






持续更新中
- 基础理论
- 数据库问题
- 技术问题
- 工具
- json类
- 代码问题
- Mybatis错误
- Mybatis批量insert
- Line:xx;number: xx; columnNumber: xx; 元素类型 "insert" 必须后跟属性规范 ">" 或 "/>"
- Mybatis传递List集合报错 Available parameters are [collection, list]
- Mybatis传递List集合报错 Available parameters are [dataList, param1]
- Duplicate entry '0' for key 'PRIMARY'
- <![CDATA[]]>
- $与#的区别
- find_in_set函数
- join的使用
- mybatis中批量更新CASE WHEN的使用
- mybatis where 和 if else 的写法
- EXIST 和 IN的区别
- 批量插入时的问题
- 工作中遇到Spring的坑
- cannot retry due to redirection, in streaming mode executing
- no suitable HttpMessageConverter found for response type and content type
- feign.FeignException:status 500 readingXXX
- 生成流转MultipartFile通过feign发送到文件服务上传
- 拦截器中注入feign报nullpointer
- @resource和@autowired的区别
- 使用RestTemplate报错java.lang.IllegalStateException: No instances available for xxxx
- HTTP请求拦截和修改参数,过滤请求
- GIT代码管理
- IDEA开发工具
- 中间件
- 服务器
基础理论
VO DTO DO PO 的区别
l 用户发出请求(可能是填写表单),表单的数据在展示层被匹配为VO。
l 展示层把VO转换为服务层对应方法所要求的DTO,传送给服务层。
l 服务层首先根据DTO的数据构造(或重建)一个DO,调用DO的业务方法完成具体业务。
l 服务层把DO转换为持久层对应的PO(可以使用ORM工具,也可以不用),调用持久层的持久化方法,把PO传递给它,完成持久化操作。
