







AI
AI 即人工智能(Artificial Intelligence)是通过计算机系统模拟人类智能行为的技术,涵盖学习、推理、决策等能力。
AI 的发展史
AI1.0
即人工智能的早期阶段,这个阶段的人工智能主要是基于规则的系统和早期的机器学习算法。
代表产品:
-
图像识别系统:基于CNN的图像分类和物理检测应用,如早期的面部识别技术。
-
语音识别助手:如早期版本的苹果Siri,利用语音识别和关键词匹配实现基本的语音交互。
-
推荐系统:如Amazon 的推荐算法,提供个性化内容推荐。
AI2.0
即人工智能技术的现代阶段,这个阶段以深度学习、大数据和云计算的兴起为标志。
代表产品:
-
ChatGPT:由OpenAI 开发的生成式预训练模型,能够进行自然语言对话和文本生成。
-
自动驾驶系统:如特斯拉的全自动驾驶(FSD),利用深度学习和大规模数据实现车辆的自动驾驶功能。
人工智能发展史
1900~2023 https://zhuanlan.zhihu.com/p/703419161
AGI
AGI,通用人工智能(Artificial General Intelligence),是 AI 领域的终极目标。与目前常见的只擅长特定领域任务的人工智能不同,AGI 旨在让机器具备像人类一样的通用智能,能够理解、学习并完成各种不同类型的任务,具备在复杂环境中灵活应对各种挑战的能力。虽然目前距离实现真正的 AGI 还有很长的路要走,但大模型的出现被视为朝着 AGI 迈进的重要一步。
Manus
Manus 是由中国 AI 公司 Monica.im 于 2025 年 3 月推出的一款现象级通用型 AI 智能体(Agent)产品,其核心突破在于实现了从 “思考” 到 “行动” 的全流程自动化执行能力,被称为 “全球首款通用型 AI Agent”。部分专家认为Manus 的出现意味着 AI 从 “对话交互” 正式迈向了 “人机协作” 模式,其展现了通用人工智能(AGI)的雏形。
