









简介
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object,普通的 Java对象)映射成数据库中的记录。
技术架构
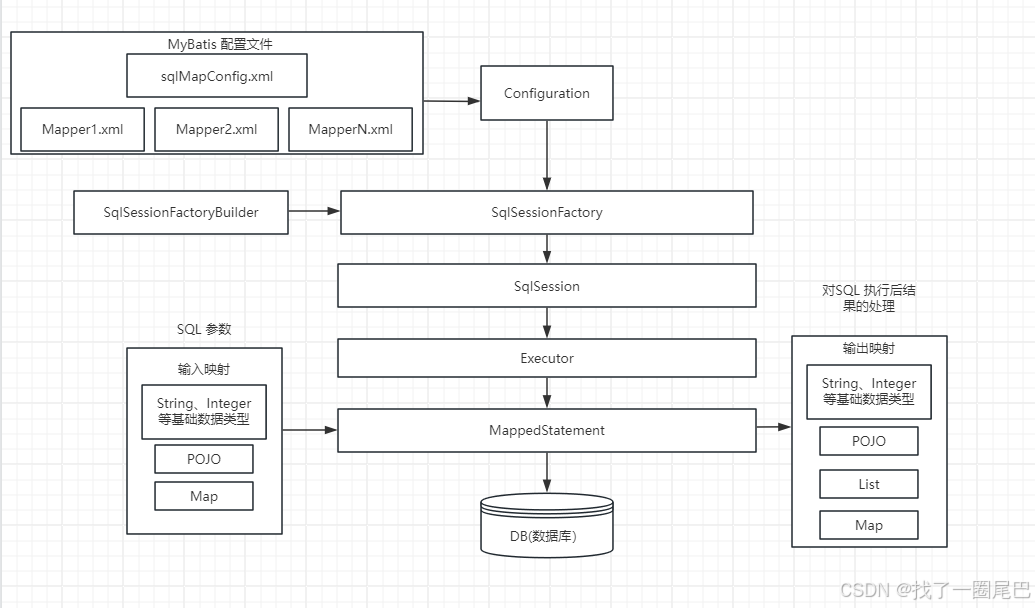
图1 MyBatis 核心类工作流图
Configuration
Configuration 是MyBatis框架中的配置中心,存储了MyBatis 运行时所需要的各种配置信息对象,其中主要包括:
- MapperRegistry:MapperRegistry类主要用于管理 MyBatis 中的映射器(Mapper)。它与 MyBatis 的接口式编程密切相关,在 MyBatis 中,通过接口来定义数据库操作方法,而MapperRegistry负责将这些接口和对应的 SQL 映射关系进行关联和管理。
- InterceptorChain:InterceptorChain是 MyBatis 插件机制中的重要组成部分。它用于管理和执行插件(Interceptor)。插件可以拦截 MyBatis 的核心操作,如 SQL 执行、参数处理、结果集处理等过程,从而实现一些自定义的功能,如分页、数据加密等。
- TypeHandlerRegistry:TypeHandlerRegistry用于管理类型处理器(Type Handler)。在 MyBatis 中,类型处理器负责将 Java 类型和 JDBC 类型进行相互转换。因为 Java 和数据库的数据类型不是完全一一对应的,例如,Java 中的String类型可能对应数据库中的VARCHAR、TEXT等类型,所以需要类型处理器来进行转换。
- TypeAliasRegistry:主要用于简化配置文件和代码中数据类型的引用,通过为 Java 类型指定别名,使得在配置文件和代码中可以使用别名代替冗长的全限定类名。
- LanguageDriverRegistry:LanguageDriverRegistry用于管理语言驱动(Language Driver)。MyBatis 支持多种语言来编写 SQL 语句或者其他相关的映射逻辑,语言驱动用于解析和处理这些语言。
- MappedStatement:MappedStatement是 MyBatis 中非常重要的一个类,它代表了一个完整的 SQL 映射语句。包括 SQL 语句本身、输入参数的映射(如参数类型、参数如何传递等)、输出结果的映射(如结果类型、结果如何封装等)以及其他相关的配置信息,如缓存配置、事务配置等。
- Cache:Cache是 MyBatis 中缓存相关的类。缓存用于提高数据访问效率,存储之前查询的结果,当再次执行相同的查询时,可以直接从缓存中获取数据,减少数据库查询次数。
- ResultMap:ResultMap用于定义查询结果如何映射到 Java 对象。在 MyBatis 中,由于数据库表结构和 Java 对象的结构可能不同,需要一种方式来明确这种映射关系,ResultMap就是为此而设计的。
- XMLStatementBuilder:XMLStatementBuilder主要用于构建MappedStatement对象,它是在解析 XML 格式的mapper.xml文件中的 SQL 映射语句时发挥作用。
- CacheRefResolver:CacheRefResolver用于处理缓存引用关系。在 MyBatis 中,一个mapper.xml文件或者 Mapper 接口可以引用其他mapper.xml文件或者 Mapper 接口的缓存,CacheRefResolver就是用于解析这种缓存引用关系的。
- ResultMapResolver:ResultMapResolver用于解析和构建ResultMap对象。在mapper.xml文件中,通过<resultMap>标签定义的结果映射关系需要被解析并转换成ResultMap对象,ResultMapResolver就是完成这个任务的。
- MethodResolver:MethodResolver主要用于处理 Mapper 接口方法与 SQL 映射关系之间的解析和关联。在 MyBatis 的接口式编程中,Mapper 接口方法需要与mapper.xml文件中的 SQL 映射语句或者接口上的注解式 SQL 映射建立联系,MethodResolver就是用于这个目的。
SqlSessionFactory
SqlSessionFactory 它是用于创建SqlSession对象的工厂,主要负责初始化 MyBatis 的配置信息,包括加载配置文件(如mybatis - config.xml)和映射文件(如Mapper.xml文件),构建SqlSession所需的环境。
在 MyBatis 中,配置文件包含了数据库连接信息(如数据源的配置、事务管理器的配置等)和 SQL 映射的相关信息。SqlSessionFactory会读取这些配置,解析数据库连接池的参数(如最大连接数、最小连接数等)、事务的隔离级别等重要信息。
SqlSessionFactory会读取这个配置文件,构建数据库连接相关的信息和 SQL 映射信息。它是线程安全的,在应用程序的整个生命周期内通常只需要创建一个实例即可。
SqlSession
SqlSession是 MyBatis 用于执行持久化操作的接口,它相当于一个数据库会话。通过SqlSession可以执行 SQL 语句,包括插入(insert)、删除(delete)、更新(update)和查询(select)操作等。它是 MyBatis 与数据库交互的主要通道。
Executor