l 对于一个逆向操作,如读取数据,也是用类似的方式转换和传递,略。
灰度发布
最原始的发布方法就是全量替换然后更换新服务,也称为全量发布,但是会带来一个问题,全量发布时会使系统处于无法访问的情况,在现代所处的环境下无法访问会直接影响一个软件的使用感受和经济收入,是无法接受的,因此为了改进全量发布的影响,提出灰度发布的概念,按照一定的策略上线部分新版本,同时保留老版本,然后让部分用户体验新版本,通过一段时间新版本的反馈收集,比如:功能、性能、稳定性等指标,然后再决定是否逐步升级直至全量升级或全部回滚到老版本。灰度发布其中又有很多种方法,这里提最经典的三种。
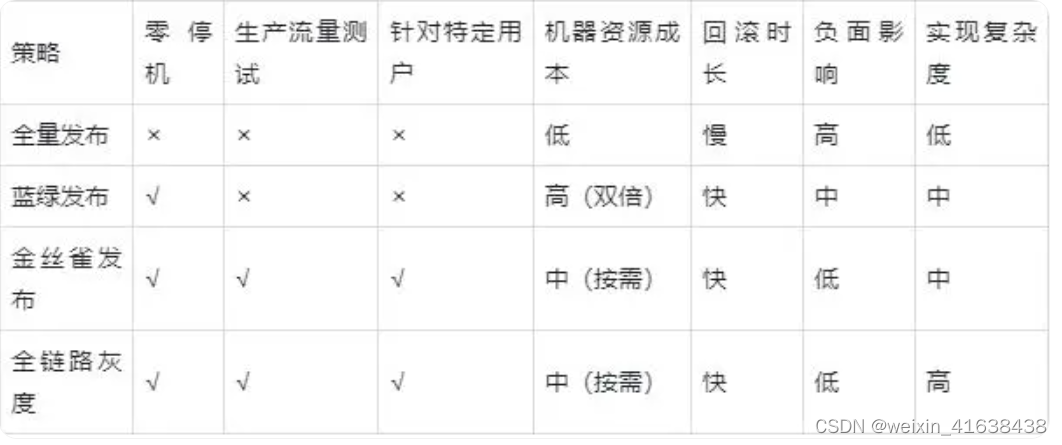
金丝雀发布
据说以前有个典故,矿工开矿前,会先放一只金丝雀下去,看金丝雀是否能活下来,用来探测是否有毒气,金丝雀发布也是由此得名。
这个典故用在金丝雀发布上面也是同样一个道理,即先升级服务一个实例,如果该实例没有问题,再全部升级剩余实例,如果有问题,再进行回滚。
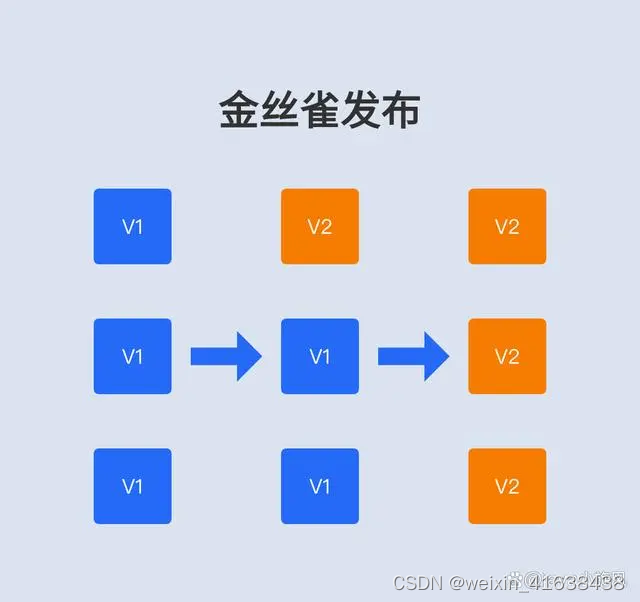
滚动发布
滚动发布则是在金丝雀发布的基础上进行的改进和优化,第一次也是使用金丝雀发布,后续则使用多批次的形式发布剩余实例,每次批次之间会进行观察,如果有问题,再进行回滚。
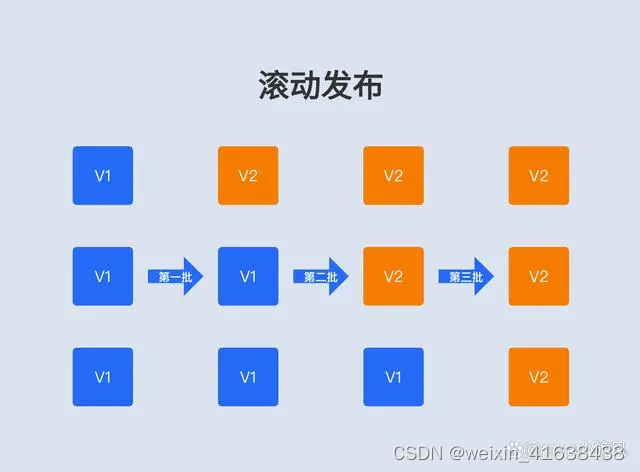
蓝绿发布
蓝绿发布比较简单,只是对全量发布的一种优化而已,发布前不用全部停机,而是另外部署新版本全部实例,然后再把流量全部再切换到新版本。
数据库问题
mysql多条件查询筛选
遇到需要多个字段影响去重的情况时,使用concat函数,连接多个字段作为查询结果,同时使用该查询结果作为分组条件group by,就可以达到多字段去重
例:
SELECT *,CONCAT(eid,YEAR (update_time) - 1) FROM a GROUP BY CONCAT(eid,YEAR (update_time) - 1)
//同时受eid和update_time影响去重
UUID()重复和去掉’-’
在navicat中由于软件设计会使select出来的uuid重复,可以试用md5函数解决,例:
select UUID(),from a;
//uuid全部相同
select md5(UUID()), from a;
//uuid不相同且uuid为32位
多表联合更新
多表联合更新.
