







背景介绍:
grep查找、awk分析、sed编辑。
文本处理,比如排查失败原因、求峰值,数据分析等。
简化文本处理和统计流程,敏捷开发。
数据来源:文本和标准输入。
输出结果:默认输出为标准输出,也可以重定向到文件中。
一:grep
描述:grep是一个命令行应用程序,用于搜索与正则表达式匹配的纯文本数据集。
特点:搜索工具、正则匹配、逐行处理
1)其主要参数如下:
-e 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内 容,格式为每一列的范本样式。
-I 忽略字符大小写的差别。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-v 反转查找。
-o 只输出文件中匹配到的部分。
2)应用如下:
数据集如下:
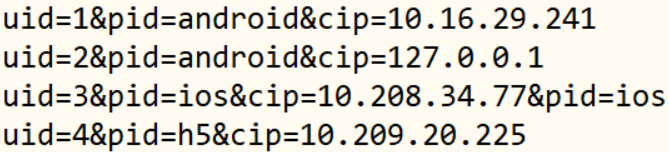
命令:cat inputData.txt | grep "&pid=ios“
grep "&pid=ios" inputData.txt
fgrep "&pid=ios" inputData.txt
意义:上述命令都表示过滤"&pid=ios"
结果:![]()
命令:grep --colour "&pid=ios" inputData.txt
意义:上述命令表示给"&pid=ios"加高亮,默认为红色
结果:![]()
为了效果更加明显,如下命令后都加 | grep --colour "&pid=[^&]\+" 来高亮
命令:fgrep -v "&pid=android" inputData.txt
意义:表示过滤除"&pid=android"以外的行
结果:
命令:fgrep -i "&pid=ANDroid" inputData.txt
意义:表示过滤时不区分大小写
结果:
命令:fgrep -r "android" ./
意义:表示逐级遍历该目录,查找"android"
命令:grep -e "&pid=ios" -e "&pid=h5" inputData.txt
意义:查找"&pid=ios"或者"&pid=h5"的行
结果:
命令:grep "&pid=[^&]\+" inputData.txt
grep -i "&pid=[a-z]\+" inputData.txt
意义:用正则过滤该字符串
结果: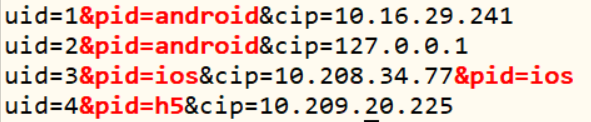
命令:grep -o "&pid=[^&]\+" inputData.txt | sort | uniq -c
意义:-o只输出匹配的部分,sort | uniq为去重,-c计数
结果: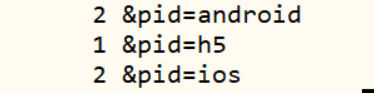
命令:egrep -o "&cip=([0-9]{1,3}[\.]){1}" inputData.txt
egrep -o "&cip=([0-9]{1,3}[\.]){3}" inputData.txt
egrep -o "&cip=([0-9]{1,3}[\.]){3}[0-9]{1,3}" inputData.txt
意义:最终目的为过滤IP,如上命令逐步分解
结果: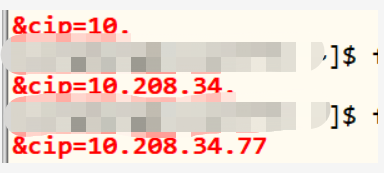
3)比较


使用egrep命令主要是因为它比grep命令更快,功能更全。 egrep命令按原样处理通配字符,并且不需要像grep那样进行转义。 这样可以减少替换这些字符的开销,同时模式匹配使得egrep比grep或fgrep更快。
4)其他
因为grep通过返回一个状态值来说明搜索的状态,
返回0:模板搜索成功;
返回1:搜索不成功;
返回2:搜索文件不存在。
我们利用这些返回值就可进行一些自动化的文本处理工作。
心得:fgrep key ./ 等价于 ag key
二:awk
描述:专门用于文本处理的编程语言,通常用作数据提取和生成报告。
特点:编程语言、分析统计、列处理
1)执行过程:
1.执行 BEGIN{action;…} 语句块,与文件无关
2. 从文件或者STDIN中读取一行,然后执行 pattern{action;…} 语句块,它逐行扫描文本内容并做相应的处理
3. 当读至输入流末尾时,执行 END{action;…} 语句块
2)使用场景:
BEGIN语句块:
一个可选的语句块,比如:变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中。
Pattern语句块:
也是可选的。 awk读取的每一行都会执行该语句块。如果没有提供pattern语句块,则默认执行{ print },即打印每一行。
END语句块:
一个可选语句块,比如:打印所有行的分析结果这类信息汇总都是在END语句块中完成。
3)主要应用
命令:cp -f `ldd ./main | awk '{print $3}' | grep -v '('` lib_test
意义:把main依赖的库文件拷贝到lib_test目录,ldd ./main | awk '{print $3}' 的意义为首先过滤出其对应的库文件.再进行拷贝
数据集:

