






目录
三、进行 nc 文件读取,并生成不同类型降雨量csv、tif 栅格
一、 降雨 nc 数据下载
1. 登录网址(截至到20240712仅有2024年1月的降雨量)
https://www.ncei.noaa.gov/products/climate-data-records/precipitation-cmorph

2. 选择对应时间分辨率
8km×8km (30 min), 0.25°×0.25° (hourly, daily)(覆盖全球60°S-60°N))

--------- 这里以天为例:

3. 选择对应时间 nc 下载

二、 使用 python 批量下载
基于https://blog.csdn.net/weixin_45135078/article/details/138766135修改
1. 代码功能
修改下面的参数,可以进行不同年份和月份的降雨量nc文件下载:
output_path = '.\\' # 文件存放路径
time_kind = 3 # daily,下载的降雨量时间分辨率
start_year = 2023 # 开始年
end_year = 2024 # 结束年
get_rain_nc_from_cmorph(output_path, time_kind, start_year, end_year)
# start_month = 1 # 开始月,默认为1
# end_month = 2 # 结束月,默认12
# get_rain_nc_from_cmorph(output_path, time_kind, start_year, end_year, start_month, end_month)
2. 代码内容
get_rain_nc_from_cmorph.py
# -*- coding: utf-8 -*-
import os
import calendar
import requests
from bs4 import BeautifulSoup
import concurrent.futures
# 降雨量数据时空分辨率:8km×8km(30 min), 0.25°×0.25° (hourly, daily)(覆盖全球60°S - 60°N))
def download_file(out_fl_path, url, year, month, day):
if day != '':
download_url = url + str(year) + '/' + f"{month:02d}/" + f"{day:02d}/"
savePath = out_fl_path + str(year) + '/' + f"{month:02d}/" + f"{day:02d}/"
else:
download_url = url + str(year) + '/' + f"{month:02d}/"
savePath = out_fl_path + str(year) + '/' + f"{month:02d}/"
# print(download_url)
response = requests.get(download_url)
soup = BeautifulSoup(response.text, 'html.parser')
if not os.path.exists(savePath):
os.makedirs(savePath)
for link in soup.select('a[href$=".nc"]'):
name = link['href']
nc = requests.get(download_url + name)
with open(os.path.join(savePath, name), 'wb') as file:
file.write(nc.content)
print(name, '下载完成')
def get_rain_nc_from_cmorph(out_fl_path, time_resolution, year_start, year_end, month_start=1, month_end=12):
url_pre = 'https://www.ncei.noaa.gov/data/cmorph-high-resolution-global-precipitation-estimates/access/'
url = ''
if time_resolution == 1: # 30min
url = url_pre + '30min/8km/'
elif time_resolution == 2: # hourly
url = url_pre + 'hourly/0.25deg/'
elif time_resolution == 3: # daily
url = url_pre + 'daily/0.25deg/'
if url.split('/')[-3] == 'daily':
day = ''
with concurrent.futures.ThreadPoolExecutor(max_workers=12) as exe_code:
future_url = {exe_code.submit(download_file, out_fl_path, url, year, month, day): (year, month, day) for year
in range(year_start, year_end + 1) for month in range(month_start, month_end+1)}
else:
with concurrent.futures.ThreadPoolExecutor(max_workers=12) as exe_code:
future_url = {exe_code.submit(download_file, out_fl_path, url, year, month, day): (year, month, day) for year
in range(year_start, year_end + 1) for month in range(month_start, month_end+1) for day in