主要是关联join和非关联where两种
在调用redis的工具类时,RedisTemplate无法注入(值为null)的解决办法
@Autowired
private RedisTemplate redisTemplate;
private static RedisTemplate<Object, Object> redis;
@PostConstruct //构造时赋值
public void redisTemplate() {
redis = this.redisTemplate;
}
修改后还是报nullpointer,查了一下需要把事务的注解从启动类去掉
springboot中@EnableTransactionManagement注解
先上原链接 https://blog.csdn.net/qq_32370913/article/details/105924209
简单来说就是springboot项目启动不需要加这个注释,在springboot的默认配置文件spring.factories中,存在自动配置
org.springframework.boot.autoconfigure.transaction.TransactionAutoConfiguration,\
已经自动帮我们开启了事务配置,不需要额外再加该注释
执行sql文件
mysql> source /opt/district.sql
mysql行转列
把某些行数据的值改造成列字段在同一条数据展示
需要先group by 对数据分组
再分别计算出每个条件下的值
select name,
sum(case when course='java' then grade end) as java,
sum(case when course='C++' then grade end) as C++,
sum(case when course='C#' then grade end) as C#
from test group by name

技术问题
工具
EasyExcel使用及遇到的问题
十分方便好用的excel导出框架,但是在使用的时候遇到两个问题。
一个是导出excel命名为中文,需要把filename转化为utf-8格式,同时前端请求需要设置为utf-8格式,这样获取得文件名就为中文,这里只给后端设置代码
response.setContentType("application/vnd.ms-excel");
response.setCharacterEncoding("utf-8");
String fileName = URLEncoder.encode("设备列表", "UTF-8");
response.setHeader("Content-disposition", "attachment;filename="+DateUtil.getDateFormat(DateUtil.getDayBefore(new Date()))+fileName+".xlsx");
另外一个问题是某些字段无法写入数据,问题在于easyexcel使用在实体类上写注解的方式写excel时,需要使用驼峰命名实体类每一个变量,我某些字段为拼音首字母加英语,在拼音部分存在大写,导致无法写入,需要将拼音部分改成小写就能正确写入数据
//错误的
@ExcelProperty(value = "接入量", index = 2)
private Integer jRCount;
//正确的
@ExcelProperty(value = "接入量", index = 2)
private Integer jrCount;
通过配置模板动态生成word
主要是用到poi的XWPFTemplate,十分的简便
class Goods {
private int count;
private String name;
private String desc;
private int discount;
private int tax;
private int price;
private int totalPrice;
// getter setter
}
class Labor {
private String category;
private int people;
private int price;
private int totalPrice;
// getter setter
}
class Data{
List<Goods> goods;
Labor labor;
}
LoopRowTableRenderPolicy policy = new LoopRowTableRenderPolicy();
Configure config = Configure.builder()
.bind("goods", policy).bind("labors", policy).build();
Data data=new Data;
XWPFTemplate template = XWPFTemplate.compile(resource, config).render(
data
);
密码正则校验
https://blog.csdn.net/wantingtingting/article/details/87938299
OKHTTP3 FormBody 踩坑
因为有接口对接需要用到表单格式(application/x-www-form-urlencoded)提交数据,使用okhttp3实现,调用包装类formBody的时候,因为参数里有个url,Formbody内部会自动给所有参数encode,导致调用异常
public final class FormBody extends RequestBody {
private static final MediaType CONTENT_TYPE = MediaType.get("application/x-www-form-urlencoded");
private final List<String> encodedNames;
private final List<String> encodedValues;
public Builder add(String name, String value) {
if (name == null) throw new NullPointerException("name == null");
if (value == null) throw new NullPointerException("value == null");
names.add(HttpUrl.canonicalize(name, FORM_ENCODE_SET, false, false, true, true, charset));
values.add(HttpUrl.canonicalize(value, FORM_ENCODE_SET, false, false, true, true, charset));
return this;
}
}
问题场景:表单类型数据提交,需要传带特殊符号的参数
问题原因:FormBody类会自动把所有参数encode,特殊字符会变转义字符
解决方案:使用RequestBody去代替FormBody
RequestBody.create(MediaType.parse("application/x-www-form-urlencoded"),
"nameA" + "=" + "valueA"+ "&" +
"nameB" + "=" + "valueB");
json类
Cannot deserialize instance of xxxxx out of START_ARRAY token
对于object对象,传进了List
Gson进行json转换时,new Gson().toJson(object),遇到null值不进行转换问题
Gson gson = new GsonBuilder()
.serializeNulls()
.create();
Object转json 和json 转对象
gson.toJson(list)
List<Student> retList = gson.fromJson(s2,new TypeToken<List<Student>>() {}.getType());
代码问题
java 获取明天的时间、昨天时间、明天0点的时间
链接: java 获取明天的时间、昨天时间、明天0点的时间.