我认为,Manus 或许只是昙花一现,其炒作成分大于本身具备的实力与价值。然而,不可否认的是,它的出现实实在在地推动了 AI Agent 朝着 AGI 模式发展的进程。如今,类似 OpenManus 这样的开源产品如雨后春笋般纷纷涌现。我们能够借助相关文档与源码,深入了解 Manus 的实现思路,进而拓宽自身的知识视野 。
-
Manus 操作指南: https://github.com/hodorwang/manus-guide
OpenManus
从技术角度来看,OpenManus 采用了经典的 ReAct 智能体架构设计模式,它能够基于当前状态进行决策,使得上下文和记忆管理变得简单便捷。该项目依赖于四个主要工具:
第一、PythonExecute 用于执行 Python 代码并与电脑系统互动;
第二、FileSaver 负责将文件保存到本地;
第三、BrowserUseTool 能够操控浏览器;
第四、GoogleSearch 则负责执行网络搜索任务
为了发挥项目的最大潜力,建议使用 Claude-3.5-Sonnet 或 Claude-3.7-Sonnet 大模型。
大模型
大模型,全称【语言大模型】,Large Language Model ,缩写 LLM。是一种基于机器学习和自然语言处理技术的模型,它通过对大量的文本数据进行训练,来学习服务人类语言理解和生成的能力。大模型一般具有千亿级以上参数、是通过大规模数据训练的深度神经网络模型,其核心优势在于泛化能力与知识涌现现象。
大模型测评
-
OpenCompass:OpenCompass司南
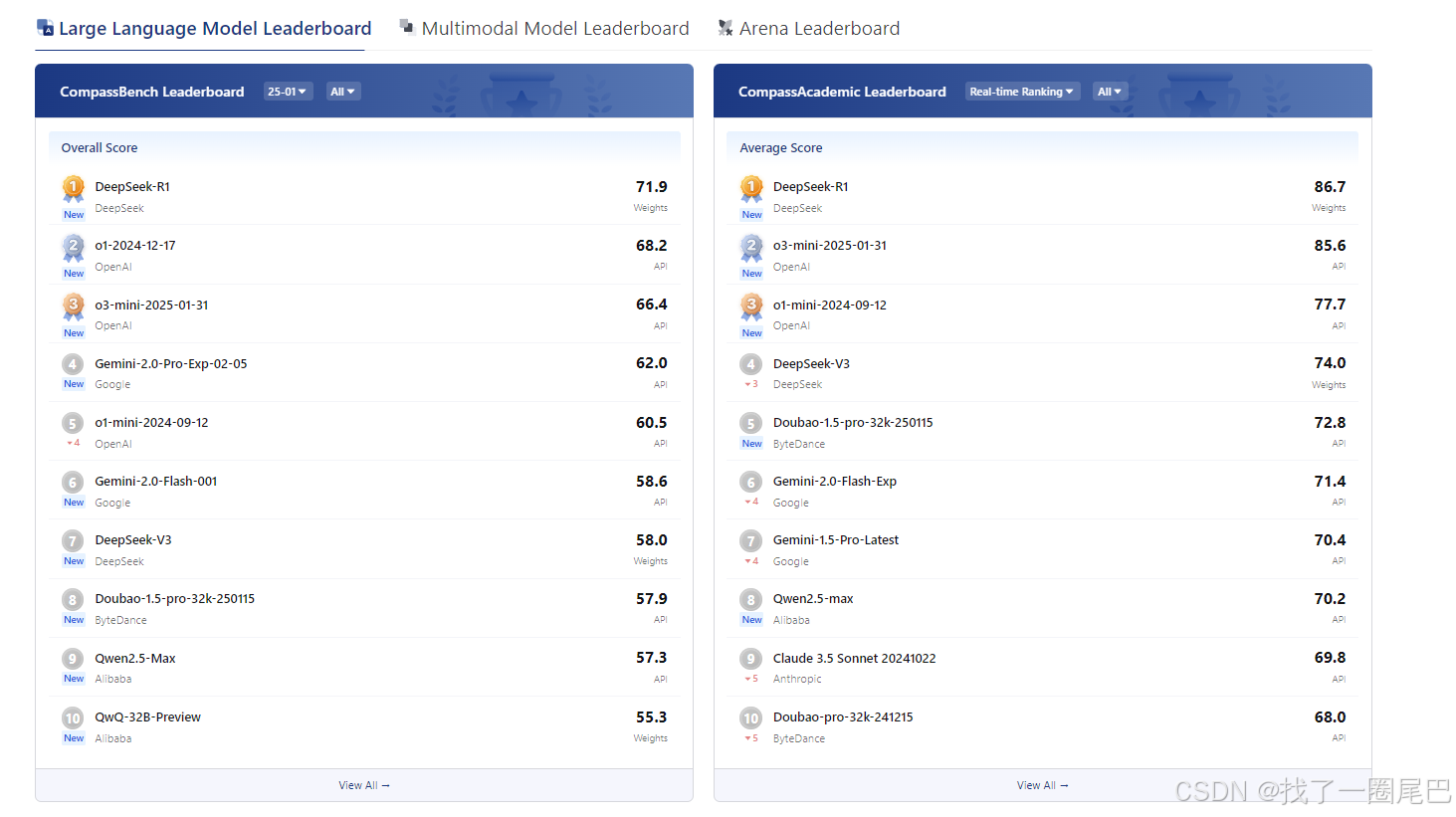
图1 2025-03-12 OpenCompass 大语言模型排行榜
基于大模型的对话产品
对于刚接触大模型的人而言,可能难以厘清大模型对话产品与大模型之间的差异。例如:ChatGPT 究竟是基于大模型的产品,还是大模型本身?DeepSeek 又属于基于大模型的产品,还是大模型呢?