在 MyBatis 中,Executor 主要负责执行 SQL 语句并处理结果集。它是 MyBatis 执行持久化操作的关键组件,封装了对数据库的访问逻辑,如查询、插入、更新和删除操作等。
查询操作
当执行一个查询操作时,例如selectList或selectOne方法(通过SqlSession调用),Executor会根据传入的参数(如 SQL 语句的标识、参数对象等)构建实际的 SQL 语句,然后发送给数据库执行。例如,在执行selectList时,Executor会获取 SQL 语句对应的MappedStatement(包含 SQL 语句的详细信息,如 SQL 文本、参数映射、结果映射等),将参数进行处理后,发送给数据库,最后接收数据库返回的结果集。
更新操作(插入、删除、修改)
对于插入、删除和修改操作,Executor的工作方式类似。以插入操作insert为例,Executor会获取要插入的对象的参数,根据对应的MappedStatement构建插入语句,将参数设置到语句中,然后发送给数据库执行插入操作,并根据数据库的返回信息(如影响的行数)来确定插入是否成功。
缓存处理
MyBatis 的缓存机制部分与Executor密切相关。Executor可以管理一级缓存(也称为本地缓存),一级缓存是在SqlSession级别维护的缓存。
当执行查询操作时,Executor会首先检查一级缓存中是否已经存在相同的查询结果。如果存在,则直接从缓存中获取数据,而无需再次发送 SQL 语句到数据库。例如,在一个SqlSession中多次查询相同的用户信息,第一次查询时,Executor会发送 SQL 语句到数据库获取结果并存储在一级缓存中,后续的查询如果参数相同,Executor就会直接从缓存中获取结果,提高了查询效率。
同时,Executor也会根据一定的规则(如缓存的刷新策略等)来维护缓存的有效性。当执行插入、更新或删除操作时,Executor会判断这些操作是否可能影响缓存中的数据,如果是,则会清除相关的缓存内容,以保证缓存数据与数据库中的数据一致性。
不同类型的 Executor
MyBatis 提供了多种Executor的实现,以满足不同的应用场景。
- SimpleExecutor:这是最基本的
Executor实现。每次执行 SQL 语句时,它都会创建一个新的Statement对象(如Statement、PreparedStatement等),然后发送 SQL 语句到数据库执行。它没有复杂的缓存和批处理机制,简单直接,适用于对性能要求不是特别高,且操作相对简单的场景。 - ReuseExecutor:它会重用已经创建的
Statement对象。在执行相同的 SQL 语句(根据 SQL 语句的文本等因素判断)时,会尝试复用之前创建的Statement,这样可以减少创建Statement对象的开销。不过,在实际应用中,需要注意Statement对象的状态管理,因为复用可能会导致一些潜在的问题,如参数设置的混乱等。 - BatchExecutor:主要用于批量操作。当需要执行多个相同类型的 SQL 语句(如批量插入、批量更新)时,
BatchExecutor可以将这些语句组合成一个批处理操作发送给数据库。这可以大大提高批量操作的效率,因为数据库可以在一次往返中处理多个语句,减少了网络开销和数据库的处理时间。不过,不是所有的数据库都对批处理操作有很好的支持,而且批处理的大小等因素也需要根据具体情况进行优化。
MappedStatement
MappedStatement它代表了一个完整的 SQL 映射语句。可以把它看作是对 SQL 操作(如查询、插入、更新、删除)从配置到执行的一个封装。它在 MyBatis 的配置解析和 SQL 执行过程中起到了承上启下的关键作用。
从配置角度看,它存储了从 MyBatis 的配置文件(如mapper.xml)或者基于接口的注解中解析出来的 SQL 语句相关的所有信息。从执行角度看,它为SqlSession提供了执行 SQL 操作所需的全部细节,使得SqlSession能够准确地构建PreparedStatement、设置参数、执行 SQL 并处理结果。
功能架构
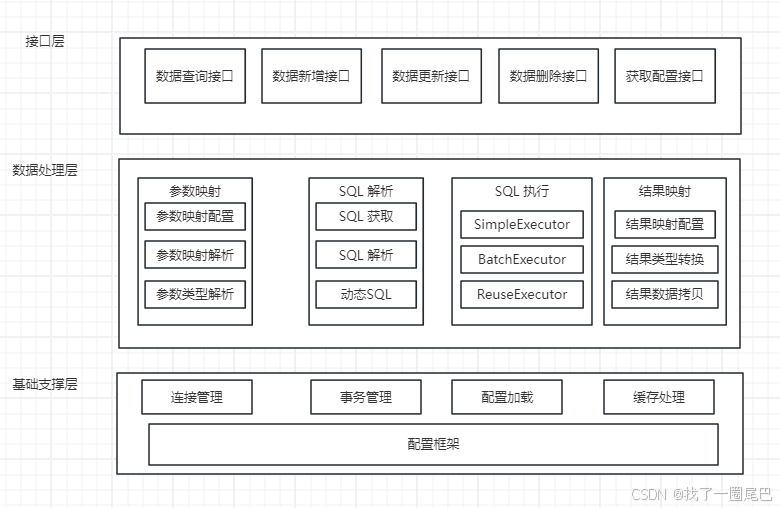
图2 Mybatis 功能分层架构图
- API接口层:提供给外部使用的接口API,开发人员通过这些本地API来操纵数据库。接口层一接收到调用请求就会调用数据处理层来完成具体的数据处理。
- 数据处理层:负责具体的SQL查找、SQL解析、SQL执行和执行结果映射处理等。它主要的目的是根据调用的请求完成一次数据库操作。
- 基础支撑层:负责最基础的功能支撑,包括连接管理、事务管理、配置加载和缓存处理,这些都是共用的东西,将他们抽取出来作为最基础的组件。为上层的数据处理层提供最基础的支撑。
优缺点
优点
- MyBatis 是免费且开源的。
- 与 JDBC 相比,减少了 50% 以上的代码量。
- MyBatis 是最简单的持久化框架,小巧并且简单易学。
- MyBatis 相当灵活,不会对应用程序或者数据库的现有设计强加任何影响,SQL 写在 XML 中,和程序逻辑代码分离,降低耦合度,便于同一管理和优化,提高了代码的可重用性。
- 提供 XML 标签,支持编写动态 SQL 语句。
- 提供映射标签,支持对象与数据库的 ORM 字段关系映射。
- 支持存储过程。MyBatis 以存储过程的形式封装 SQL,可以将业务逻辑保留在数据库之外,增强应用程序的可移植性、更易于部署和测试。
缺点
- 编写 SQL 语句工作量较大,对开发人员编写 SQL 语句的功底有一定要求。
- SQL 语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