修正昨天应该使用 calendar.set(Calendar.HOUR_OF_DAY,-24);
jdk8的straem中的Collectors.toMap报NullPointerException
主要就是value或者key中遇到null值,会抛错
详情看看这位大佬的和解决方法
解决方法
xxl/测试类中调用ThreadPoolTaskExecutor不生效
想在xxl定时任务中调用ThreadPoolTaskExecutor去跑业务,发现不生效,看了一段解释有了比较清楚的认识
这个主要是由于executor.execute() 激活的线程都是守护线程,主线程结束,守护线程就会放弃执行。
守护线程也叫后台线程,是指在程序中运行的时候在后台提供一种通用服务的线程,并且这种并不属于程序中不可或缺的部分。因此,当所有的非后台线程结束时,程序也就终止了,同时会杀死进程中的所有后台线程。比较常用的是java GC。
xxl任务执行器和测试类都是主线程,在调用线程池后主线程就会死亡,而其的调用也会放弃执行。
Mybatis错误
Mybatis批量insert
使用mybatis foreach标签
具体用法如下:
<!-- 批量保存(foreach插入多条数据两种方法)
int addEmpsBatch(@Param("emps") List<Employee> emps); -->
<!-- MySQL下批量保存,可以foreach遍历 mysql支持values(),(),()语法 --> //推荐使用
<insert id="addEmpsBatch">
INSERT INTO emp(ename,gender,email,did)
VALUES
<foreach collection="emps" item="emp" separator=",">
(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>
Line:xx;number: xx; columnNumber: xx; 元素类型 “insert” 必须后跟属性规范 “>” 或 “/>”
mapper.xml文件相关sql语句编写错误,存在中文字符或缺少分隔符
Mybatis传递List集合报错 Available parameters are [collection, list]
使用Param注解绑定数据名
原:
void insert( List<Data> dataList);
新:
void insert=(@Param("dataList") List<Data> dataList);
Mybatis传递List集合报错 Available parameters are [dataList, param1]
在传入数据绑定对应类型得数据
原:
<insert id="insert" parameterType="java.util.List" keyProperty="xx" useGeneratedKeys="true">
INSERT INTO xx
(xx)
VALUES
<foreach collection="dataList" item="Data" separator=",">
(
#{XX,jdbcType=INTEGER})
</foreach>
</insert>
新:
<insert id="insertBatch" parameterType="java.util.List" keyProperty="seqId" useGeneratedKeys="true">
INSERT INTO xxx
(xx)
VALUES
<foreach collection="dataList" item="Data" separator=",">
(
#{Data.XX,jdbcType=INTEGER}
</foreach>
</insert>
Duplicate entry ‘0’ for key ‘PRIMARY’
主键字段,没有添加自增 关键字 AUTO_INCREMENT,开启自增
<![CDATA[]]>
把选中字符串作为纯文本输出
$与#的区别
$输出为纯文本,#会根据字符型和数值型做不同的匹配,因为使用$如果输出字符型时需要加上引号
find_in_set函数
一个sql函数,可以用在查询上,也可以用在where条件上
