







索引
索引是帮助 MySQL 高效获取数据的排好序的数据结构。
1.为什么要索引?
索引是帮助 MySQL 高效获取数据的排好序的数据结构。
-
如果没有索引,查找表就是从第一行数据开始找,会使得数据库和磁盘直接进行大量的 IO 操作。降低效率。
比如:
select * from t where t.col = 89;会一条一条取出来作比较。
2.什么是B+树?

-
B+ 树的非叶子节点,只保存索引,而不保存数据,因此 B+ 树比 B 树更加矮壮。这就意味着,B+ 树检索速度会更快
-
B+ 树叶子节点是一个有序双向链表,遍历查询更方便。
-
B+ 树的一个节点占有一页,一页大概是16k。每次查询,把一页加载到内存中去查询(比如二分查询)。如下图,就是一个节点(一页):

h=3 的 B+ 树差不多能放2千万的数据。
B+ 树查询过程
-
RAM是内存

为什么不用二叉搜索树?
-
如果数据是递增(或递减)的,搜索二叉树就成了一个链表。就和全表查询一样了。
为什么不用红黑树?
红黑树就是二叉平衡树。左右子树高度差不超过1。
-
红黑树也是一种二叉树,所以数据量大的时候,树的高度较高。
b 树比红黑树强的地方
-
红黑树是一种"二叉搜索树",每个node节点只能保存一对key,value
-
B 或 B+ 树是一种”多路搜索树“,每个node节点可以保存多个数据
-
因此,相比较而言,B 或者 B+ 树比红黑树高度更低,高度更低就意味着检索速度更快。
为什么不用 Hash 表
-
只能满足 =, IN 的查询,不支持范围查询
比如查询 col > 10
-
hash 有冲突问题
为什么不用B树?
B 树

-
B+ 树相比较 B 树,有两个优势
-
更矮壮:B+ 树的非叶子节点,只保存索引,而不保存数据,因此 B+ 树比 B 树更加矮壮。这就意味着,B+ 树检索速度会更快
-
叶子节点有序且是双向链表:B+ 树叶子节点是一个有序双向链表,遍历查询更方便,尤其支持范围查找。而B树就不行。
-
3.为什么建议 innoDB 表必须建主键,并且是auto_increment
-
如果不使用自增的主键,B+ 树会选一列唯一不重复的列来建立数据,如果没有,会维护一个row_id,但是这样会让 MySQL 多维护一列数据,而这个数据本身可以避免出现。
-
主键要自增:B+树叶子节点是有序排列的,如果主键索引不是自增的,新插入的数据可能会插到中间节点之间,这样可能会导致树不平衡而花费时间重新平衡。
什么是回表
回表会基于非主键索引的查询后回到主键索引树搜索的过程。即当通过非主键索引找到索引列值以外的字段时,就会回表。
比如:
create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k)) engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
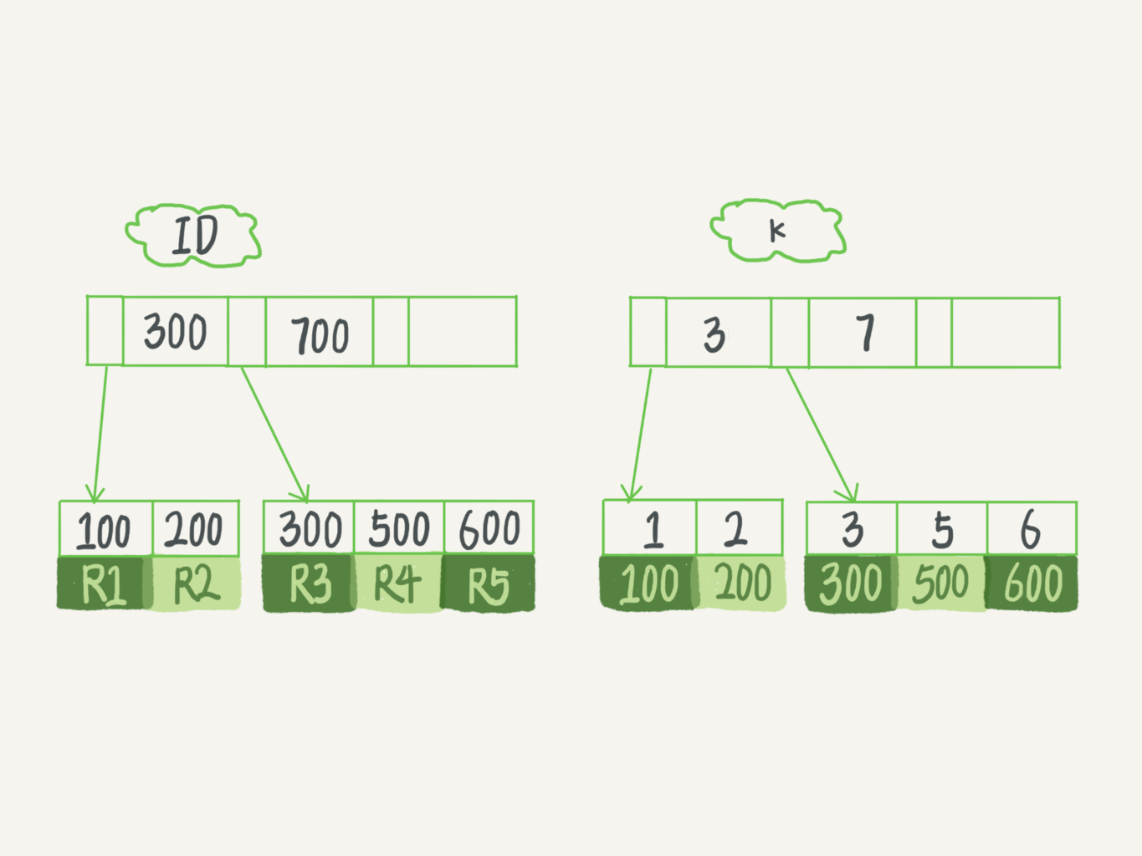
此时执行 select * from T where k between 3 and 5:
-
先在 k 索引树找到 k = 3 的数据记录,找到 id = 300
-
然后去主键索引树,找到 id = 300 的数据记录
-
这个过程就是在回表
原因:
-
因为非主键索引建立的B+树叶子节点的数据表保存的是索引列值和主键。(聚簇索引保存的是主键和其他所有列值)
-
所以,如果要查询索引值以外的值时,先要通过非主键索引找到相应的主键值,再通过主键值去聚簇索引B+树找到相应的数据行,再读取出要查询的数据。
-
比如,MySQL采用非主键索引name来作为索引,那么底层B+树存放的是name列值和主键id。如果此时用一下sql查询
select * from student where name = "James"
那么MySQL只能进行查询到name列值和相应的id,而其他的列值就必须通过这个id,再去聚簇索引保存的B+树,找到相应的数据并读取。这就是回表。
怎样避免回表
通过覆盖索引的方式。
-
就是建立联合索引,使得查询时候,想要的结果已经在叶子节点上了,而不需要进行回表操作。
-
比如如果要查 orderId 和 orderName,那就以这两个字段作为联合索引。这样 orderId 和 orderName 就作为数据保存在B+树的叶子节点上了,就不需要回表操作了。
覆盖索引
将被查询的字段,建立到联合索引里去
场景1:全表count查询优化