MyBatis 参数配置
| 设置名 | 描述 | 有效值 | 默认值 |
| cacheEnabled | 全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。 | true | false | true |
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 属性来覆盖该项的开关状态。 | true | false | false |
| aggressiveLazyLoading | 开启时,任一方法的调用都会加载该对象的所有延迟加载属性。 否则,每个延迟加载属性会按需加载(参考 )。 | true | false | false (在 3.4.1 及之前的版本中默认为 true) |
| multipleResultSetsEnabled | Deprecated. This option has no effect. | true | false | true |
| useColumnLabel | 使用列标签代替列名。实际表现依赖于数据库驱动,具体可参考数据库驱动的相关文档,或通过对比测试来观察。 | true | false | true |
| useGeneratedKeys | 允许 JDBC 支持自动生成主键,需要数据库驱动支持。如果设置为 true,将强制使用自动生成主键。尽管一些数据库驱动不支持此特性,但仍可正常工作(如 Derby)。 | true | false | False |
| autoMappingBehavior | 指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示关闭自动映射;PARTIAL 只会自动映射没有定义嵌套结果映射的字段。 FULL 会自动映射任何复杂的结果集(无论是否嵌套)。 | NONE, PARTIAL, FULL | PARTIAL |
| autoMappingUnknownColumnBehavior | 指定发现自动映射目标未知列(或未知属性类型)的行为。
Note that there could be false-positives when `autoMappingBehavior` is set to `FULL`. | NONE, WARNING, FAILING | NONE |
| defaultExecutorType | 配置默认的执行器。SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(PreparedStatement); BATCH 执行器不仅重用语句还会执行批量更新。 | SIMPLE REUSE BATCH | SIMPLE |
| defaultStatementTimeout | 设置超时时间,它决定数据库驱动等待数据库响应的秒数。 | 任意正整数 | 未设置 (null) |
| defaultFetchSize | 为驱动的结果集获取数量(fetchSize)设置一个建议值。此参数只可以在查询设置中被覆盖。 | 任意正整数 | 未设置 (null) |
| defaultResultSetType | 指定语句默认的滚动策略。(新增于 3.5.2) | FORWARD_ONLY | SCROLL_SENSITIVE | SCROLL_INSENSITIVE | DEFAULT(等同于未设置) | 未设置 (null) |
| safeRowBoundsEnabled | 是否允许在嵌套语句中使用分页(RowBounds)。如果允许使用则设置为 false。 | true | false | False |
| safeResultHandlerEnabled | 是否允许在嵌套语句中使用结果处理器(ResultHandler)。如果允许使用则设置为 false。 | true | false | True |
| mapUnderscoreToCamelCase | 是否开启驼峰命名自动映射,即从经典数据库列名 A_COLUMN 映射到经典 Java 属性名 aColumn。 | true | false | False |
| localCacheScope | MyBatis 利用本地缓存机制(Local Cache)防止循环引用和加速重复的嵌套查询。 默认值为 SESSION,会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地缓存将仅用于执行语句,对相同 SqlSession 的不同查询将不会进行缓存。 | SESSION | STATEMENT | SESSION |
| jdbcTypeForNull | 当没有为参数指定特定的 JDBC 类型时,空值的默认 JDBC 类型。 某些数据库驱动需要指定列的 JDBC 类型,多数情况直接用一般类型即可,比如 NULL、VARCHAR 或 OTHER。 | JdbcType 常量,常用值:NULL、VARCHAR 或 OTHER。 | OTHER |
| lazyLoadTriggerMethods | 指定对象的哪些方法触发一次延迟加载。 | 用逗号分隔的方法列表。 | equals,clone,hashCode,toString |
| defaultScriptingLanguage | 指定动态 SQL 生成使用的默认脚本语言。 | 一个类型别名或全限定类名。 | org.apache.ibatis.scripting.xmltags.XMLLanguageDriver |