FIND_IN_SET(str,strList)
str要查询的字符串
strList要查目标字段或者字符串
作为查询的时候返回的是字符串所在的位置
做的是精准匹配,
1
select find_in_set('1','1,2,3,4,5,6');
2
select find_in_set('2','1,2,3,4,5,6');
0
select find_in_set('7','1,2,3,4,5,6');
0
select find_in_set('2','1,21,3,4,5,6');
0
select find_in_set('1','');
null
select find_in_set(null,'1,2,3,4,5,6');
null
select find_in_set('1',null);
where上是返回是否符合该条件的数据
join的使用
今天学到一个很打开思路的做法,我要做关联查询,目的是要对对应条件筛选。
现在有一个主表信息表info,有一个标签表tag,标签分为公共和私人标签,通过标签表的type字段区分,两个表通过id关联。
现在要实现分页查询同时对两种类型标签的过滤筛选
select distinct
a.ID,
b.ids as publicIds,
c.ids as privateIds
from info a
left join tag b on a.id = b.info_id and b.type=1
left join tag c on a.id = c.info_id and c.type=2
可以同时连接标签表两次获取两次id,做两种标签的过滤筛选
mybatis中批量更新CASE WHEN的使用
这块浪费了很多时间主要就是一些语法的问题,其实就是使用sql函数case when,而且在其他地方查的资料当更新数据超过一千条就会挂死,使用的时候要注意这个问题
错误重点:单修改时end不用加,
语法:
//单修改
<update id="updateBatch">
UPDATE 表 SET remark = CASE ID
<foreach collection="dataList" item="数据类型">
WHEN #{数据类型.id,jdbcType=BIGINT} THEN #{数据类型.remark,jdbcType=VARCHAR}
</foreach>
END
<where>
ID IN
<foreach collection="dataList" item="数据类型" separator="," open="(" close=")">
#{数据类型.id,jdbcType=BIGINT}
</foreach>
</where>
</update>
//多修改
<update id="updateBatch">
UPDATE 表 SET
remark1 = CASE ID
<foreach collection="dataList" item="数据类型">
WHEN #{数据类型.id,jdbcType=BIGINT} THEN #{数据类型.remark1,jdbcType=VARCHAR}
</foreach>
END,
remark2 = CASE ID
<foreach collection="dataList" item="数据类型">
WHEN #{数据类型.id,jdbcType=BIGINT} THEN #{数据类型.remark2,jdbcType=VARCHAR}
</foreach>
<where>
ID IN
<foreach collection="dataList" item="数据类型" separator="," open="(" close=")">
#{数据类型.id,jdbcType=BIGINT}
</foreach>
</where>
</update>
mybatis where 和 if else 的写法
where 中mybatis会自动忽略第一个and,所以在写if的时候所有语句都带上and即可,mybatis会处理后面跟的第一个and。
在mybatis的语法中,可以直接写if做判断处理。当需要写if else或者说switch时,就要用到
<choose>
<when test="">
...
</when>
//可以使用多个when达到switch的效果
<otherwise>
....
