









目录
一、Scrapy的简介
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。整体架构大致如下

它主要由五大组件和两中间件组成:
五大组件:
1、引擎(ENGINE):用来处理整个系统的数据流处理, 触发事务(框架核心)
2、调度器(SCHEDULER) : 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3、下载器(DOWLOADER):用于下载网页内容, 并将网页内容返回给ENGINE,下载器是建立在twisted这个高效的异步模型上的
4、爬虫(Spiders):爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
5、项目管道(Pipeline):负责处理爬虫从网页中抽取的实体(item),主要的功能是对item进行持久化、验证有效性、清理。当页面被操作。
两大中间件:
1、下载中间件:位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。比如:添加请求头,更换user-agent、代理ip等
2、爬虫中间件:介于Scrapy引擎和spiders之间的框架,主要工作是处理spider的响应输入和请求输出。
二、Scrapy的使用
1、安装
#Windows平台
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
#Linux平台
1、pip3 install scrapy
2、Scrapy工程的基本操作以及命令
#注意:都是在cmd下进行命令操作
# 1、创建scrapy工程
scrapy startproject 工程名字
# 2、切换到scrapy攻略目录下,创建爬虫文件
scrapy genspider 爬虫文件名字 www.xxx.com(允许爬取的域名)
# 3、执行scrapy工程
scrapy crawl 爬虫文件名字(不用带.py)
# 也可以创建一个py文件,内容如下,每次执行该py文件就可以
from scrapy.cmdline import execute
execute(['scrapy','crawl','爬虫文件名'])
'''
用法: scrapy <命令> [options] [args]
可用命令:
bench # scrapy压力测试
check # 检测项目有无语法错误
commands
crawl # 运行爬虫
edit # 编辑器,一般不用
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
genspider #创建爬虫程序
list #列出项目中所包含的爬虫名
parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确
runspider #运行一个独立的python文件,不必创建项目
settings #如果是在项目目录下,则得到的是该项目的配置
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
startproject #创建项目
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
'''
'''
例子:
注意:执行项目命令,要切到项目的目录下(check、list、parse、bench)
'''
scrapy settings --get XXX #如果切换到项目目录下,看到的则是该项目的配置
scrapy runspider baidu.py
scrapy shell https://www.baidu.com
response
response.status
response.body
view(response)
scrapy view https://www.taobao.com #如果页面显示内容不全,不全的内容则是ajax请求实现的,以此快速定位问题
scrapy fetch --nolog --headers https://www.taobao.com
scrapy version #scrapy的版本
scrapy version -v #依赖库的版本
3、项目结构
"""
├── project_name/
├── scrapy.cfg/ #项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中
├── project_name/
├── __init__.py/
├── items.py/ # 设置数据存储模板,用于结构化数据,类似Django的Model
├── settings.py # 配置文件,如:递归的层数、并发数,延迟下载等。强调:配置文件的选项必须大写否则视为无效,正确写法USER_AGENT='xxxx'
├── pipelines.py/ # 数据处理行为,如:一般结构化的数据持久化
├── spiders/ # 爬虫目录,如:创建文件,编写爬虫规则
├── __init__.py/
├── 爬虫文件1.py # 项目开发时的本地配置
├── 爬虫文件2.py # 项目开发时的本地配置
......