range(1, calendar.monthrange(year, month)[1] + 1)}
if __name__ == '__main__':
output_path = '.\\'
time_kind = 3 # daily
start_year = 2023 # 开始年
end_year = 2024 # 结束年
get_rain_nc_from_cmorph(output_path, time_kind, start_year, end_year)
# start_month = 1 # 开始月,默认为1
# end_month = 2 # 结束月,默认12
# get_rain_nc_from_cmorph(output_path, time_kind, start_year, end_year, start_month, end_month)三、进行 nc 文件读取,并生成不同类型降雨量csv、tif 栅格
1. 代码功能
将由get_rain_nc_from_cmorph.py代码生成的降雨量nc文件批量转为csv和tif文件,包括日均降雨量、月均降雨量、年均降雨量、多年累计降雨量等。
该代码可以和get_rain_nc_from_cmorph.py合并
input_path = "D:\\...\\降雨量数据获取_2\\" # get_rain_nc_from_cmorph.py代码的路径
time_kind = 3 # daily,下载的降雨量时间分辨率
start_year = 2023 # 开始年
end_year = 2024 # 结束年
start_month = 1 # 开始月,默认为1
end_month = 2 # 结束月,默认12
tran_csv = 0 # 原始文件转csv(0. 默认不转; 1. 转)
tran_tif = 1 # 转tif(0. 默认不转; 1. 转)
read_nc_to_csv_batch(input_path, time_kind, start_year, end_year, start_month, end_month, tran_csv, tran_tif)
2. 实现效果
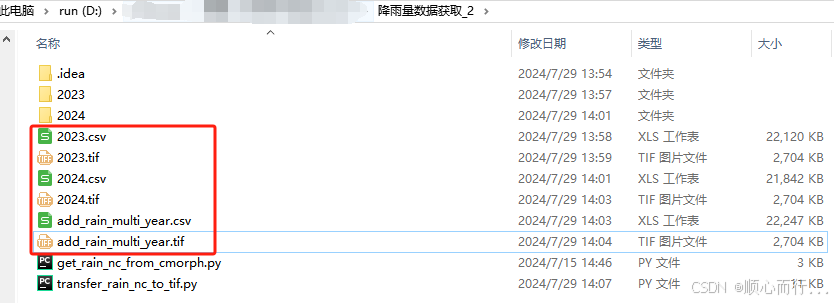
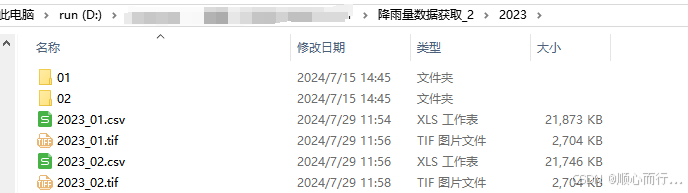
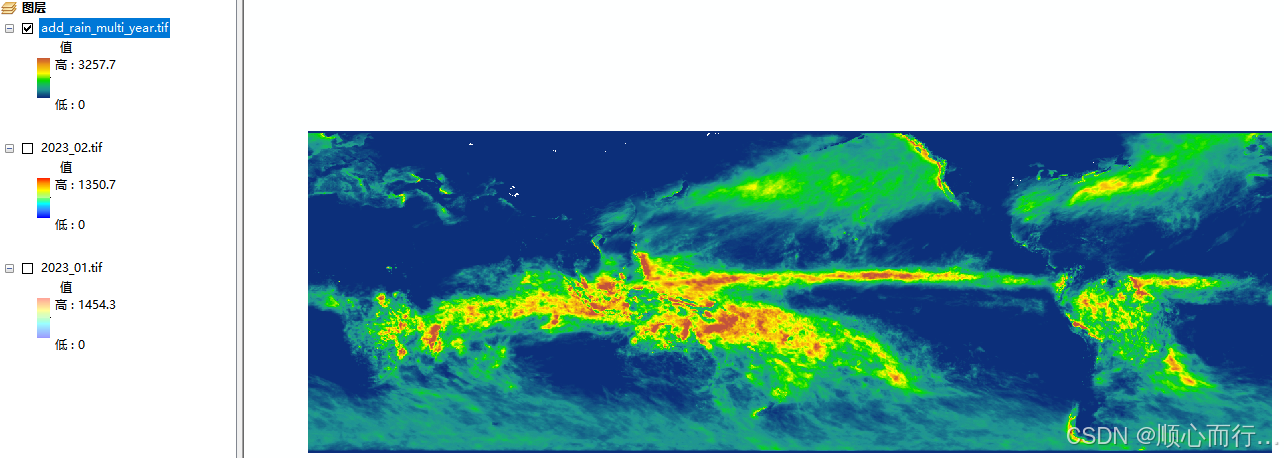
3. 代码内容
transfer_rain_nc_to_tif.py
from netCDF4 import Dataset
import os
import numpy as np
import pandas as pd
import calendar
from osgeo import gdal
def nc_to_csv(input_fl_nm, output_fl_nm):
# 打开netCDF文件
# input_fl_nm = 'CMORPH_V1.0_ADJ_0.25deg-DLY_00Z_20230205.nc'
nc_file = Dataset(input_fl_nm, 'r')
# 获取经度和纬度数据
longitudes = nc_file.variables['lon'][:]
latitudes = nc_file.variables['lat'][:]
rainfall = nc_file.variables['cmorph'][:] # 1440x480的二维数组
# 生成经度和纬度的格网
lons, lats = np.meshgrid(longitudes, latitudes)
# 准备数据列表,每个元素是一个包含经度、纬度和降雨量的元组
data = list(zip(lons.flatten(), lats.flatten(), rainfall.flatten()))
# 创建DataFrame
df = pd.DataFrame(data, columns=['经度', '纬度', '降雨量'])
# 保存为CSV文件
# output_fl_nm = 'output.csv'
df.to_csv(output_fl_nm, index=False)
# 关闭netCDF文件
nc_file.close()
def cal_add_nc(input_fl_path, output_fl_nm):
nc_fls = os.listdir(input_fl_path)
nc_fl_lts = filter(lambda filename: filename[-3:] == '.nc', nc_fls)
nc_fl_lts = list(nc_fl_lts)
# print(nc_fl_lts)
if nc_fl_lts:
nc_fl_one = nc_fl_lts[0]
os.chdir(input_fl_path)
nc_fl = Dataset(nc_fl_one, 'r')
# 获取经度和纬度数据
longitudes = nc_fl.variables['lon'][:]
latitudes = nc_fl.variables['lat'][:]
rain_add = np.zeros((480, 1440))
for nc_fl_lt in nc_fl_lts:
# 打开NetCDF文件
nc_data = Dataset(nc_fl_lt, 'r')
# 打印所有变量名
# var_nms = []
# for var_nm in nc_data.variables:
# var_nms.append(var_nm)
# print(var_nms)
# 读取变量
rain_var = nc_data.variables['cmorph']
# print(rain_var)
# time_var = nc_data.variables['time']
# print(time_var)
# 读取整个变量数据
rain_data = rain_var[:][0]
rain_add = rain_add + rain_data