</otherwise>
//if else 使用when otherwise
</choose>
EXIST 和 IN的区别
在说in之前,要先解释一个定义
笛卡尔积:两个集合X和Y的笛卡尔积(Cartesian product),又称直积,表示为X×Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
IN:in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。
例子:select * from A where id in(select id from B)
先查分别把A,B表的数据,在遍历A表的id,对于每个A表的id,遍历B表去匹配,如果A表有N条,B表有M条,时间复杂度就是N的M次方,所以in()适合B表比A表数据小的情况。
EXIST:exist查询,只查询出A表的数据,对于A表的数据去做查询B匹配情况,true则留下false删除A的数据。
例子:select a.* from A a where exists(select 1 from B b where a.id=b.id)
先查A表数据,再遍历A表数据,去执行exist的内容select 1 from B b where a.id=b.id,如果返回true保留数据,返回false删除数据。:exists()适合B表比A表数据大的情况
PS: 如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
批量插入时的问题
- insert ignore into(若没有则插入,若存在则忽略)
- insert into … on duplicate key update(若没有则正常插入,若存在则更新)
- replace into(若没有则正常插入,若存在则先删除后插入)
详细解释
工作中遇到Spring的坑
cannot retry due to redirection, in streaming mode executing
这个错误是服务提供方请求被系统登录身法验证的shiro拦截,这个需要根据业务进行出来,可以将对应请求放开或使用特殊的校验身份的方式
no suitable HttpMessageConverter found for response type and content type
有可能是服务器返回数据格式问题引起的
我遇到的是 content type text/html ,因为接口调用有误,返回错误信息,无法解析成所需要的类型就会报这个错误。需要查看调用接口的参数或者查看服务提供方的错误信息等等,
feign.FeignException:status 500 readingXXX
我查看有的人是因为序列化的等等问题导致,而我再查看服务器返回信息时发现,Feign在发送GET请求时,不做处理的话会自动转化为POST请求,这时候服务提供方返回的错误信息就是500,解决方法如下:
@GetMapping +参数列表使用@RequestParam
生成流转MultipartFile通过feign发送到文件服务上传
这里面有很多坑,第一个是流转MultipartFile,主要思路就是把inputstream循环塞进outputStream,通过FileItem构造一个CommonsMultipartFile
FileItem fileItem = createFileItem(input, "能效分析报告.docx");
//CommonsMultipartFile是feign对multipartFile的封装,但是要FileItem类对象
MultipartFile mfile = new CommonsMultipartFile(fileItem);
public static FileItem createFileItem(InputStream inputstream, String fileName) {
String fieldName = "file";
FileItemFactory factory = new DiskFileItemFactory(16, null);
FileItem item = factory.createItem(fieldName, "text/plain", false, fileName);
int bytesRead = 0;
byte[] buffer = new byte[8192];
try {
OutputStream os = item.getOutputStream();
while ((bytesRead = inputstream.read(buffer, 0, 8192)) != -1) {
os.write(buffer, 0, bytesRead);
}
os.close();
inputstream.close();
} catch (IOException e) {
e.printStackTrace();
}
return item;
}
通过feign发送MultipartFile,需要配置一个config
@Configuration
@EnableFeignClients
public class MultipartSupportConfig {
@Autowired
private ObjectFactory<HttpMessageConverters> messageConverters;
@Bean
@Primary
@Scope("prototype")
public Encoder feignFormEncoder() {
return new SpringFormEncoder(new SpringEncoder(messageConverters));
}
}
在feignClient和接口上配置
@FeignClient(name =xxxx, path = "/file",configuration = MultipartSupportConfig.class)
@PostMapping(value = "/upload", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
拦截器中注入feign报nullpointer
拦截器是直接new生成,不通过bean管理生成,没有使用容器所以无法注入
解决方法:https://www.codeleading.com/article/36952584355/
@resource和@autowired的区别
@Autowired是由org.springframework.beans.factory.annotation.Autowired提供,换句话说就是由Spring提供;
@Autowired只按照byType 注入
@Autowired按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false。如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。
@Resource是由javax.annotation.Resource提供,即J2EE提供,需要JDK1.6及以上。
@Resource默认按byName自动注入,也提供按照byType 注入
- 如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
- 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
- 如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常
- 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配;
使用RestTemplate报错java.lang.IllegalStateException: No instances available for xxxx
RestTemplate配置中使用了@LoadBalanced//负载均衡注解,如果访问服务使用实际ip地址就会报错,使用所有的访问就必须以应用名访问,也就是生产者注册在Eureka中的ID
HTTP请求拦截和修改参数,过滤请求
业务场景:
1.需要拦截请求,修改请求体的参数/返回体的参数(无论是修改请求体还是返回体都是一样的修改请求)
2.且部分接口不需要修改(定制化)
针对业务场景,我们最直接的方法是先取出接口路径,判断是否是我们需要处理的接口,符合条件则修改请求体参数。我们首先采用拦截器去拦截请求并处理
//注册拦截器
@Configuration
@Slf4j
public class InterceptorsConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
//其他拦截器,需要取接口路径做权限处理
//....