原表为: user(PK id, name, sex);
直接: select count(name) from user; 不能利用索引覆盖。
添加索引: alter table user add key(name); 就能够利用索引覆盖提效。
什么是联合索引?

最左前缀原则/最左匹配原则
B+树这种索引结构,可以利用索引的“最左前缀”,来定位记录。

(I) 比如上图索引为 index(name, age)
-
比如
-
查询条件为 where name = '张三',则找到 ("张三", 10), id=4 的记录,然后往后遍历所有满足条件的值
-
查询条件为 where name like '张%',则找到 ("张六", 30), id=3 的记录,然后往后遍历所有满足条件的值
-
-
所以,只要满足最左前缀,就可以利用索引来加速查找。
因此,建立索引时,要考虑索引顺序。比如,居民身份信息索引就只需建立
(card_id, name)和(name)就行了,不能再单独建立一个(card_id)
索引下推
当有联合索引 (name, age) 时,如果我们执行以下语句:
select * from user_info where name="王%" and age=20 and ismale=1;
-
在mysql 5.6之前,该查询首先会通过name去联合索引 (name, age) 树里查询,找到多条符合name="王%"的数据,然后根据 id 触发回表操作,去主键索引里找到符合条件的数据,整个过程需要回表多次。
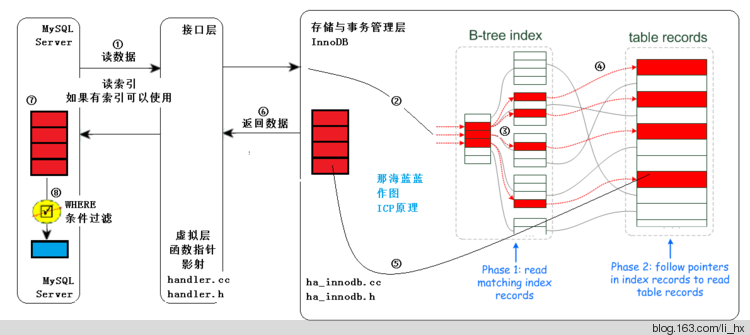
-
mysql 5.6 之后,有了索引下推。在索引内部就会先判断 age 是否等于 20,这样在 (name, age) 联合索引树中只会找到一个数据,然后拿着 id 回表找到数据。整个过程只需要回表一次。

聚簇/非聚簇索引
特点:
-
使用主键值的大小进行记录和页的排序。
-
页内的记录按照主键大小排成单向链表
-
各个数据页之间按照主键大小顺序排成双向链表
-
-
MySQL一个表只有一个聚簇索引。
-
如果没有定义主键。
-
InnoDB 会选择一个非空的唯一索引来代替。
-
如果没有这样的索引,则 InnoDB 会隐式的定义一个主键来作为聚簇索引。
-
缺点:
-
插入速度严重依赖于插入顺序。所以最好自增ID为主键, 否则插入会带来B+树的分裂。
-
更新主键代价很高,所以最好主键为不可更新。
MySQL 怎么创建索引?
三种方式
-
CREATE INDEX <index_name> ON TABLE <table_name> (<column_name>) -
ALTER TABLE <table_name> ADD INDEX <index_name>(<column_name>);
-
CREATE TABLE tableName( id INT NOT NULL, columnName columnType, INDEX [indexName] (columnName(length)) );
















 1429
1429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