| defaultEnumTypeHandler | 指定 Enum 使用的默认 。(新增于 3.4.5) | 一个类型别名或全限定类名。 | org.apache.ibatis.type.EnumTypeHandler |
| callSettersOnNulls | 指定当结果集中值为 null 的时候是否调用映射对象的 setter(map 对象时为 put)方法,这在依赖于 Map.keySet() 或 null 值进行初始化时比较有用。注意基本类型(int、boolean 等)是不能设置成 null 的。 | true | false | false |
| returnInstanceForEmptyRow | 当返回行的所有列都是空时,MyBatis默认返回 。 当开启这个设置时,MyBatis会返回一个空实例。 请注意,它也适用于嵌套的结果集(如集合或关联)。(新增于 3.4.2) | true | false | false |
| logPrefix | 指定 MyBatis 增加到日志名称的前缀。 | 任何字符串 | 未设置 |
| logImpl | 指定 MyBatis 所用日志的具体实现,未指定时将自动查找。 | SLF4J | LOG4J(3.5.9 起废弃) | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING | 未设置 |
| proxyFactory | 指定 Mybatis 创建可延迟加载对象所用到的代理工具。 | CGLIB (3.5.10 起废弃) | JAVASSIST | JAVASSIST (MyBatis 3.3 以上) |
| vfsImpl | 指定 VFS 的实现 | 自定义 VFS 的实现的类全限定名,以逗号分隔。 | 未设置 |
| useActualParamName | 允许使用方法签名中的名称作为语句参数名称。 为了使用该特性,你的项目必须采用 Java 8 编译,并且加上 选项。(新增于 3.4.1) | true | false | true |
| configurationFactory | 指定一个提供 实例的类。 这个被返回的 Configuration 实例用来加载被反序列化对象的延迟加载属性值。 这个类必须包含一个签名为 的方法。(新增于 3.2.3) | 一个类型别名或完全限定类名。 | 未设置 |
| shrinkWhitespacesInSql | 从SQL中删除多余的空格字符。请注意,这也会影响SQL中的文字字符串。 (新增于 3.5.5) | true | false | false |
| defaultSqlProviderType | 指定一个拥有 provider 方法的 sql provider 类 (新增于 3.5.6). 这个类适用于指定 sql provider 注解上的 (或 ) 属性(当这些属性在注解中被忽略时)。 (e.g. ) | 类型别名或者全限定名 | 未设置 |
| nullableOnForEach | 为 'foreach' 标签的 'nullable' 属性指定默认值。(新增于 3.5.9) | true | false | false |
| argNameBasedConstructorAutoMapping | 当应用构造器自动映射时,参数名称被用来搜索要映射的列,而不再依赖列的顺序。(新增于 3.5.10) | true | false | false |
MyBatis 动态Sql 标签
MyBatis使用了基于强大的OGNL表达式来消除了大部分元素
<if>标签
<if>标签是 MyBatis 中最常用的动态 SQL 标签之一。它用于根据条件判断是否将包含的 SQL 片段包含在最终的 SQL 语句中。这种条件判断通常基于传入的参数值。
<select id="selectUsersByCondition" resultMap="UserResultMap">
SELECT * FROM users
<where>
<if test="username!= null">
AND username = #{username}
</if>
<if test="age!= null">
AND age = #{age}
</if>
</where>
</select><choose>、<when>和<otherwise>标签
这组标签用于实现多条件分支选择。<choose>标签作为父标签,内部包含多个<when>标签用于不同条件的判断,以及一个可选的<otherwise>标签用于处理前面所有条件都不满足的情况。
<select id="selectUsersByType" resultMap="UserResultMap">
SELECT * FROM users
<choose>
<when test="queryType == 'byName'">
WHERE username = #{username}
</when>
<when test="queryType == 'byAge'">
WHERE age = #{age}
</when>
<otherwise>
WHERE 1 = 1
</otherwise>
</choose>
</select><where>标签
<where>标签主要用于处理 SQL 语句中的WHERE子句。它会自动去除 SQL 语句开头的AND或OR关键字,并且如果所有的条件都不满足(即<where>标签内部的<if>等标签都没有添加 SQL 片段),<where>标签本身也不会添加WHERE关键字到 SQL 语句中。
<select id="selectUsersByCondition" resultMap="UserResultMap">