//业务拦截器
registry.addInterceptor(new UserInterceptors()).addPathPatterns("/**").excludePathPatterns("/exclude");
}
}
@Slf4j
public class UserInterceptors implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws IOException {
HttpServletRequest requestWrapper=(HttpServletRequest) request;
String body = requestWrapper.getBody();
//业务处理
return true;
}
public UserInterceptors() {
}
}
这里运行后会出现第一个问题:接口会报错 stream close
原因:请求内所有参数都是只能取一次的,拦截器里取了body数据,接口就没办法读到请求数据
解决办法:解决参数只能读取一次的限制,自定义一个请求,把需要取的数据(body的数据)存在本地变量,重写getBody取变量值
@Slf4j
public class CustomHttpServletRequestWrapper extends HttpServletRequestWrapper {
// 保存request body的数据
private String body;
// 解析request的inputStream(即body)数据,转成字符串
public CustomHttpServletRequestWrapper(HttpServletRequest request) {
super(request);
StringBuilder stringBuilder = new StringBuilder();
BufferedReader bufferedReader = null;
InputStream inputStream = null;
try {
inputStream = request.getInputStream();
if (inputStream != null) {
bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
char[] charBuffer = new char[128];
int bytesRead = -1;
while ((bytesRead = bufferedReader.read(charBuffer)) > 0) {
stringBuilder.append(charBuffer, 0, bytesRead);
}
} else {
stringBuilder.append("");
}
} catch (IOException ex) {
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException e) {
log.error("error:", e);
}
}
}
body = stringBuilder.toString();
}
@Override
public ServletInputStream getInputStream() throws IOException {
final ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(body.getBytes());
ServletInputStream servletInputStream = new ServletInputStream() {
@Override
public boolean isFinished() {
return false;
}
@Override
public boolean isReady() {
return false;
}
@Override
public void setReadListener(ReadListener readListener) {
}
@Override
public int read() throws IOException {
return byteArrayInputStream.read();
}
};
return servletInputStream;
}
@Override
public BufferedReader getReader() throws IOException {
return new BufferedReader(new InputStreamReader(this.getInputStream()));
}
public String getBody() {
return this.body;
}
// 赋值给body字段
public void setBody(String body) {
this.body = body;
}
}
变更拦截器代码
@Slf4j
public class UserInterceptors implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws IOException {
CustomHttpServletRequestWrapper requestWrapper=(CustomHttpServletRequestWrapper) request;
String body = requestWrapper.getBody();
//业务处理
requestWrapper.setBody(body);
return true;
}
public UserInterceptors() {
}
}
这里就会遇到我们第二个问题:报错类型转换错误,无法转换
原因:读到的请求并不是HttpServletRequest 类型或者CustomHttpServletRequestWrapper 类型,而是一个abstract类,所以会报转化错误
坑点:一般情况下我们会想着把HttpServletRequest转化为CustomHttpServletRequestWrapper,调用构造方法,但是这样会新建一个对象,并不是原来的请求对象,在拦截器中无法修改请求对象地址,这样会造成修改的请求并不是到controller的请求,一样产生流关闭的问题。
解决办法:因为过滤器FIlter的特性,可以分发请求,改变请求对象,且运行顺序在拦截器之前。先把通过过滤器,把请求转化为自定义请求,再拦截器处理请求。且因为要过滤请求,需要取uri去判断,需要再自定义一个过滤请求类型,存储uri变量