"""
4、数据解析
xpath解析和css解析
#1 //与/
response.xpath('//body/a/')#
response.css('div a::text')
response.xpath('//body/a') #开头的//代表从整篇文档中寻找,body之后的/代表body的儿子
>>> []
response.xpath('//body//a') #开头的//代表从整篇文档中寻找,body之后的//代表body的子子孙孙
>>> [<Selector xpath='//body//a' data='<a href="image1.html">Name: My image 1 <'>, <Selector xpath='//body//a' data='<a href="image2.html">Name: My image 2 <'>, <Selector xpath='//body//a' data='<a href="
image3.html">Name: My image 3 <'>, <Selector xpath='//body//a' data='<a href="image4.html">Name: My image 4 <'>, <Selector xpath='//body//a' data='<a href="image5.html">Name: My image 5 <'>]
#2 text 获取文本值
response.xpath('//body//a/text()')
response.css('body a::text')
'''
3、extract与extract_first:从selector对象中解出内容
extract()取出的是一个列表
extract_first()取出的是列表第一个元素
'''
response.xpath('//div/a/text()').extract()
>>> ['Name: My image 1 ', 'Name: My image 2 ', 'Name: My image 3 ', 'Name: My image 4 ', 'Name: My image 5 ']
response.css('div a::text').extract()
>>> ['Name: My image 1 ', 'Name: My image 2 ', 'Name: My image 3 ', 'Name: My image 4 ', 'Name: My image 5 ']
response.xpath('//div/a/text()').extract_first()
>>> 'Name: My image 1 '
response.css('div a::text').extract_first()
>>> 'Name: My image 1 '
#4、属性:xpath的属性加前缀@
response.xpath('//div/a/@href').extract_first()
>>> 'image1.html'
response.css('div a::attr(href)').extract_first()
>>> 'image1.html'
#4、嵌套查找
response.xpath('//div').css('a').xpath('@href').extract_first()
>>> 'image1.html'
#5、设置默认值
response.xpath('//div[@id="xxx"]').extract_first(default="not found")
>>> 'not found'
#4、按照属性查找
response.xpath('//div[@id="images"]/a[@href="image3.html"]/text()').extract()
response.css('#images a[@href="image3.html"]/text()').extract()
#5、按照属性模糊查找
response.xpath('//a[contains(@href,"image")]/@href').extract()
response.css('a[href*="image"]::attr(href)').extract()
response.xpath('//a[contains(@href,"image")]/img/@src').extract()
response.css('a[href*="imag"] img::attr(src)').extract()
response.xpath('//*[@href="image1.html"]')
response.css('*[href="image1.html"]')
#6、正则表达式
response.xpath('//a/text()').re(r'Name: (.*)')
response.xpath('//a/text()').re_first(r'Name: (.*)')
#7、xpath相对路径
res=response.xpath('//a[contains(@href,"3")]')[0]
res.xpath('img')
>>> [<Selector xpath='img' data='<img src="image3_thumb.jpg">'>]
res.xpath('./img')
>>> [<Selector xpath='./img' data='<img src="image3_thumb.jpg">'>]
res.xpath('.//img')
>>> [<Selector xpath='.//img' data='<img src="image3_thumb.jpg">'>]
res.xpath('//img') #这就是从头开始扫描
>>> [<Selector xpath='//img' data='<img src="image1_thumb.jpg">'>, <Selector xpath='//img' data='<img src="image2_thumb.jpg">'>, <Selector xpath='//img' data='<img src="image3_thumb.jpg">'>, <Selector xpa
th='//img' data='<img src="image4_thumb.jpg">'>, <Selector xpath='//img' data='<img src="image5_thumb.jpg">'>]
#8、带变量的xpath
response.xpath('//div[@id=$xxx]/a/text()',xxx='images').extract_first()
>>> 'Name: My image 1 '
response.xpath('//div[count(a)=$yyy]/@id',yyy=5).extract_first() #求有5个a标签的div的id
>>> 'images'
5、配置
# robosttxt 协议设置为false
ROBOTSTXT_OBEY = False
# 日志配置成错误级别
LOG_LEVEL='ERROR'
# 请求头配置
USER_AGENT = '浏览器标识'