SELECT * FROM users
<where>
<if test="username!= null">
AND username = #{username}
</if>
<if test="age!= null">
AND age = #{age}
</if>
</where>
</select><foreach>标签
<foreach>标签用于循环遍历一个集合或数组,并将集合中的元素逐个添加到 SQL 语句中。它常用于IN子句或者批量插入等操作。
<select id="selectUsersByIdList" resultMap="UserResultMap">
SELECT * FROM users
WHERE id IN
<foreach collection="idList" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</select><insert id="batchInsertUsers">
INSERT INTO users (id, username, password)
VALUES
<foreach collection="userList" item="user" separator=",">
(#{user.id}, #{user.username}, #{user.password})
</foreach>
</insert><set>标签
<set>标签主要用于在UPDATE语句中动态设置需要更新的列。它会自动去除 SQL 语句最后多余的逗号,确保生成的UPDATE语句语法正确。
<update id="updateUser">
UPDATE users
<set>
<if test="username!= null">username = #{username},</if>
<if test="password!= null">password = #{password},</if>
</set>
WHERE id = #{id}
</update><trim>标签
<trim>标签用于自定义去除 SQL 语句中多余的关键字或空格。它可以通过prefix、suffix、prefixOverrides和suffixOverrides属性来灵活地控制 SQL 语句的开头、结尾以及需要去除的前缀和后缀内容。
<insert id="insertUser">
INSERT INTO users
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="id!= null">id,</if>
<if test="username!= null">username,</if>
<if test="password!= null">password</if>
</trim>
VALUES
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="id!= null">#{id},</if>
<if test="username!= null">#{username},</if>
<if test="password!= null">#{password}</if>
</trim>
</insert><script>标签
要在带注解的映射器接口类中使用动态 SQL,可以使用 script 元素。
@Update({"<script>",
"update Author",
" <set>",
" <if test='username != null'>username=#{username},</if>",
" <if test='password != null'>password=#{password},</if>",
" <if test='email != null'>email=#{email},</if>",
" <if test='bio != null'>bio=#{bio}</if>",
" </set>",
"where id=#{id}",
"</script>"})
void updateAuthorValues(Author author);<bind>标签
bind 元素允许你在 OGNL 表达式以外创建一个变量,并将其绑定到当前的上下文。
<select id="selectBlogsLike" resultType="Blog">
<bind name="pattern" value="'%' + _parameter.getTitle() + '%'" />
SELECT * FROM BLOG
WHERE title LIKE #{pattern}
</select>CDATA
CDATA(Character Data)是在 XML(可扩展标记语言)中的一个术语。它用于在 XML 文档中包含可能被解析器误解为标记的文本内容。 放在CDATA区中的内容,只会被xml解析器当作普通文本来处理。而不是被当成标签的一部分处理。
<![CDATA[ < ]]#{}占位符
在mybatis中占位符有两个,分别是 #{} 占位符 和 ${} 占位符:
#{}:相当于JDBC中的问号(?)占位符,是为SQL语句中的参数值进行占位,大部分情况下都是使用#{}占位符;并且当#{}占位符是为字符串或者日期类型的值进行占位时,在参数值传过来替换占位符的同时,会进行转义处理(在字符串或日期类型的值的两边加上单引号);- 在mapper文件中: select * from emp where name=#{name}
- 在程序执行时: select * from emp where name=?