实际上,ChatGPT 和 DeepSeek 均为基于大模型的对话产品。ChatGPT 的基座大模型是 GPT,而 DeepSeek 对话产品的基座大模型是 DeepSeek - R1 和 DeepSeek - V3 。
在很多情形下,人们会错误地认为自己所接触到的就是大模型本身,而事实上,人们最终接触到的是基座模型经过复杂的训练流程,以及对一些算法、架构进行优化后所衍生出的产品。
基座大模型
基座大模型一般是指通用的大预言模型,它们经过大规模数据的预训练,具备强大的语言理解和生成能力。
核心特征:
-
通用性:基于 Transformer 架构,在语言、图像等多模态领域实现基础能力储备
-
参数规模:典型参数范围从数十亿到万亿级(如 GPT-4 约 1.8 万亿参数)
-
训练范式:采用无监督预训练 + 监督微调(SFT)+ 强化学习优化(RLHF)的三级训练体系
代表模型:
-
GPT 系列(OpenAI):自然语言处理领域的奠基性模型
-
BERT(Google):开创双向 Transformer 预训练范式
-
DeepSeek-V3(深度求索):采用 MoE 混合专家架构的 6710 亿参数模型
推理模型
推理模型(Reasoning Model)是专注于逻辑推导、问题求解的专用模型,强调复杂情境下的决策能力。
核心特征:
-
架构优化:强化学习架构(如 DeepSeek-R1 的 RLHF 优化);思维链(CoT)技术增强多步推理能力
-
参数规模:通常小于基座模型(15 亿 - 700 亿参数)
-
训练目标:针对数学证明、代码生成等专项任务优化
代表模型:
-
Claude-3.7-Sonnet(Anthropic):采用 “一个模型,两种思考方式” 设计,支持实时响应(标准模式)与深度推理(扩展模式)自由切换。针对编码、前端开发等复杂任务优化,在 SWE-bench Verified 测试中通过率达 70.3%,研究生级推理准确率 78.2%。2025 年 2 月发布,是全球首款混合推理模型,标志着推理技术的突破。
-
OpenAI o3(OpenAI):采用 "私人思想链" 技术,可在响应前暂停并生成内部推理过程。支持低 / 中 / 高三级推理强度调节,性能与计算资源正相关。内置事实核查模块,降低常见逻辑错误率。基于强化学习优化(RLHF)的深度推理架构。引入 "审议式对齐" 安全机制,通过显式推理安全规范提升合规性。
-
DeepSeek-R1(深度求索):为复杂逻辑推理设计,采用 RLHF 强化学习训练,思维链长度可达数万字,在数学、代码等任务中性能媲美 OpenAI o1。已开源 660B 参数模型,并通过蒸馏技术推出 6 个小模型(如 32B、70B)。
基座模型与推理模型对比
| 维度 | 基座模型 | 推理模型 |
|---|---|---|
| 设计目标 | 通用能力泛化 | 专项推理优化 |
| 参数规模 | 超大规模(千亿级) | 中等规模(十亿级) |
| 训练数据 | 多领域通用语料 | 专业领域标注数据 |
| 典型应用 | 对话系统、内容生成 | 数学证明、决策支持 |
大模型的发展方向
主流方向由 BERT 转变为 GPT
BERT
-
BERT 是之前最流行的方向,几乎统治了所有NLP领域,并在自然语言理解类任务中发挥出色(例如文本分类、情感倾向判断等)。
-
模型架构:基于 Transformer 架构中的编码器部分,采用了多层双向 Transformer 编码器,能够同时考虑文本前后的上下文信息,捕捉文本中的长期依赖关系。
-
核心特点:
-
双向编码:与传统的单向语言模型不同,BERT 可以同时从正向和反向对文本进行编码,更好地理解文本的语义信息。
-
预训练任务:采用了两种无监督的预训练任务,即掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。MLM 任务随机掩盖输入文本中的一些单词,让模型预测被掩盖的单词;NSP 任务则是预测两个句子是否在文本中是相邻的,有助于模型理解句子之间的关系。
-
GPT
-
