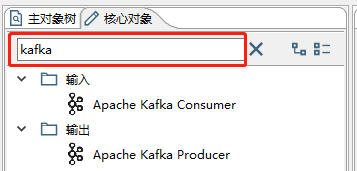
我们这里需要使用的是Producer, 拖出来

需要配置的位置
- Topic name kafka的topic
- Message field name 引用的变量,这里我配置的是之前的JavaScript中定义的变量
这些在下面的列表中找
- client.id 配置的是kafka所在机器的ip地址
- metadata.broker.list 配置kafka所在机器的ip:端口号
其他的设置为default即可
点击"确定"后保存, 运行走起…
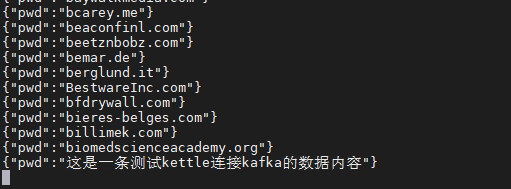
bingo!
格式完全没问题, 那我们之前的猜想就是正确的, 写入到txt文本中的json串, 如果不落地成文件, 单纯的在系统中使用时, 是不会多来那么多引号的, 现在这种形式的json, 就是logstash想要的, 那我们把中间转换成json的JavaScript替换掉, 换成由json Output输出json串应该也是没有问题的了!
一次一次尝试
之前看过一个关于JSON Output使用的介绍, 说是把JSON Output的 “条目名称“设置为 空, 然后”一个数据条目的数据行“设置为"1” 就可以召唤神龙, 不是, 就可以达到我们预期的效果, 我试了一下, 并不是这样的,文档地址 放在这了, 你们可以看一下, 如果你能解决, 在留言板告诉我一声

我这样设置写入到kafka之后数据是这样的

这…还是有一个没名的父亲啊…
所以, javaScripts脚本代码还是有必要处理一下的, 采用这种结构, json生成数据之后,需要处理一下, javaScripts来将字符串转成Object, 然后获取正确数据之后再转换会json串

先给JSON Output中的父亲赋个名, 交data爸爸, 然后js中先把json转为Object, 喊一声爸爸(data), 就可以获取到他的儿子"们”, 然后叫他的第0个儿子上来登基(转换成json), 就是我们要的盛世明君… 看不懂这段的 可以自己看代码, 我觉得你能看懂…
// 这里
var jsonResult = JSON.stringify(JSON.parse(value).data[0]);
最后kafka中配置的使用变量名需要改变为js中新创建的jsonResult变量, 然后, 保存…启动…看结果…

OJBK !
数据已经非常完美的进入到kafka中了, 接下来就是由logstash对kafka进行读取了
使用logstash读取kafka数据写入数据到elasticsearch
logstash的使用, 我们在之前的一篇文章中已经介绍过了, 不同的是 文章中介绍的kafka + logstash + elasticsearch他们三个组合使用的模式是
文本文件(txt) → logstash → kafka → logstash → elasticsearch
第一个logstash从文本文件中获取数据, 转为json格式, 然后写入到kafka中, 第二个logstash读取kafka中的数据, 写入到elasticsearch中, 这里kafka的作用是对大量数据进行削峰处理
对比现在的情况
现在是kettle将json数据写入到kafka中, 那后面依旧是使用logstash 读取kafka数据 ,然后写入到elasticsearch中
kafka的作用是使处理后的数据不落地, 避免太多文件占用系统存储资源
等会 说到这 , 我想起了一个问题…
logstash是可以直接读取文件, 然后格式化为json格式, 写入到elasticsearch中的, 那么…kettle并不是必须把数据转成json格式啊, 直接把处理好的数据放在kafka中就可以了, logstash读取kafka的同时, 将他json化, 然后导入elasticsearch, 那不就完事了吗?
这一天白忙活了?
我得试试直接存入kafka能不能行…
嗨呀!
糟糕的一天…
好像不太聪明的样子…
首先把中间过程全去掉, 直接从文件读取之后, 输出到kafka(单击连接线, 就可以让他失效)

然后简单地修改一下使用的变量, 修改一下存入kafka的topic
logstash这边, 我们直接使用logstash+kafka+logstash+elasticsearch模式中logstash从kafka获取数据到elasticsearch的配置文件,
现在也是这样的, 然后我们新建一个elasticsearch的索引, logstash启动配置文件如下:
#_________range_______从kafka获取数据后写入es中________
input{
kafka {
bootstrap_servers => "192.168.....:9092"
topics => "logstash_json"
codec => "json"
}
}
filter{
mutate{
remove_field => ["host","path","@timestamp","@version","tags"]
rename => {"message"=>"pwd"}
gsub => [ "pwd", "\r", "" ]
}
}
output{
elasticsearch{
action => index
hosts => "192.168.....:9200"
index => "logstash_json"
document_id => "%{pwd}"
}
stdout{}
}
启动logstash, 对kafka进行监听
然后启动kettle转换, 向kafka发送数据…
e…we get some errors as fellow…
[2020-05-15T16:20:43,722][ERROR][logstash.codecs.json ][main] JSON parse error, original
data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token
'avtomatika': was expecting ('true', 'false' or 'null')
at [Source: (String)"avtomatika.ru"; line: 1, column: 11]>, :data=>"avtomatika.ru"}
这是什么意思, json转换失败? message中有源数据? 啥意思嘛?
复制, 百度, search…
有一个解决方案说的是

意思大概是:JSON解析错误可能是由于输入尝试着读取codec => json {}
我的数据格式显然不是JSON, 而是赤裸裸的数据啊, 那…这不就好说了吗? 我们在logstash直接读取文本文件时, 读取数据源时配置的数据类型是什么, 看一下就知道了啊
#文本文档通过logstash直接写入ElasticSearch
input{
file{
path => ["/root/dic/post2.txt"]
# path => ["/root/range_dic/test.txt"]
start_position => "beginning"
}
}
filter{
mutate{
remove_field => ["host","path","@timestamp","@version"]
rename => {"message"=>"pwd"}
gsub => [ "pwd", "\r", "" ]
}
}
output{
elasticsearch{
hosts => "192.168.....:9200"
index => "postoffice2"
document_id => "%{pwd}"
}
stdout{}
}
这里没设置数据类型, 那好, 我们把现在的配置文件中这个配置注释掉就可以了
input{
kafka {
bootstrap_servers => "192.168.....:9092"
topics => "logstash_json"
#codec => "json"
}
}
重新启动,重新测试…

看一下elasticsearch中数据


问题完美修复, 这一天啊, 走了太多弯路…但是收货也是不小的
总结
这是一篇摸索着前进的文章, 然后有很多弯路, 但是还是不错的 美滋滋
又是没有bug的一天 美滋滋















 8200
8200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