# print(rain_data.shape)
rainfall_add = rain_add[:]
# 生成经度和纬度的格网
lons, lats = np.meshgrid(longitudes, latitudes)
# 准备数据列表,每个元素是一个包含经度、纬度和降雨量的元组
data = list(zip(lons.flatten(), lats.flatten(), rainfall_add.flatten()))
# 创建DataFrame
df = pd.DataFrame(data, columns=['经度', '纬度', '降雨量'])
# 保存为CSV文件
df.to_csv(output_fl_nm, index=False)
# 关闭netCDF文件
nc_fl.close()
def cal_add_csv(input_fl_path, output_fl_nm):
# 获取所有CSV文件名
csv_fls = [f for f in os.listdir(input_fl_path) if f.endswith('.csv')]
csv_fl_lts = csv_fls # 直接使用列表推导得到的文件名列表
rainfall_add = np.zeros((480*1440,), dtype=float) # 初始化降雨量累加数组
# 读取第一个CSV文件的经度和纬度数据
csv_one_data = pd.read_csv(os.path.join(input_fl_path, csv_fl_lts[0]), low_memory=False)
longitude = csv_one_data['经度'].values
latitude = csv_one_data['纬度'].values
for csv_fl_lt in csv_fl_lts:
csv_data = pd.read_csv(os.path.join(input_fl_path, csv_fl_lt))
# 累加降雨量数据
rainfall_add += pd.to_numeric(csv_data.iloc[:, -1], errors='coerce').values
# 创建包含经度、纬度和降雨量总和的新DataFrame
combined_df = pd.DataFrame({
'经度': longitude,
'纬度': latitude,
'降雨量': rainfall_add
})
# 将结果保存到新的CSV文件中
combined_df.to_csv(output_fl_nm, index=False)
def csv_to_tif(csv_path, tif_path, rows=480, cols=1440, x_res=0.25, y_res=0.25, nodata='--'):
# Read the CSV file into a pandas DataFrame
df = pd.read_csv(csv_path)
# Determine the range of longitude and latitude
lon_min = df['经度'].min()
lat_min = df['纬度'].min() # 纬度最小值
lat_max = df['纬度'].max() # 纬度最大值
# Calculate the geotransform
geotransform = [lon_min, x_res, 0, lat_max, 0, -y_res] # 纬度方向的分辨率是负值
# 创建一个空的数组,用于存储降雨量数据
raster_data = np.zeros((rows, cols))
# 将CSV数据填充到数组中
for index, row in df.iterrows():
lon = float(row['经度'])
lat = float(row['纬度'])
rain = row['降雨量']
if rain == nodata: # 检查是否为无效值
continue # 如果是无效值,则跳
rain = float(rain) # 转换为浮点数
x = int((lon - geotransform[0]) / geotransform[1]) # 计算经度对应的列索引
y = int((lat - geotransform[3]) / geotransform[5]) # 计算纬度对应的行索引
if 0 <= x < cols and 0 <= y < rows:
raster_data[y, x] = rain
driver = gdal.GetDriverByName('GTiff')
# 创建输出数据集
out_dataset = driver.Create(tif_path, cols, rows, 1, gdal.GDT_Float32)
# 设置地理变换
out_dataset.SetGeoTransform(geotransform)
# 设置投影
out_datasetSRS = out_dataset.GetProjection()
out_datasetSRS = "WGS84"
# 写入数据
outband = out_dataset.GetRasterBand(1)
outband.WriteArray(raster_data)
# 设置数据的无数据值,例如np.nan
outband.SetNoDataValue(np.nan)
# 保存并关闭数据集
out_dataset.FlushCache()
out_dataset = None
print(f"GeoTIFF has been created at: {tif_path}")
def read_nc_to_csv_batch(input_fl_path, time_resolution, year_start, year_end, month_start=1, month_end=12, to_csv=0,
to_tif=0):
second_level_path = os.path.dirname(input_fl_path)
for yr_dir in range(year_start, year_end+1):