- 参数:王海涛,将参数传入,替换占位符
- select * from emp where name=‘王海涛’;
${}:是为SQL片段(字符串)进行占位,将传过来的SQL片段直接拼接在 ${} 占位符所在的位置,不会进行任何的转义处理。(由于是直接将参数拼接在SQL语句中,因此可能会引发SQL注入攻击问题)。需要注意的是:使用 ${} 占位符为SQL语句中的片段占位时,即使只有一个占位符,需要传的也只有一个参数,也需要将参数先封装再传递。
多数据库支持
如果配置了 databaseIdProvider,你就可以在动态代码中使用名为 “_databaseId” 的变量来为不同的数据库构建特定的语句。
<insert id="insert">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
<if test="_databaseId == 'oracle'">
select seq_users.nextval from dual
</if>
<if test="_databaseId == 'db2'">
select nextval for seq_users from sysibm.sysdummy1"
</if>
</selectKey>
insert into users values (#{id}, #{name})
</insert>MyBatis 一、二级缓存
MyBatis 包含一个强大的事务查询缓存功能,该功能非常易于配置和自定义。MyBatis 3 缓存实现进行了大量更改,使其功能更强大且更易于配置。默认情况下,只启用本地会话缓存(一级缓存),仅用于在会话期间缓存数据。要启用全局二级缓存,只需在 SQL 映射文件中添加一行:
<cache/>这一条简单语句的效果如下:
- 映射语句文件中选择语句的所有结果都将被缓存。
- 映射语句文件中的所有插入,更新和删除语句都将刷新缓存。
- 缓存将使用最近最少使用 (LRU) 算法进行驱逐。
- 缓存不会按照任何基于时间的计划刷新(即没有刷新间隔)。
- 缓存将存储 1024 个对列表或对象的引用(无论查询方法返回什么)。
- 该缓存将被视为读/写缓存,这意味着检索到的对象不共享,并且可以由调用者安全地修改,而不会干扰其他调用者或线程的其他潜在修改。
您需要使用 @CacheNamespaceRef 注释引用缓存区域。所有这些属性都可以通过缓存元素的属性进行修改。例如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>- eviction的可配置项包括:
LRU– 最近最少使用:删除最长时间未使用的对象。FIFO– 先进先出:按照对象进入缓存的顺序删除对象。SOFT– 软引用:根据垃圾收集器状态和软引用规则删除对象。WEAK– 弱引用:根据垃圾收集器状态和弱引用规则更积极地删除对象。- 默认是 LRU。
- flushInterval:可以设置为任意正整数,并且应表示以毫秒为单位指定的合理时间量。默认未设置,因此不使用刷新间隔,并且仅通过调用语句来刷新缓存。
- size:可以设置为任意正整数,请记住缓存的对象的大小和环境的可用内存资源。默认值为 1024。
- readOnly: readOnly属性可以设置为 true 或 false。只读缓存将向所有调用者返回缓存对象的相同实例。因此不应修改此类对象。但这提供了显著的性能优势。读写缓存将返回缓存对象的副本(通过序列化)。这较慢,但更安全,因此默认值为 false。
缓存级别和范围
- 一级缓存:一级缓存是
SqlSession级别的缓存。它的作用范围是在同一个SqlSession内。当在一个SqlSession中执行多次相同的查询操作时,第一次查询后,结果会被缓存在这个SqlSession对应的一级缓存中。后续相同的查询,只要缓存没有失效,就可以直接从缓存中获取结果,而不需要再次向数据库发送查询请求。例如,在一个业务方法中使用同一个SqlSession进行两次相同用户信息的查询,第一次查询数据库后,第二次查询就会直接使用缓存中的数据。 - 二级缓存:二级缓存是
Mapper级别(命名空间级别)的缓存。它的范围比一级缓存更广,作用于整个Mapper(即一个接口对应的所有 SQL 操作)。当多个SqlSession访问相同Mapper中的相同查询操作时,它们可以共享二级缓存中的数据。比如,在一个 Web 应用程序中,不同的请求可能会创建不同的SqlSession,但如果它们都涉及到同一个Mapper的相同查询,就可以利用二级缓存来减少数据库查询次数。
缓存的生命周期
- 一级缓存:一级缓存的生命周期与
SqlSession一致。当SqlSession被打开时,一级缓存开始生效;当SqlSession被关闭后,一级缓存中的数据就会被清空。这意味着一级缓存的数据仅在一个SqlSession的生命周期内有效。例如,在一个事务处理过程中,如果使用一个SqlSession,那么在这个事务内的缓存数据在事务结束(SqlSession关闭)后就不再可用。 - 二级缓存:二级缓存的生命周期相对独立,只要应用程序在运行,并且缓存没有被清空或者过期,二级缓存中的数据就可以被不同的
SqlSession反复使用。它的生命周期通常跨越多个SqlSession的开启和关闭过程,使得缓存数据能够在更广泛的场景下发挥作用,提高查询效率。
缓存数据的一致性维护难度
- 一级缓存:一级缓存的数据一致性维护相对简单。因为它只在一个
SqlSession内有效,当在这个SqlSession中执行插入、更新或删除操作时,MyBatis 会自动清除相关的一级缓存内容。这样可以保证在同一个SqlSession中,缓存数据与数据库数据能够保持较好的一致性。 - 二级缓存:二级缓存的数据一致性维护相对复杂。由于它跨越多个