'''
提升scrapy爬取数据效率的配置
#1 增加并发:
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。
#2 降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘INFO’
# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False
# 4禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False
# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 10 超时时间为10s
'''
'''
其他配置可以根据需要进行相应配置,也可以参考下面的其他配置
'''
#==>第一部分:基本配置<===
#1、项目名称,默认的USER_AGENT由它来构成,也作为日志记录的日志名
BOT_NAME = 'Amazon'
#2、爬虫应用路径
SPIDER_MODULES = ['Amazon.spiders']
NEWSPIDER_MODULE = 'Amazon.spiders'
#3、客户端User-Agent请求头
#USER_AGENT = 'Amazon (+http://www.yourdomain.com)'
#4、是否遵循爬虫协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
#5、是否支持cookie,cookiejar进行操作cookie,默认开启
#COOKIES_ENABLED = False
#6、Telnet用于查看当前爬虫的信息,操作爬虫等...使用telnet ip port ,然后通过命令操作
#TELNETCONSOLE_ENABLED = False
#TELNETCONSOLE_HOST = '127.0.0.1'
#TELNETCONSOLE_PORT = [6023,]
#7、Scrapy发送HTTP请求默认使用的请求头
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
#===>第二部分:并发与延迟<===
#1、下载器总共最大处理的并发请求数,默认值16
#CONCURRENT_REQUESTS = 32
#2、每个域名能够被执行的最大并发请求数目,默认值8
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#3、能够被单个IP处理的并发请求数,默认值0,代表无限制,需要注意两点
#I、如果不为零,那CONCURRENT_REQUESTS_PER_DOMAIN将被忽略,即并发数的限制是按照每个IP来计算,而不是每个域名
#II、该设置也影响DOWNLOAD_DELAY,如果该值不为零,那么DOWNLOAD_DELAY下载延迟是限制每个IP而不是每个域
#CONCURRENT_REQUESTS_PER_IP = 16
#4、如果没有开启智能限速,这个值就代表一个规定死的值,代表对同一网址延迟请求的秒数
#DOWNLOAD_DELAY = 3
#===>第三部分:智能限速/自动节流:AutoThrottle extension<===
#一:介绍
from scrapy.contrib.throttle import AutoThrottle #http://scrapy.readthedocs.io/en/latest/topics/autothrottle.html#topics-autothrottle
设置目标:
1、比使用默认的下载延迟对站点更好
2、自动调整scrapy到最佳的爬取速度,所以用户无需自己调整下载延迟到最佳状态。用户只需要定义允许最大并发的请求,剩下的事情由该扩展组件自动完成
#二:如何实现?
在Scrapy中,下载延迟是通过计算建立TCP连接到接收到HTTP包头(header)之间的时间来测量的。
注意,由于Scrapy可能在忙着处理spider的回调函数或者无法下载,因此在合作的多任务环境下准确测量这些延迟是十分苦难的。 不过,这些延迟仍然是对Scrapy(甚至是服务器)繁忙程度的合理测量,而这扩展就是以此为前提进行编写的。
#三:限速算法
自动限速算法基于以下规则调整下载延迟
#1、spiders开始时的下载延迟是基于AUTOTHROTTLE_START_DELAY的值
#2、当收到一个response,对目标站点的下载延迟=收到响应的延迟时间/AUTOTHROTTLE_TARGET_CONCURRENCY
#3、下一次请求的下载延迟就被设置成:对目标站点下载延迟时间和过去的下载延迟时间的平均值
#4、没有达到200个response则不允许降低延迟
#5、下载延迟不能变的比DOWNLOAD_DELAY更低或者比AUTOTHROTTLE_MAX_DELAY更高
#四:配置使用
#开启True,默认False
AUTOTHROTTLE_ENABLED = True
#起始的延迟
AUTOTHROTTLE_START_DELAY = 5
#最小延迟
DOWNLOAD_DELAY = 3
#最大延迟
AUTOTHROTTLE_MAX_DELAY = 10
#每秒并发请求数的平均值,不能高于 CONCURRENT_REQUESTS_PER_DOMAIN或CONCURRENT_REQUESTS_PER_IP,调高了则吞吐量增大强奸目标站点,调低了则对目标站点更加”礼貌“
#每个特定的时间点,scrapy并发请求的数目都可能高于或低于该值,这是爬虫视图达到的建议值而不是硬限制
AUTOTHROTTLE_TARGET_CONCURRENCY = 16.0
#调试
AUTOTHROTTLE_DEBUG = True
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
#===>第四部分:爬取深度与爬取方式<===
#1、爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度
# DEPTH_LIMIT = 3
#2、爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo
# 后进先出,深度优先
# DEPTH_PRIORITY = 0
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue'
# 先进先出,广度优先
# DEPTH_PRIORITY = 1
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
#3、调度器队列
# SCHEDULER = 'scrapy.core.scheduler.Scheduler'
# from scrapy.core.scheduler import Scheduler
#4、访问URL去重
# DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl'
#===>第五部分:中间件、Pipelines、扩展<===