for month_dir in range(month_start, month_end+1):
if time_resolution == 3: # daily
day_nc_fls_path = second_level_path + "\\" + str(yr_dir) + "\\" + f"{month_dir:02d}"
month_csv_fl_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '.csv'
month_tif_fl_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '.tif'
month_csv_nm = second_level_path + '\\' + str(yr_dir) + '\\' + month_csv_fl_nm
month_tif_nm = second_level_path + '\\' + str(yr_dir) + '\\' + month_tif_fl_nm
# 生成日均csv
if to_csv == 1:
nc_fls = os.listdir(day_nc_fls_path)
nc_fl_lts = filter(lambda filename: filename[-3:] == '.nc', nc_fls)
for nc_fl in nc_fl_lts:
day_nc_nm = day_nc_fls_path + "\\" + nc_fl
day_csv_nm = day_nc_fls_path + "\\" + nc_fl[:-3] + '.csv'
nc_to_csv(day_nc_nm, day_csv_nm)
# 生成月均csv
cal_add_nc(day_nc_fls_path, month_csv_nm)
if os.path.exists(month_csv_nm):
if to_tif == 1:
csv_to_tif(month_csv_nm, month_tif_nm)
else:
for day_dir in range(1, calendar.monthrange(yr_dir, month_dir)[1] + 1):
hour_nc_fls_path = second_level_path + '\\' + str(yr_dir) + '\\' + f"{month_dir:02d}" + '\\' + \
f"{day_dir:02d}"
day_nc_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '_' + f"{day_dir:02d}" + '.csv'
day_csv_nm = second_level_path + '\\' + str(yr_dir) + '\\' + f"{month_dir:02d}" + '\\' + day_nc_nm
# 生成原始文件csv, 时均
if to_csv == 1:
nc_fls = os.listdir(hour_nc_fls_path)
nc_fl_lts = filter(lambda filename: filename[-3:] == '.nc', nc_fls)
for nc_fl in nc_fl_lts:
hour_nc_nm = hour_nc_fls_path + "\\" + nc_fl
hour_csv_nm = hour_nc_fls_path + "\\" + nc_fl[:-3] + '.csv'
nc_to_csv(hour_nc_nm, hour_csv_nm)
# 生成日均csv
day_nc_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '_' + f"{day_dir:02d}" + '.csv'
day_csv_nm = second_level_path + '\\' + str(yr_dir) + '\\' + f"{month_dir:02d}" + '\\' + day_nc_nm
cal_add_nc(hour_nc_fls_path, day_csv_nm)
# 生成月均csv
day_nc_fls_path = second_level_path + '\\' + str(yr_dir) + '\\' + f"{month_dir:02d}"
month_csv_fl_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '.csv'
month_tif_fl_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '.tif'
month_csv_nm = second_level_path + '\\' + str(yr_dir) + '\\' + month_csv_fl_nm
month_tif_nm = second_level_path + '\\' + str(yr_dir) + '\\' + month_tif_fl_nm
cal_add_csv(day_nc_fls_path, month_csv_nm)
if os.path.exists(month_csv_nm):
if to_tif == 1:
csv_to_tif(month_csv_nm, month_tif_nm)
# 生成年均csv
month_nc_fls_path = second_level_path + '\\' + str(yr_dir)
year_csv_nm = second_level_path + '\\' + str(yr_dir) + '.csv'
year_tif_nm = second_level_path + '\\' + str(yr_dir) + '.tif'
cal_add_csv(month_nc_fls_path, year_csv_nm)
if os.path.exists(year_csv_nm):
if to_tif == 1:
csv_to_tif(year_csv_nm, year_tif_nm)
# 所选多年平均csv
year_nc_fls_path = second_level_path
add_rain_multi_year_csv = second_level_path + '\\'+'add_rain_multi_year.csv'
add_rain_multi_year_tif = second_level_path + '\\' + 'add_rain_multi_year.tif'
cal_add_csv(year_nc_fls_path, add_rain_multi_year_csv)
if to_tif == 1:
csv_to_tif(add_rain_multi_year_csv, add_rain_multi_year_tif)
if __name__ == '__main__':
input_path = "D:\\...\\降雨量数据获取_2\\"
time_kind = 3 # daily
start_year = 2023
end_year = 2024
start_month = 1 # 开始月,默认为1
end_month = 2 # 结束月,默认12
tran_csv = 0 # 原始文件转csv(0. 默认不转; 1. 转)
tran_tif = 1 # 转tif(0. 默认不转; 1. 转)
read_nc_to_csv_batch(input_path, time_kind, start_year, end_year, start_month, end_month, tran_csv, tran_tif)
合并后的代码
get_rain_nc_from_cmorph_to_tif.py
# -*- coding: utf-8 -*-
import os
import calendar
import requests
from bs4 import BeautifulSoup
import concurrent.futures
from netCDF4 import Dataset
import numpy as np
import pandas as pd
from osgeo import gdal
# 降雨量数据时空分辨率:8km×8km(30 min), 0.25°×0.25° (hourly, daily)(覆盖全球60°S - 60°N))
def download_file(out_fl_path, url, year, month, day):
if day != '':
download_url = url + str(year) + '/' + f"{month:02d}/" + f"{day:02d}/"
savePath = out_fl_path + str(year) + '/' + f"{month:02d}/" + f"{day:02d}/"
else:
download_url = url + str(year) + '/' + f"{month:02d}/"
savePath = out_fl_path + str(year) + '/' + f"{month:02d}/"
# print(download_url)
response = requests.get(download_url)
soup = BeautifulSoup(response.text, 'html.parser')
if not os.path.exists(savePath):
os.makedirs(savePath)
for link in soup.select('a[href$=".nc"]'):
name = link['href']
nc = requests.get(download_url + name)
with open(os.path.join(savePath, name), 'wb') as file:
file.write(nc.content)
print(name, '下载完成')
def get_rain_nc_from_cmorph(out_fl_path, time_resolution, year_start, year_end, month_start=1, month_end=12):
url_pre = 'https://www.ncei.noaa.gov/data/cmorph-high-resolution-global-precipitation-estimates/access/'
url = ''
if time_resolution == 1: # 30min
url = url_pre + '30min/8km/'
elif time_resolution == 2: # hourly
url = url_pre + 'hourly/0.25deg/'
elif time_resolution == 3: # daily
url = url_pre + 'daily/0.25deg/'
if url.split('/')[-3] == 'daily':
day = ''
with concurrent.futures.ThreadPoolExecutor(max_workers=12) as exe_code:
future_url = {exe_code.submit(download_file, out_fl_path, url, year, month, day): (year, month, day) for year
in range(year_start, year_end + 1) for month in range(month_start, month_end+1)}
else:
with concurrent.futures.ThreadPoolExecutor(max_workers=12) as exe_code:
future_url = {exe_code.submit(download_file, out_fl_path, url, year, month, day): (year, month, day) for year
