







Java集合知识点整理
java.lang
- Collection接口
- List接口
- Set接口
- Map接口
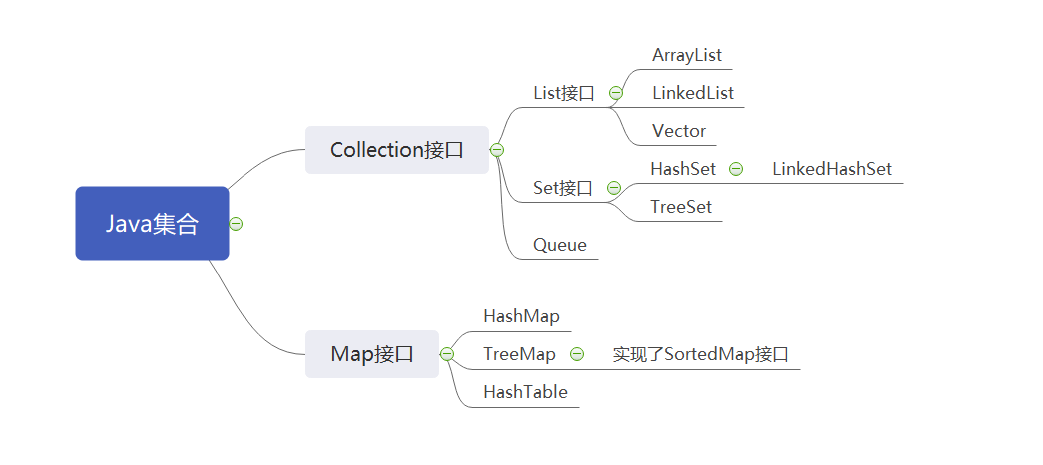
Collection
List
- 重复
- 有序
1 ArrayList
- List接口的主要实现类,底层用数组实现
- 优点
- 访问速度快
- 缺点
- 插入和删除开销大:增加和删除元素时,需要对整个数组进行遍历、定位和移动
- 线程不安全
源码分析:
-
JDK7
-
创建
- 底层创建一个长度为10的数组
-
扩容
-
设置新的存储空间为原来的1.5倍
- 如果新存储空间仍然不够,则将要求的最小存储空间设置成新存储空间
-
将原数组里的元素复制到新数组里
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); //设置新的存储能力为原来的1.5倍 if (newCapacity - minCapacity < 0) //扩容之后仍小于最低存储要求minCapacity newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) //private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
-
-
-
JDK8
- 创建
- 初始时,底层数组的容量为0,当添加第一个元素时,才将数组容量设置为10
- 扩容:和JDK7类似
- 创建
2 LinkedList
- 用双向链表存储元素
- 优点:
- 插入和删除数据快
- 缺点:
- 遍历和查找慢
- 线程不安全
3 Vector
-
底层用数组实现
-
初始化时,默认容量为10
-
扩容时,如果增量>0,则新容量为旧容量+增量;否则,新容量为原来的2倍。最后将数组里的值,复制到新数组里
- 如果新容量不够,则以要求的容量为新容量
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); elementData = Arrays.copyOf(elementData, newCapacity); } -
优点
- 线程安全的,同一时间只能有一个线程写Vector
-
缺点
- 访问速度慢
Set
- 无序
- 无序不代表没有顺序,而是不像数组一样按索引值顺序添加的,set是由HashCode来决定存储位置的
- 不可以重复
1 HashSet
-
Set接口的主要实现类,是线程不安全的
-
可以存储null值
-
添加
-
当向HashSet添加元素a时,会调用HashCode()方法计算元素a的哈希值
-
然后通过a的哈希值根据某种算法获得a的索引位置
-
如果索引位置处没有元素,则元素a添加成功
-
如果索引位置处有元素b,则a和b通过equals()方法比较
-
两值相等,则添加失败
-
两值不等,则添加成功
旧元素”七上八下“:jdk7新元素放到数组,指向旧元素;jdk8旧元素指向新元素
-
-
-
-
扩容

2 LinkedHashSet
- 添加数据的时候,会添加两个引用,引向前一个数据和后一个数据
- 底层用LinkedHashMap实现
3 TreeSet
- 要求添加的必须是同一个类的对象
- 会对添加的元素排序
Map
- Entry表示一对key和value
- Entry由Set结构保存,是无序、不可重复的
1 HashMap
-
Map的主要实现类
-
可以存放null的key和value,但最多只能允许一条key为null的entry,可以有多条value为null的entry
map.put(null, null); -
线程不安全
- 但是可以使用
synchronizedMap()方法和ConcurrentHashMap()方法使其变成线程安全的
- 但是可以使用
JDK7
- 底层用数组+链表实现的,数组默认容量为16
- 插入数据时,首先计算key的哈希值,然后找到数组相应要存放的位置
- 如果该位置是空的,则直接插入即可
- 如果该位置是非空的,则先比较key和位置上所有key值的哈希值
- 如果哈希值不相等,则插入key-value
- 如果哈希值相等,则需要调用key的equals方法和位置上存在的key1进行比较
- 如果相等,则将key1的value1替换成新的value
- 如果不相等,则以链表形式插入新的key-value
JDK8
-
底层用数组+链表+红黑树实现,初始化时,数组容量为0
- 当第一次put数据时,初始化16容量的数组
-
当链表元素>8且哈希表长度>MIN_TREEIFY_CAPACITY(64),则转换成红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { ... }
扩容
-
默认容量为16,负载因子为0.75
- 当超过容量*负载因子时,就扩容,扩容成原来的两倍
-
为什么负载因子为0.75?
- Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution.
- 负载因子是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。
2 TreeMap
- 插入的key必须是同一个类的对象
- 会根据key值进行排序
- 底层用红黑树实现
3 HashTable
- 线程安全的,效率低
- 不能存储值为null的key和value
- 有一个子类Property,用于处理配置文件
ibution.
- 负载因子是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。
2 TreeMap
- 插入的key必须是同一个类的对象
- 会根据key值进行排序
- 底层用红黑树实现
3 HashTable
- 线程安全的,效率低
- 不能存储值为null的key和value
- 有一个子类Property,用于处理配置文件















 6065
6065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