#1、Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'Amazon.middlewares.AmazonSpiderMiddleware': 543,
#}
#2、Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'Amazon.middlewares.DownMiddleware1': 543,
}
#3、Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
#4、Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'Amazon.pipelines.CustomPipeline': 200,
}
#===>第六部分:缓存<===
"""
1. 启用缓存
目的用于将已经发送的请求或相应缓存下来,以便以后使用
from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware
from scrapy.extensions.httpcache import DummyPolicy
from scrapy.extensions.httpcache import FilesystemCacheStorage
"""
# 是否启用缓存策略
# HTTPCACHE_ENABLED = True
# 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy"
# 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy"
# 缓存超时时间
# HTTPCACHE_EXPIRATION_SECS = 0
# 缓存保存路径
# HTTPCACHE_DIR = 'httpcache'
# 缓存忽略的Http状态码
# HTTPCACHE_IGNORE_HTTP_CODES = []
# 缓存存储的插件
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#===>第七部分:线程池<===
REACTOR_THREADPOOL_MAXSIZE = 10
#Default: 10
#scrapy基于twisted异步IO框架,downloader是多线程的,线程数是Twisted线程池的默认大小(The maximum limit for Twisted Reactor thread pool size.)
#关于twisted线程池:
http://twistedmatrix.com/documents/10.1.0/core/howto/threading.html
#线程池实现:twisted.python.threadpool.ThreadPool
twisted调整线程池大小:
from twisted.internet import reactor
reactor.suggestThreadPoolSize(30)
6、scrapy持久化存储
(1)基于终端指令
'''
要求:只可以将parse方法的返回值存储到本地的文本文件中
注意:持久化存储对应的文本文件的类型只可以为:‘json','jsonlines','jl',’csv',‘xml',’marshal','pickle‘
指令:scrapy crawl 爬虫文件名 -o filePath
优点:简介高效便捷
缺点:局限性比较强(数据只可以存储到指定后缀的文本文件中)
'''
(2)基于管道
'''
items.py: 数据结构模版文件,定义数据属性
pipelines.py:管道文件,用来接收数据(items),进行持久化操作
持久化流程:
1.爬虫文件爬取到数据后,需要将数据封装到items对象中。需要导入items.py文件里面的类
2.使用yield关键字将items对象提交给pipelines管道进行持久化操作。
3.在管道文件中的process_item方法中接收爬虫文件提交过来的item对象,然后编写持久化存储的代码将item对象中存储的数据进行持久化存储
4.settings.py配置文件中开启管道
'''
# pipline.py 管道类
class BlogPostPipeline:
# 开始
def open_spider(self,spider):
self.conn=pymysql.connect(host='127.0.0.1', user='root', password="root",database='pcdb', charset='utf8mb4',port=3306,)
# 持久化过程
def process_item(self,item,spider):
cursor=self.conn.cursor()
sql = 'insert into article (title,url,content,`desc`) values (%s,%s,%s,%s)'
cursor.execute(sql, [item['title'], item['url'], item['content'], item['desc']])
self.conn.commit()
return item
# 结束
def close_spider(self,spider):
self.conn.close()
print('爬虫结束了')
#items文件
import scrapy
class PostItem(scrapy.Item):
title=scrapy.Field()
url=scrapy.Field()
desc=scrapy.Field()
content=scrapy.Field()
图片存储 :
1、在setting文件配置:IMAGES_STORE = ‘./imgs’:表示最终图片存储的目录,并在ITEM_PIPELINES中增加管道类中新增的类
2、重写一个管道类(继承ImagesPipeline)
3、基于ImagesPipeLine类的管道类三个方法:get_media_request()、file_path()、tiem_completed()
from scrapy.pipelines.images import ImagesPipeline
# 继承ImagesPipeline
class myPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
print('下载开始')
return scrapy.Request(item['img_url'],headers={'referer':item['img_referer']},meta={'item':item})
def file_path(self, request, response=None, info=None):
item=request.meta['item']
url = request.url
file_name=url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
print('下载结束')
return item
7、scrapy中间件(下载中间件)