in range(year_start, year_end + 1) for month in range(month_start, month_end+1) for day in
range(1, calendar.monthrange(year, month)[1] + 1)}
def nc_to_csv(input_fl_nm, output_fl_nm):
# 打开netCDF文件
# input_fl_nm = 'CMORPH_V1.0_ADJ_0.25deg-DLY_00Z_20230205.nc'
nc_file = Dataset(input_fl_nm, 'r')
# 获取经度和纬度数据
longitudes = nc_file.variables['lon'][:]
latitudes = nc_file.variables['lat'][:]
rainfall = nc_file.variables['cmorph'][:] # 1440x480的二维数组
# 生成经度和纬度的格网
lons, lats = np.meshgrid(longitudes, latitudes)
# 准备数据列表,每个元素是一个包含经度、纬度和降雨量的元组
data = list(zip(lons.flatten(), lats.flatten(), rainfall.flatten()))
# 创建DataFrame
df = pd.DataFrame(data, columns=['经度', '纬度', '降雨量'])
# 保存为CSV文件
# output_fl_nm = 'output.csv'
df.to_csv(output_fl_nm, index=False)
# 关闭netCDF文件
nc_file.close()
def cal_add_nc(input_fl_path, output_fl_nm):
nc_fls = os.listdir(input_fl_path)
nc_fl_lts = filter(lambda filename: filename[-3:] == '.nc', nc_fls)
nc_fl_lts = list(nc_fl_lts)
# print(nc_fl_lts)
if nc_fl_lts:
nc_fl_one = nc_fl_lts[0]
os.chdir(input_fl_path)
nc_fl = Dataset(nc_fl_one, 'r')
# 获取经度和纬度数据
longitudes = nc_fl.variables['lon'][:]
latitudes = nc_fl.variables['lat'][:]
rain_add = np.zeros((480, 1440))
for nc_fl_lt in nc_fl_lts:
# 打开NetCDF文件
nc_data = Dataset(nc_fl_lt, 'r')
# 打印所有变量名
# var_nms = []
# for var_nm in nc_data.variables:
# var_nms.append(var_nm)
# print(var_nms)
# 读取变量
rain_var = nc_data.variables['cmorph']
# print(rain_var)
# time_var = nc_data.variables['time']
# print(time_var)
# 读取整个变量数据
rain_data = rain_var[:][0]
rain_add = rain_add + rain_data
# print(rain_data.shape)
rainfall_add = rain_add[:]
# 生成经度和纬度的格网
lons, lats = np.meshgrid(longitudes, latitudes)
# 准备数据列表,每个元素是一个包含经度、纬度和降雨量的元组
data = list(zip(lons.flatten(), lats.flatten(), rainfall_add.flatten()))
# 创建DataFrame
df = pd.DataFrame(data, columns=['经度', '纬度', '降雨量'])
# 保存为CSV文件
df.to_csv(output_fl_nm, index=False)
# 关闭netCDF文件
nc_fl.close()
def cal_add_csv(input_fl_path, output_fl_nm):
# 获取所有CSV文件名
csv_fls = [f for f in os.listdir(input_fl_path) if f.endswith('.csv')]
csv_fl_lts = csv_fls # 直接使用列表推导得到的文件名列表
rainfall_add = np.zeros((480*1440,), dtype=float) # 初始化降雨量累加数组
# 读取第一个CSV文件的经度和纬度数据
csv_one_data = pd.read_csv(os.path.join(input_fl_path, csv_fl_lts[0]), low_memory=False)
longitude = csv_one_data['经度'].values
latitude = csv_one_data['纬度'].values
for csv_fl_lt in csv_fl_lts:
csv_data = pd.read_csv(os.path.join(input_fl_path, csv_fl_lt))
# 累加降雨量数据
rainfall_add += pd.to_numeric(csv_data.iloc[:, -1], errors='coerce').values
# 创建包含经度、纬度和降雨量总和的新DataFrame
combined_df = pd.DataFrame({
'经度': longitude,
'纬度': latitude,
'降雨量': rainfall_add
})
