







1,hive创建表的语句
CREATE TABLE `olympic_data`(
`name` string,
`age` int,
`state` string,
`year` string,
`date` string,
`project` string,
`gold` int,
`silver` int,
`bronze` int,
`total` int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
2,mysql中创建表的语句:
CREATE TABLE `olympic_data` (
`name` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`state` varchar(20) DEFAULT NULL,
`year` varchar(20) DEFAULT NULL,
`date` varchar(20) DEFAULT NULL,
`project` varchar(20) DEFAULT NULL,
`gold` int(11) DEFAULT NULL,
`silver` int(11) DEFAULT NULL,
`bronze` int(11) DEFAULT NULL,
`total` int(11) DEFAULT NULL
)CHARSET=utf8
3,sqoop导出语句:
sqoop export \
--connect jdbc:mysql://master:3306/testdb \
--username hive \
--password 123456 \
--table olympic_data \
--export-dir /user/hive/warehouse/testdb.db/olympic_data/olympic_data.csv \
--fields-terminated-by '\t'
4,结果发现hive中原本有8618条数据,结果导出到mysql中发现数据只有8100条数据,然后我尝试调大map的个数到100,结果还是存在数据丢失。
hive中数据个数:
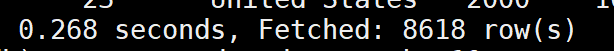
mysql中数据个数:
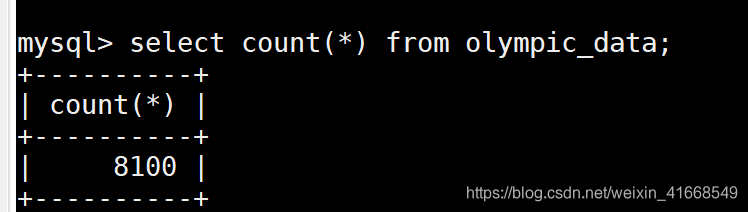
sqoop export \
--connect jdbc:mysql://master:3306/testdb \
--username hive \
--password 123456 \
--table olympic_data \
--export-dir /user/hive/warehouse/testdb.db/olympic_data/olympic_data.csv \
--fields-terminated-by '\t' \
-m 100
结果还是发现还是只有8100条数据,
5,最后我尝试加了-direct参数,结果发现数据全部导入成功。
sqoop export \
--connect jdbc:mysql://master:3306/testdb \
--username hive \
--password 123456 \
--table olympic_data \
--export-dir /user/hive/warehouse/testdb.db/olympic_data/olympic_data.csv \
--fields-terminated-by '\t' \
-direct
6,最后查了资料说direct参数是一种快速模式,是一种比JDBC更高效的将数据导入到关系型数据库方式。














 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