(1)拦截请求:修改user-agent、请求头,加入代理ip(可以方法process_exception方法,或者process_request方法)等
(2)拦截响应:修改响应对象或者响应数据(例子:比如一些动态加载的页面)
def process_request(self, request, spider):
#1、更改请求头的user-agent
from fake_useragent import UserAgent
ua=UserAgent()
request.headers['User-Agent']=ua.random
# 2、设置代理ip
import requests
r = requests.get('http://127.0.0.1:5010/get/')
proxy=r.json().get('proxy')
request.meta['download_timeout'] = 5
request.meta["proxy"] = 'http://'+proxy
print(request)
return None
# 在中间件使用selenium处理ajax请求问题
def process_response(self, request, response, spider):
from scrapy.http import HtmlResponse
spider.bro.get('https://dig.chouti.com/')
response = HtmlResponse(url='https://dig.chouti.com/', body=spider.bro.page_source.encode('utf-8'),
request=request)
return response
三、去重源码解析
1、BaseDupeFilter源码
class BaseDupeFilter:
@classmethod
def from_settings(cls, settings):
return cls()
# 去重方法
def request_seen(self, request):
return False
def open(self): # can return deferred
pass
def close(self, reason): # can return a deferred
pass
def log(self, request, spider): # log that a request has been filtered
pass
2、RFPDupeFilter源码
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set() #集合
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
# 去重的主要方法
def request_seen(self, request):
'''
from scrapy.utils.request import request_fingerprint
利用request_fingerprint对请求取指纹(md5)
判断如果在集合中,返回True,不在则添加到集合
'''
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + '\n')
def request_fingerprint(self, request):
return request_fingerprint(request)
def close(self, reason):
if self.file:
self.file.close()
def log(self, request, spider):
if self.debug:
msg = "Filtered duplicate request: %(request)s (referer: %(referer)s)"
args = {'request': request, 'referer': referer_str(request)}
self.logger.debug(msg, args, extra={'spider': spider})
elif self.logdupes:
msg = ("Filtered duplicate request: %(request)s"
" - no more duplicates will be shown"
" (see DUPEFILTER_DEBUG to show all duplicates)")
self.logger.debug(msg, {'request': request}, extra={'spider': spider})
self.logdupes = False
spider.crawler.stats.inc_value('dupefilter/filtered', spider=spider)
3、通过BaseDupeFilter和RFPDupeFilter对比,我们可以看出去重规则主要在request_seen()方法中,则我们可以仿照写一个自定义去重类
(1) 新建一个去重文件dupfilter.py
from scrapy.dupefilters import BaseDupeFilter
class UrlFilter(BaseDupeFilter):
def __init__(self):
self.visited = set() #或者放到数据库
@classmethod
def from_settings(cls, settings):
return cls()
def request_seen(self, request):
if request.url in self.visited:
return True
self.visited.add(request.url)
def open(self): # can return deferred
pass
def close(self, reason): # can return a deferred
pass
def log(self, request, spider): # log that a request has been filtered
pass
(2) 在配置文件settings中
DUPEFILTER_CLASS = '项目名.dupfilter.UrlFilter'
四、scrapy-redis分布式爬虫
1、介绍
scrapy-redis是在原来的scrapy的基础上,重写Scheduler,让调度器到共享队列中取Request(该request请求时去重的)。去重主要是利用了redis的集合类型
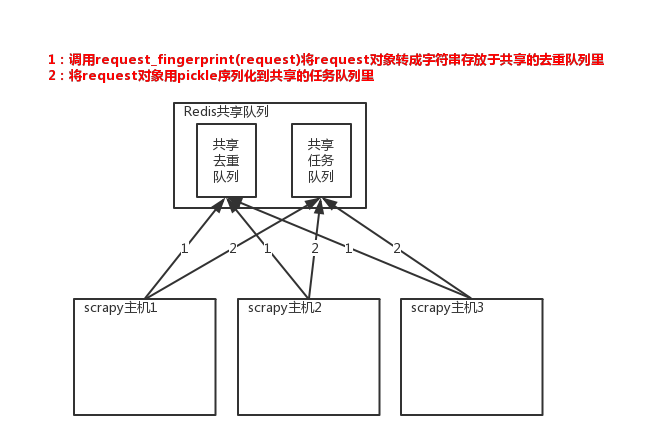
2、使用方法
(1)安装scrapy-redis模块,pip install scrapy-redis
(2)配置settings文件
# scheduler调度器配置,参考Scheduler源码
class Scheduler(object):
"""
在scrapy中settings的配置信息
--------
SCHEDULER_PERSIST : bool (default: False)
关闭的时候,是否保留redis队列(也就是起始地址).