# 将结果保存到新的CSV文件中
combined_df.to_csv(output_fl_nm, index=False)
def csv_to_tif(csv_path, tif_path, rows=480, cols=1440, x_res=0.25, y_res=0.25, nodata='--'):
# Read the CSV file into a pandas DataFrame
df = pd.read_csv(csv_path)
# Determine the range of longitude and latitude
lon_min = df['经度'].min()
lat_min = df['纬度'].min() # 纬度最小值
lat_max = df['纬度'].max() # 纬度最大值
# Calculate the geotransform
geotransform = [lon_min, x_res, 0, lat_max, 0, -y_res] # 纬度方向的分辨率是负值
# 创建一个空的数组,用于存储降雨量数据
raster_data = np.zeros((rows, cols))
# 将CSV数据填充到数组中
for index, row in df.iterrows():
lon = float(row['经度'])
lat = float(row['纬度'])
rain = row['降雨量']
if rain == nodata: # 检查是否为无效值
continue # 如果是无效值,则跳
rain = float(rain) # 转换为浮点数
x = int((lon - geotransform[0]) / geotransform[1]) # 计算经度对应的列索引
y = int((lat - geotransform[3]) / geotransform[5]) # 计算纬度对应的行索引
if 0 <= x < cols and 0 <= y < rows:
raster_data[y, x] = rain
driver = gdal.GetDriverByName('GTiff')
# 创建输出数据集
out_dataset = driver.Create(tif_path, cols, rows, 1, gdal.GDT_Float32)
# 设置地理变换
out_dataset.SetGeoTransform(geotransform)
# 设置投影
out_datasetSRS = out_dataset.GetProjection()
out_datasetSRS = "WGS84"
# 写入数据
outband = out_dataset.GetRasterBand(1)
outband.WriteArray(raster_data)
# 设置数据的无数据值,例如np.nan
outband.SetNoDataValue(np.nan)
# 保存并关闭数据集
out_dataset.FlushCache()
out_dataset = None
print(f"GeoTIFF has been created at: {tif_path}")
def read_nc_to_csv_batch(input_fl_path, time_resolution, year_start, year_end, month_start=1, month_end=12, to_csv=0,
to_tif=0):
second_level_path = os.path.dirname(input_fl_path)
for yr_dir in range(year_start, year_end+1):
for month_dir in range(month_start, month_end+1):
if time_resolution == 3: # daily
day_nc_fls_path = second_level_path + "\\" + str(yr_dir) + "\\" + f"{month_dir:02d}"
month_csv_fl_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '.csv'
month_tif_fl_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '.tif'
month_csv_nm = second_level_path + '\\' + str(yr_dir) + '\\' + month_csv_fl_nm
month_tif_nm = second_level_path + '\\' + str(yr_dir) + '\\' + month_tif_fl_nm
# 生成日均csv
if to_csv == 1:
nc_fls = os.listdir(day_nc_fls_path)
nc_fl_lts = filter(lambda filename: filename[-3:] == '.nc', nc_fls)
for nc_fl in nc_fl_lts:
day_nc_nm = day_nc_fls_path + "\\" + nc_fl
day_csv_nm = day_nc_fls_path + "\\" + nc_fl[:-3] + '.csv'
nc_to_csv(day_nc_nm, day_csv_nm)
# 生成月均csv
cal_add_nc(day_nc_fls_path, month_csv_nm)
if os.path.exists(month_csv_nm):
if to_tif == 1:
csv_to_tif(month_csv_nm, month_tif_nm)
else:
for day_dir in range(1, calendar.monthrange(yr_dir, month_dir)[1] + 1):
hour_nc_fls_path = second_level_path + '\\' + str(yr_dir) + '\\' + f"{month_dir:02d}" + '\\' + \