SqlSession,当一个SqlSession执行插入、更新或删除操作后,需要考虑如何通知其他可能使用二级缓存的SqlSession来更新或清除缓存数据。这通常需要开发人员在代码中或者通过配置适当的缓存刷新策略来确保二级缓存中的数据与数据库数据的一致性。例如,可以在执行更新操作的Mapper方法中手动清除二级缓存,或者使用 MyBatis 提供的缓存刷新机制来维护数据一致性。
MyBatis Cursor
MyBatis 中的Cursor<T> 是一个用于处理大型结果集的接口,它提供了一个游标(cursor)的方式来逐行遍历查询结果,而不是一次性将所有结果加载到内存中。这种方式特别适用于处理大量数据,因为它可以有效地减少内存消耗。通过使用 Cursor<T>,MyBatis 提供了一种内存高效的方式来处理大型数据集。
Cursor 的特点
- 流式查询:
Cursor<T>支持流式查询,允许 MyBatis 按需加载数据,而不是一次性加载整个结果集。 - 逐行处理:你可以使用
Cursor<T>逐行处理结果集,这对于处理大量数据非常有用。 - 懒加载:
Cursor<T>实现了懒加载,只有当实际需要数据时,才会从数据库中检索。 - 可关闭:
Cursor<T>是可关闭的,一旦完成操作,应该关闭游标以释放数据库连接。
如何使用 Cursor
要使用 Cursor<T>,首先需要在你的映射器接口(Mapper interface)中定义一个返回 Cursor<T> 的方法。以下是一个示例:
import org.apache.ibatis.cursor.Cursor;
import org.apache.ibatis.annotations.Select;
public interface UserMapper {
@Select("SELECT * FROM users")
Cursor<User> scanUsers();
} 在这个例子中,scanUsers() 方法将返回一个 Cursor<User>,你可以通过这个游标逐行遍历 User 对象。
使用 Cursor 遍历结果
以下是如何使用 Cursor<T> 来遍历查询结果的示例:
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
// 假设你已经有了一个 SqlSessionFactory 实例
SqlSessionFactory sqlSessionFactory = ...;
try (SqlSession session = sqlSessionFactory.openSession()) {
UserMapper userMapper = session.getMapper(UserMapper.class);
try (Cursor<User> cursor = userMapper.scanUsers()) {
for (User user : cursor) {
// 处理每一行数据
System.out.println(user.getUsername());
}
}
} 在这个例子中,我们首先通过 SqlSession 获取了 UserMapper 的代理对象,然后调用 scanUsers() 方法获取 Cursor<User>。
Cursor 使用注意事项
- 当使用
Cursor<T>时,确保你的 MyBatis 配置支持流式查询。这通常意味着需要设置defaultFetchSize为负数,以禁用 MyBatis 的预加载行为。 - 使用
Cursor<T>时,要确保在完成操作后关闭游标,以避免潜在的内存泄漏和数据库连接未释放的问题。
SQL 语句构建器
当我们有必要在Java 代码中,而不是使用XML的方式来构建SQL 语句的时候,我们可以使用MyBatis 提供的SQL 语句构件器来优化Java 代码中的SQL 语句表达式。以下是官方文档提供的一些基本示例:
private String selectPersonSql() {
return new SQL() {{
SELECT("P.ID, P.USERNAME, P.PASSWORD, P.FULL_NAME");
SELECT("P.LAST_NAME, P.CREATED_ON, P.UPDATED_ON");
FROM("PERSON P");
FROM("ACCOUNT A");
INNER_JOIN("DEPARTMENT D on D.ID = P.DEPARTMENT_ID");
INNER_JOIN("COMPANY C on D.COMPANY_ID = C.ID");
WHERE("P.ID = A.ID");
WHERE("P.FIRST_NAME like ?");
OR();
WHERE("P.LAST_NAME like ?");
GROUP_BY("P.ID");
HAVING("P.LAST_NAME like ?");
OR();
HAVING("P.FIRST_NAME like ?");
ORDER_BY("P.ID");
ORDER_BY("P.FULL_NAME");
}}.toString();
}
// 匿名内部类风格
public String deletePersonSql() {
return new SQL() {{
DELETE_FROM("PERSON");
WHERE("ID = #{id}");
}}.toString();
}
// Builder / Fluent 风格
public String insertPersonSql() {
String sql = new SQL()
.INSERT_INTO("PERSON")
.VALUES("ID, FIRST_NAME", "#{id}, #{firstName}")
.VALUES("LAST_NAME", "#{lastName}")
.toString();
return sql;
}
// 动态条件(注意参数需要使用 final 修饰,以便匿名内部类对它们进行访问)
public String selectPersonLike(final String id, final String firstName, final String lastName) {