/**
* @author zhentao
* @version 1.0
* @date 2022/12/12 12:36
* @description 转化请求到指定request,启动类@ServletComponentScan扫描webFilter
*/
@Slf4j
@WebFilter(filterName = "requestWrapperFilter", urlPatterns = "/*")
public class RequestWrapperFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
log.info("RequestWrapperFilter初始化...");
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
String path = req.getRequestURI().substring(req.getContextPath().length()).replaceAll("[/]+$", "");
List<String> excludeList = new ArrayList() {{
add("/exclude");
}};
if (excludeList.contains(path)) {
ServletRequest requestWrapper = new FileHttpServletRequestWrapper((HttpServletRequest) request);
chain.doFilter(requestWrapper, response);
} else {
ServletRequest requestWrapper = new CustomHttpServletRequestWrapper((HttpServletRequest) request);
chain.doFilter(requestWrapper, response);
}
}
@Override
public void destroy() {
log.info("RequestWrapperFilter 销毁...");
}
}
@Slf4j
public class FileHttpServletRequestWrapper extends HttpServletRequestWrapper {
// 保存request 的数据
private String contextPath;
private String requestURI;
public FileHttpServletRequestWrapper(HttpServletRequest request) {
super(request);
contextPath = request.getContextPath();
requestURI = request.getRequestURI();
}
@Override
public String getRequestURI() {
return this.requestURI;
}
@Override
public String getContextPath() {
return this.contextPath;
}
}
GIT代码管理
git操作,回滚本地commit
//回滚最近一次commit
git reset --hard head~1
//回滚至分支
git reset --hard origin/master
git pull
IDEA开发工具
debug启动慢
断点过多,取消无用断电
maven项目部署项目
使用maven project的clean和install功能生成对应的jar包,输出目录在target。否则会报错。
在jar目录下
java -jar xxx.jar
maven拉去jar包失败
Could not transfer artifact xxx from/to maven-default-http-blocker (http://0.0.0.0/): Blocked mirror for repositories:xxxx
原因因为是新装的idea,默认捆绑3.92版本的maven,maven在3.8以后不支持http的仓库配置,如需解决分为两种情况。仓库配置支持https的可以改成https,如不支持则需要降版本
maven构建子工程,依赖其他子工程构建失败
主要问题:子工程A引用子工程B,install时出现程序包B不存在,找不到依赖的子工程
已排除问题:
1、包路径是否正常
2、pom.xml是否引入
3、jar包是否冲突
解题思路:
1.需要引入子工程包B,首先子工程包B需要成功install,子工程需要成功install需要父工程先成功install,父工程因为子工程A构建失败,无法成功install,进入死循环。
解决方法:先解除子工程A与父工程的关联,使父工程成功install,进而子工程B成功install
2.解决子工程B install问题后,依旧找不到程序包,经查询后得知,我们使用的打包插件maven plugin(如下)打出来的包是不可被依赖,可被运行的。
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
需要添加以下配置,使install出来的jar包是可被依赖,不可被执行的
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<classifier>execute</classifier>
</configuration>
</plugin>
</plugins>
</build>
再次install子工程A成功,问题解决
配置构建war包
https://blog.csdn.net/qq_46093353/article/details/122678269
中间件
启动Nginx 出现 nginx: [emerg] unknown directive “锘?user” 错误
出现这种情况 一般是修改配置文件 nginx.conf 造成的 如果你修改文件后出现 那基本上就是这个原因 启动不了 重新打开 改为UTF-8 无BOM编码
服务器
上传本地大于4G的文件到服务器
https://blog.csdn.net/github_37271067/article/details/120525446
把自己的电脑当做一台网络服务器注册上网络,让线上服务器通过网络下载文件















 7855
7855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