f"{day_dir:02d}"
day_nc_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '_' + f"{day_dir:02d}" + '.csv'
day_csv_nm = second_level_path + '\\' + str(yr_dir) + '\\' + f"{month_dir:02d}" + '\\' + day_nc_nm
# 生成原始文件csv, 时均
if to_csv == 1:
nc_fls = os.listdir(hour_nc_fls_path)
nc_fl_lts = filter(lambda filename: filename[-3:] == '.nc', nc_fls)
for nc_fl in nc_fl_lts:
hour_nc_nm = hour_nc_fls_path + "\\" + nc_fl
hour_csv_nm = hour_nc_fls_path + "\\" + nc_fl[:-3] + '.csv'
nc_to_csv(hour_nc_nm, hour_csv_nm)
# 生成日均csv
day_nc_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '_' + f"{day_dir:02d}" + '.csv'
day_csv_nm = second_level_path + '\\' + str(yr_dir) + '\\' + f"{month_dir:02d}" + '\\' + day_nc_nm
cal_add_nc(hour_nc_fls_path, day_csv_nm)
# 生成月均csv
day_nc_fls_path = second_level_path + '\\' + str(yr_dir) + '\\' + f"{month_dir:02d}"
month_csv_fl_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '.csv'
month_tif_fl_nm = str(yr_dir) + '_' + f"{month_dir:02d}" + '.tif'
month_csv_nm = second_level_path + '\\' + str(yr_dir) + '\\' + month_csv_fl_nm
month_tif_nm = second_level_path + '\\' + str(yr_dir) + '\\' + month_tif_fl_nm
cal_add_csv(day_nc_fls_path, month_csv_nm)
if os.path.exists(month_csv_nm):
if to_tif == 1:
csv_to_tif(month_csv_nm, month_tif_nm)
# 生成年均csv
month_nc_fls_path = second_level_path + '\\' + str(yr_dir)
year_csv_nm = second_level_path + '\\' + str(yr_dir) + '.csv'
year_tif_nm = second_level_path + '\\' + str(yr_dir) + '.tif'
cal_add_csv(month_nc_fls_path, year_csv_nm)
if os.path.exists(year_csv_nm):
if to_tif == 1:
csv_to_tif(year_csv_nm, year_tif_nm)
# 所选多年平均csv
year_nc_fls_path = second_level_path
add_rain_multi_year_csv = second_level_path + '\\'+'add_rain_multi_year.csv'
add_rain_multi_year_tif = second_level_path + '\\' + 'add_rain_multi_year.tif'
cal_add_csv(year_nc_fls_path, add_rain_multi_year_csv)
if to_tif == 1:
csv_to_tif(add_rain_multi_year_csv, add_rain_multi_year_tif)
if __name__ == '__main__':
output_path = '.\\'
time_kind = 3 # daily
start_year = 2023 # 开始年
end_year = 2024 # 结束年
# get_rain_nc_from_cmorph(output_path, time_kind, start_year, end_year)
start_month = 1 # 开始月,默认为1
end_month = 2 # 结束月,默认12
get_rain_nc_from_cmorph(output_path, time_kind, start_year, end_year, start_month, end_month)
input_path = "D:\\...\\降雨量数据获取_2\\"
tran_csv = 0 # 原始文件转csv(0. 默认不转; 1. 转)
tran_tif = 1 # 转tif(0. 默认不转; 1. 转)
read_nc_to_csv_batch(input_path, time_kind, start_year, end_year, start_month, end_month, tran_csv, tran_tif)数据介绍及下载参考视频网址:https://www.bilibili.com/video/BV1yb421H7rF

















 6149
6149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