GPT 于2018 年开始陆续推出不同版本,在GPT3.0发布前,GPT 方向一直是弱于BERT 的,而GPT3.0后,也许是训练参数量的大幅提高,最终量变引起了质变,GPT3.0之后迅速超越了BERT ,成为LLM 模型的主流。
-
模型架构:基于 Transformer 架构中的解码器部分,最初的 GPT 采用了多层单向 Transformer 解码器,从左到右或从右到左地生成文本。后续版本在架构上有所改进和扩展。
-
核心特点:
-
生成式能力:以生成自然语言文本为主要目标,能够根据给定的上下文生成连贯、合理的文本内容。
-
无监督预训练:通过在大规模文本数据上进行无监督预训练,学习语言的统计规律和语义信息。预训练过程中主要采用了语言建模任务,即根据前面的文本预测下一个单词或短语。
-
BERT 和GPT的区别

GPT -GPT-4 的演进
-
GPT-1
-
发布时间: 2018年
-
模型概述: GPT-1是由OpenAI开发的⾸个GPT模型,基于Transformer架构。 它标志着使⽤⼤规模预训练模型在⾃然语⾔处理领域的⼀个重要转变。该模型通过⽆监督学习从⼤量⽂本中预训练语⾔模型,然后通过有监督学习进⾏特定 任务的微调。
-
关键特点: 该模型展示了通过预训练和微调相结合的⽅法,可以在多个⾃然语⾔理解任务上实现显著的性能提升。
-
-
GPT-2
-
发布时间: 2019年
-
模型概述: GPT-2在GPT-1的基础上显著扩展了模型⼤⼩和训练数据。具体来说,GPT-2使⽤了1.5亿个模型参数,远多于GPT-1的参数数量。
-
关键特点: GPT-2显示了出⾊的语⾔⽣成能⼒,能够产⽣连贯和引⼈⼊胜的⽂本段落。此外,OpenAI最初由于担⼼潜在的滥⽤⻛险,选择了不完全开放模型的访问。
-
-
GPT-3
-
发布时间: 2020年
-
模型概述: GPT-3是⼀个进⼀步扩⼤的模型,拥有1750亿个参数。这⼀巨⼤的扩展使GPT-3成为当时最⼤的语⾔模型之⼀。
-
关键特点: GPT-3的性能在多个⾃然语⾔处理任务上表现出⾊,包括翻译、问答和摘要等。GPT-3特别引⼊了“few-shot learning”,即模型能够在极少量的示例指导下快速适应新任务。
-
-
GPT-3.5与InstructGPT
-
发布时间:2022年
-
核⼼突破:引⼊⼈类反馈强化学习(RLHF),优化指令跟随能⼒。
-
技术细节: 基于GPT-3微调,结合⼈类标注数据调整输出偏好。 减少有害内容⽣成,提升对⽤户意图的理解。
-
-
GPT-4
-
发布时间: 2023年
-
模型概述: GPT-4进⼀步增强了模型的复杂性和多样性,包括改进的训练技术和更⼴泛的数据集。
-
关键特点: GPT-4在处理复杂的⽂本理解和⽣成任务时表现得更加精准,同时在逻辑推理和维持上下⽂连贯性⽅⾯也有显著改进。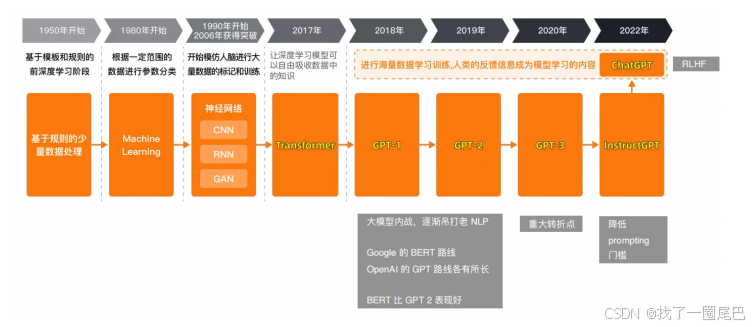
图2 GPT 发展历程
参数提高
GPT-3 之所以能超越 BERT,成为大语言模型(LLM)领域的主流,一个关键原因就在于参数规模带来的巨大变化。GPT-2 仅有 1.5 亿参数,而 GPT-3 的参数猛增到 1750 亿,这种量变在大模型领域引发了质变,充分证明了训练参数的规模对基座大模型性能起着基础性的决定作用。
然而,参数数量的攀升也带来了高昂的代价。随着参数量增加,训练成本大幅提升。例如,GPT-4 参数量高达 1.8 万亿,单次训练成本飙升至 6300 万美元。特斯拉的 Grok 3 同样如此,它依托由 10 万块英伟达 H100 GPU(后续扩展至 20 万块)构建的 Colossus 超级计算机进行训练,这背后所需的资源与成本可想而知。
所以一般情况下我们会认为参数量越大的模型效果越好,但这并不是绝对的,DeepSeek的横空出世就挑战了这一认知。
deepSeek 的出现,降本增效
2025 年春节期间,DeepSeek 的出现犹如一颗重磅炸弹,在国内掀起了大模型探索与使用的热潮。以大模型为基础的对话产品也借此机会,逐渐走进大众视野,广为人知。一时间,国内众多厂家纷纷蜂拥接入 DeepSeek,并大力宣传。实际上,不只是国内,国外的英伟达、微软等大厂也都接入了 DeepSeek。那么,DeepSeek 究竟有何独特魅力呢?