命令:awk -F 'h=' '{print $2}‘ awk_data.txt
意义:以'h='为过滤符,打印第二列内容

命令:
awk -F ',' 'BEGIN{sum=0};{sum+=$3};END{print sum, sum/NR}' awk_data.txt
awk -F ',' 'BEGIN{sum=0};{sum+=$3}; END{print "sum="sum",avg="sum/NR}' awk_data.txt
意义:以逗号为分隔符,求第三列的和、平均值
结果: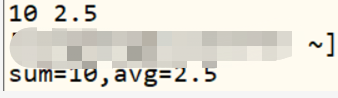
命令:
awk -F ',' '{if($3 > 2) {print $3}}' awk_data.txt | sort -rnk1
意义:如果第三列的值大于2,则打印.并排序
结果:![]()
命令:awk -F ',' '{a[$1","$2] += $3} END{for(i in a)print i,a[i]} ' awk_data.txt
意义:把第一列和第二列的值当作key,将对应第三列的值加和起来,并打印
结果:
三:sed编辑
描述:流编辑器是一个Unix应用程序,使用简单紧凑的命令解析和编辑文本。
特点:批量处理、正则表达、按行处理
1)主要参数:
d 删除,删除选择的行。
D 删除模板块的第一行。
s 替换指定字符
h 拷贝模板块的内容到内存中的缓冲区。
H 追加模板块的内容到内存中的缓冲区。
r file 从file中读行。
w file 写并追加模板块到file末尾。
W file 写并追加模板块的第一行到file末尾。
2)应用
数据集:

命令:sed 's/w=/weight=/' sed_data.txt
意义:替换每行第一个"w="为"weight="
结果: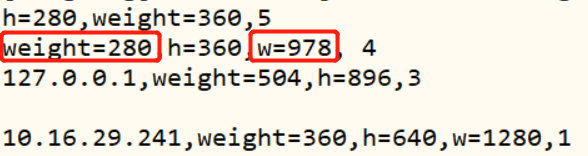
命令:sed 's/w=/weight=/g' sed_data.txt
意义:全文替换,将"w="替换为"weight="
结果: "
"
命令:sed '/^w=/'d sed_data.txt
意义:删除以"w="开头的行
结果:
命令:sed '/^$/d' sed_data.txt
意义:删除空行
结果:
命令:sed '3,$d;s/w=/weight=/' sed_data.txt
sed -e '3,$d' -e 's/w=/weight=/' sed_data.txt
意义:sed可顺序执行命令,可把上一句命令行的输出作为输入.如图上为删除第三行到最后一行,并把其余的行做替换操作
结果:
命令:sed '/h=/r test.txt' sed_data.txt
意义:把sed_data.txt中每一行有"h="的读入test.txt,匹配原文件内容的上一行.test.txt内容也是匹配到几次就复制几份
结果:
命令:sed '/h=/w test.txt' sed_data.txt
意义:把sed_data.txt中每一行有"h="的写入test.txt,会覆盖原test.txt文件内容
结果:
命令:sed '/^h=/a\this is a test line' sed_data.txt
意义:在开头为"h="的行下添加"this is a test line"
结果: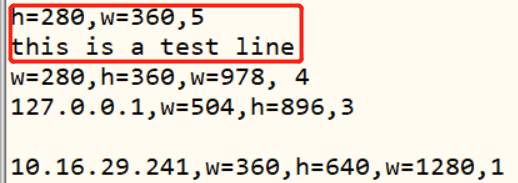















 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