SCHEDULER_FLUSH_ON_START : bool (default: False)
是否在启动时刷新redis队列。
SCHEDULER_IDLE_BEFORE_CLOSE : int (default: 0)
如果没有收到任何消息,在关闭之前要等待多少秒(超时时间)。
SCHEDULER_QUEUE_KEY : str
调度器中请求存放在redis中的key
SCHEDULER_QUEUE_CLASS : str
调度程序队列类s.
SCHEDULER_DUPEFILTER_KEY : str
去重规则中,在redis中保存对应的key值.
SCHEDULER_DUPEFILTER_CLASS : str
去重规则对应的处理类
SCHEDULER_SERIALIZER : str
对保存到redis中的数据进行序列化.默认使用pickle
# SCHEDULER_SERIALIZER ="scrapy_redis.picklecompat"
"""
# Redis配置,参考connection源码
def get_redis_from_settings(settings):
# ----------------
# 在settings中的配置
# ----------------
REDIS_URL : str, optional
# 例子:REDIS_URL='redis://:12345@127.0.0.1:6379'
#redis的连接url,优先去url配置(等同的host\post的配置),.
#注意:配置了url,就不用配置主机号跟端口了
REDIS_HOST : str, optional
#redis的主机名.
REDIS_PORT : str, optional
#redis的端口.
REDIS_ENCODING : str, optional
#redis的编码.
REDIS_PARAMS : dict, optional
#redis的其他参数,是字典类型.
#如: REDIS_PARAMS = {'password':'12345'}
# 持久化 配置,参考pipeline源码
class RedisPipeline(object):
Settings
--------
REDIS_ITEMS_KEY : str
# redis关键字
REDIS_ITEMS_SERIALIZER : str
# 序列化函数
# 参考spiders源码配置
class RedisSpider(RedisMixin, Spider):
Settings
--------
REDIS_START_URLS_KEY : str (default: "<spider.name>:start_urls")
# 起始rurl从对应的redis的key.
REDIS_START_URLS_BATCH_SIZE : int (deprecated by CONCURRENT_REQUESTS)
# 每次尝试从reids获取的url数,默认从配置中获取.
REDIS_START_URLS_AS_SET : bool (default: False)
# 获取起始URL时,如果为True,则使用self.server.spop;如果为False,则使用self.server.lpop
REDIS_ENCODING : str (default: "utf-8")
#编码
(3) 参考案例(在原来的scrapy的源码上进行修改)
'''
spdies文件
继承RedisSpider
'''
from scrapy_redis.spiders import RedisSpider
class BlogSpider(RedisSpider):
name = 'redis_blog'
redis_key = 'myspider:start_urls'
def parse(self, response):
print('---redis-blog-----')
article_list = response.xpath('//div[@id="post_list"]/article')
....
#settings文件配置
#redis的连接
REDIS_HOST='localhost'
REDIS_PORT=6379
# REDIS_PASSWD='12345'
REDIS_PARAMS = {'password':'12345'}
# REDIS_URL='redis://:12345@127.0.0.1:6379'
# from scrapy_redis.scheduler import Scheduler
DUPEFILTER_CLASS="scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = 'scrapy_redis.scheduler.Scheduler'
SCHEDULER_PERSIST = True
最后,在redis的数据库中插入一个起始地址:lpush myspider:start_urls https://www.cnblogs.com/ 就可以运行了















 4304
4304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