在我看来,DeepSeek 能够火爆出圈,最大的魅力在于它是开源的,但其性能却丝毫不逊色于那些顶尖的闭源大模型。在 OpenCompass 排行榜上,DeepSeek - R1 至今仍在大语言模型排行榜中独占鳌头。另一个关键因素是,DeepSeek 大幅降低了使用成本和训练成本。这就意味着,许多小厂商即便没有大量资金投入,也能够尝试涉足大模型领域,开展应用开发等业务。
小企业大模型落地策略
对于小企业而言,我们由于资金有限,可能不会投入大量的资金去部署一个大参数量的本地模型。如果公司要求我们部署一个本地的大模型,我一般会选择 14-32B 左右的开源模型,需要公司投资大概10万左右。目前我比较靠谱的模型包括两个一个是DeepSeek32B,还有一个是阿里的QwQ32B。在部署本地大模型时,我们一定要注意让大模型充分利用GPU 的资源,后续我会有专门的一篇文章探讨本地大模型的交互加速策略。
我认为基于顶尖大模型蒸馏的模型是小企业应该选择的,后续我们也可以使用行业领域数据集再对模型进行微调等操作,让大模型更符合专业领域的业务需求。
RAG方案则是目前更广泛的大模型落地的策略,通过RAG ,我们可以有效减少大模型的幻觉问题,同时RAG 方案的成本要比大模型微调的成本低得多,所以探索一条适合企业的RAG 架构是小企业目前大力推进的工作。
对于资金有限的小企业来说,通常不会投入大量资金去部署一个参数量巨大的本地模型。如果公司要求部署本地大模型,我一般会挑选参数在 14B 至 32B 左右的开源模型,这大概需要公司投资 10 万元左右。我认为市面上目前比较靠谱的开源模型有两个,一个是 DeepSeek32B,另一个是阿里的 Qwen32B。在部署本地大模型时,务必让大模型充分利用 GPU 资源,后续我会专门写一篇文章,探讨本地大模型的交互加速策略。
我觉得,基于顶尖大模型蒸馏得到的模型,比较适合小企业选择。后续还可以利用行业领域的数据集对模型进行微调等操作,使大模型能更好地契合专业领域的业务需求。
而 RAG 方案则是目前应用更为广泛的大模型落地策略。通过 RAG,能够有效减少大模型的幻觉问题,而且 RAG 方案的成本比大模型微调要低得多。所以,探索一条适合企业自身的 RAG 架构,是当下小企业应大力推进的工作。
大模型的训练路径

图3 大模型的训练路径
大模型的训练整体上分为三个阶段:预训练、SFT(监督微调)以及RLHF(基于人类反馈的强化学习)
-
预训练(Pre-training):预训练的过程类似于从婴⼉成⻓为中学⽣的阶段,在这个阶段我们会学习各种各样的知识,我们的语⾔习惯、知识体系等重要部分都会形成;对于⼤模型来说,在这个阶段它会学习各种不同种类的语料,学习到语⾔的统计规律和⼀般知识。
-
监督微调(SFT,Supervised Fine Tuning):SFT的过程类似于从中学⽣成⻓为⼤学⽣的阶段,在这个阶段我们会学习到专业知识,⽐如⾦融、法律等领域,我们的头脑会更专注于特定领域。对于⼤模型来说,在这个阶段它可以学习各种⼈类的对话语料,甚⾄是⾮常专业的垂直领域知识,在监督微调过程之后,它可以按照⼈类的意图去回答专业领域的问题。
-
基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback):RLHF的过程类似于从⼤学⽣步⼊职场的阶段,在这个阶段我们会开始进⾏⼯作,但是我们的⼯作可能会受到领导和客户的表扬,也有可能会受到批评,我们会根据反馈调整⾃⼰的⼯作⽅法,争取在职场获得更多的正⾯反馈。对于⼤模型来说,在这个阶段它会针对同⼀问题进⾏多次回答,⼈类会对这些回答打分,⼤模型会在此阶段学习到如何输出分数最⾼的回答,使得回答更符合⼈类的偏好。
通俗的大模型工作原理
-
大模型阅读了人类曾说过的所有的话,这就是机器学习,这个过程叫训练。
-
把一串token后面跟着的不同token 的概率记录下来,记下的就是参数,也叫权重。
-
当我们给它生成若干token,大模型就能算出概率最高的下一个token 是什么。这就是生成,也叫推理。
-
用生成的token,再加上下文,就能继续生成下一个token。以此类推,生成更多文字
大模型推荐
-
大语言基座模型:DeepSeek-V3、QWQ 32B
-
推理模型:DeepSeek-R1
-
代码编程模型:Claude-3.7-Sonnet
-
向量模型:text-embedding-3-small,text-embedding-3-large(OpenAI)
-
多模态:Qwen2.5-VL-72B
基础概念列表
deepseek满血 671B 中的 B代表什么?
B 表示十亿(Billion),671B 即 6710 亿参数。参数规模是衡量模型复杂度的核心指标之一。
Token
大语言模型中,Token是模型进行语言处理的基本信息单元,它可以是一个字,一个词甚至是一个短语句子。Token 并不是一成不变的,在不同的上下文中,它会有不同的划分粒度。
-
Tokenizer:https://platform.openai.com/tokenizer

从官方文档中我们可以看到每个模型都有一个Max Tokens的参数,这个参数的意思就是在一次会话中,模型能基于整个上下文记忆的最大Token 数量,这个上下文既包含了我们的输入,也包含了我们的输出。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











