







 1. 必备知识关联规则关联规则是形如 x->y 的蕴涵表达式,x,y是不相交的项集,即X∩Y=∅项集保含0个或者多个项的集合叫项集 数量是k 就叫k项集例:{鸡蛋, 水果,蛋糕} 是一个3项集 空集同理关联规则的强度一般用 支持度 support 和 可信度 confidence 来 度量支持度交易单商品0鸡蛋 牛奶 可乐 尿布1啤酒 ...
1. 必备知识关联规则关联规则是形如 x->y 的蕴涵表达式,x,y是不相交的项集,即X∩Y=∅项集保含0个或者多个项的集合叫项集 数量是k 就叫k项集例:{鸡蛋, 水果,蛋糕} 是一个3项集 空集同理关联规则的强度一般用 支持度 support 和 可信度 confidence 来 度量支持度交易单商品0鸡蛋 牛奶 可乐 尿布1啤酒 ...
1. 必备知识
关联规则
关联规则是形如 x->y 的蕴涵表达式,x,y是不相交的项集,即X∩Y=∅
项集
保含0个或者多个项的集合叫项集 数量是k 就叫k项集
例:{鸡蛋, 水果,蛋糕} 是一个3项集 空集同理
关联规则的强度
一般用 支持度 support 和 可信度 confidence 来 度量
支持度
| 交易单 | 商品 |
|---|---|
| 0 | 鸡蛋 牛奶 可乐 尿布 |
| 1 | 啤酒 鸡蛋 可乐 |
| 2 | 牛奶 鸡蛋 |
在上述列表中
鸡蛋的支持度为 3/3
牛奶为 2/3
尿布 1/3
可乐 2/3
(鸡蛋,尿布)为 0
(鸡蛋 可乐 ) 为 1/3
即一个项集的支持度 就是 他在所有项集中出现的频率
可信度(置信度)
可信度 和 数理统计中的 条件概率 类似
购买x中同时购买y的置信度为
confidence(x->y) = P(y/x) =P(x,y)/P(x) = 同时买x,y /买了 x
可乐->鸡蛋 的可信度为
同时买鸡蛋可乐 = 1/3 — (鸡蛋,可乐)的支持度
买可乐 2/3 — 可乐的支持度
结果就是 1/2 — 相除
同理 鸡蛋->可乐
为2/3
提升度(并没用到)
lift(x->y) = P(x,y)/(P(x)*P(y)= P(y/x)/P(y)
计算方法有很多种
提升度指 买 x对买y有没有提升作用,如果值大于1 则有用,1 无相关 ,小于1 负相关
可乐->鸡蛋 的提升度为
1/3 / (2/3 * 1) = 2 买可乐对买鸡蛋有提升作用
项目
交易数据库中的字段
即各种商品就是一个项目 鸡蛋是一个项目 牛奶是一个项目
事务
一次交易的所有项目集合
即一个人购物一次买的所有东西 {鸡蛋,牛奶}是一个事务 他代表路人甲一次购买的所有东西
频繁项集
所有支持度大于最小支持度的项集称为频繁项集,简称频集 (最小支持度由用户指定)
最大频繁项集是不被其他元素包含的频繁项目集
项目集的相关定理
定理( Apriori 属性1).
如果项目集X 是频繁项目集,那么它的所有非空子集都是频繁项目集
定理( Apriori 属性2).
如果项目集X 是非频繁项目集,那么它的所有超集都是非频繁项目集。
证明都很简单,也很容易理解,从定义理解即可。
关联规则挖掘问题
关联规则挖掘问题可以划分成两个子问题:
- 发现频繁项目集:通过用户给定Minsupport ,寻找所有频繁项目集或者最大频繁项目集。
- 生成关联规则:通过用户给定Minconfidence ,在频繁项目集中,寻找关联规则。
强关联规则
D在I上满足最小支持度和最小信任度(Minconfidence)的关联规则称为强关联规则(Strong Association Rule)。
即我们需要根据我们给出的最小支持度和最小可信度找到其中的规则
2.实例
1.寻找最大频繁项集
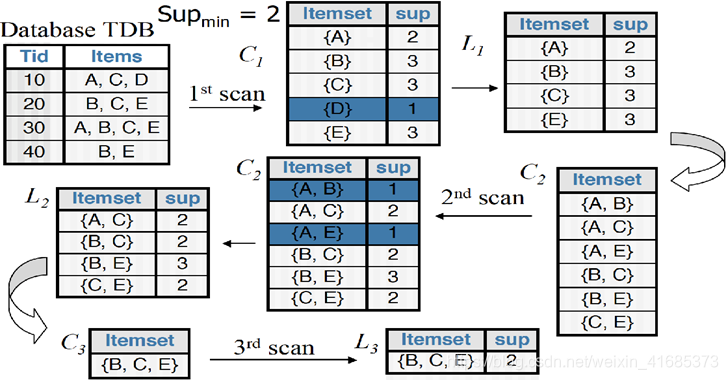
每一次扫描数据库, 从 1项集开始 ,淘汰不满足用户指定的最小支持度的项(这里是2)支持度为0.5 ,然后再两两结合生成i+1项集再淘汰直到最后唯一 , 这样我们就找到了最大频繁项集 {B, C,E }其他3项集都不满足最小支持度 ,这个图没标,在C3这里 还有{A,B,C},{ A,C,E},{A,B,E} 支持度只有1/4
2.生成强关联规则
若我们取最小可信度为80% 大于0.8 才可信
| 最大频繁项集(支持度) | 子集(支持度) | 可信度 | 规则 | 是否强关联 |
|---|---|---|---|---|
| B,C,E(50%) | B,C(50%) | 100% | BC->E | 是 |
| B,C,E(50%) | B,E(75%) | 67% | BE->C | 否 |
| B,C,E(50%) | C,E(50%) | 100% | CE->B | 是 |
| B,C,E(50%) | B(75%) | 67% | B->CE | 否 |
| B,C,E(50%) | C(75%) | 67% | C->BE | 否 |
| B,C,E(50%) | E(75%) | 67% | E->BC | 否 |
这样就找到了一个强关联规则 BC -> E 和 CE ->B
3.算法
python算法,写法也是抄别人的,我加了字典序的排序更加好看了
注释是自己写的
def load_data_set():
'''
给出数据库事务集
:return: data
'''
data_set = [
['A' ,'C' ,'D'],
['B' ,'C' ,'E'],
['A' ,'B' ,'C' ,'E'],
['B' ,'E']
]
data =[
['a','c','d','e','f'],
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9579
9579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