return new SQL() {{
SELECT("P.ID, P.USERNAME, P.PASSWORD, P.FIRST_NAME, P.LAST_NAME");
FROM("PERSON P");
if (id != null) {
WHERE("P.ID like #{id}");
}
if (firstName != null) {
WHERE("P.FIRST_NAME like #{firstName}");
}
if (lastName != null) {
WHERE("P.LAST_NAME like #{lastName}");
}
ORDER_BY("P.LAST_NAME");
}}.toString();
}
public String deletePersonSql() {
return new SQL() {{
DELETE_FROM("PERSON");
WHERE("ID = #{id}");
}}.toString();
}
public String insertPersonSql() {
return new SQL() {{
INSERT_INTO("PERSON");
VALUES("ID, FIRST_NAME", "#{id}, #{firstName}");
VALUES("LAST_NAME", "#{lastName}");
}}.toString();
}
public String updatePersonSql() {
return new SQL() {{
UPDATE("PERSON");
SET("FIRST_NAME = #{firstName}");
WHERE("ID = #{id}");
}}.toString();
}从版本 3.4.2 开始,你可以像下面这样使用可变长度参数:
public String selectPersonSql() {
return new SQL()
.SELECT("P.ID", "A.USERNAME", "A.PASSWORD", "P.FULL_NAME", "D.DEPARTMENT_NAME", "C.COMPANY_NAME")
.FROM("PERSON P", "ACCOUNT A")
.INNER_JOIN("DEPARTMENT D on D.ID = P.DEPARTMENT_ID", "COMPANY C on D.COMPANY_ID = C.ID")
.WHERE("P.ID = A.ID", "P.FULL_NAME like #{name}")
.ORDER_BY("P.ID", "P.FULL_NAME")
.toString();
}
public String insertPersonSql() {
return new SQL()
.INSERT_INTO("PERSON")
.INTO_COLUMNS("ID", "FULL_NAME")
.INTO_VALUES("#{id}", "#{fullName}")
.toString();
}
public String updatePersonSql() {
return new SQL()
.UPDATE("PERSON")
.SET("FULL_NAME = #{fullName}", "DATE_OF_BIRTH = #{dateOfBirth}")
.WHERE("ID = #{id}")
.toString();
}从版本 3.5.2 开始,你可以像下面这样构建批量插入语句:
public String insertPersonsSql() {
// INSERT INTO PERSON (ID, FULL_NAME)
// VALUES (#{mainPerson.id}, #{mainPerson.fullName}) , (#{subPerson.id}, #{subPerson.fullName})
return new SQL()
.INSERT_INTO("PERSON")
.INTO_COLUMNS("ID", "FULL_NAME")
.INTO_VALUES("#{mainPerson.id}", "#{mainPerson.fullName}")
.ADD_ROW()
.INTO_VALUES("#{subPerson.id}", "#{subPerson.fullName}")
.toString();
}从版本 3.5.2 开始,你可以像下面这样构建限制返回结果数的 SELECT 语句,:
public String selectPersonsWithOffsetLimitSql() {
// SELECT id, name FROM PERSON
// LIMIT #{limit} OFFSET #{offset}
return new SQL()
.SELECT("id", "name")
.FROM("PERSON")
.LIMIT("#{limit}")
.OFFSET("#{offset}")
.toString();
}
public String selectPersonsWithFetchFirstSql() {
// SELECT id, name FROM PERSON
// OFFSET #{offset} ROWS FETCH FIRST #{limit} ROWS ONLY
return new SQL()
.SELECT("id", "name")
.FROM("PERSON")
.OFFSET_ROWS("#{offset}")
.FETCH_FIRST_ROWS_ONLY("#{limit}")
.toString();
}参考文献
官方文档: MyBatis 3 | 简介 – mybatis
豆包AI 大模型


















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











