






文章目录
前言
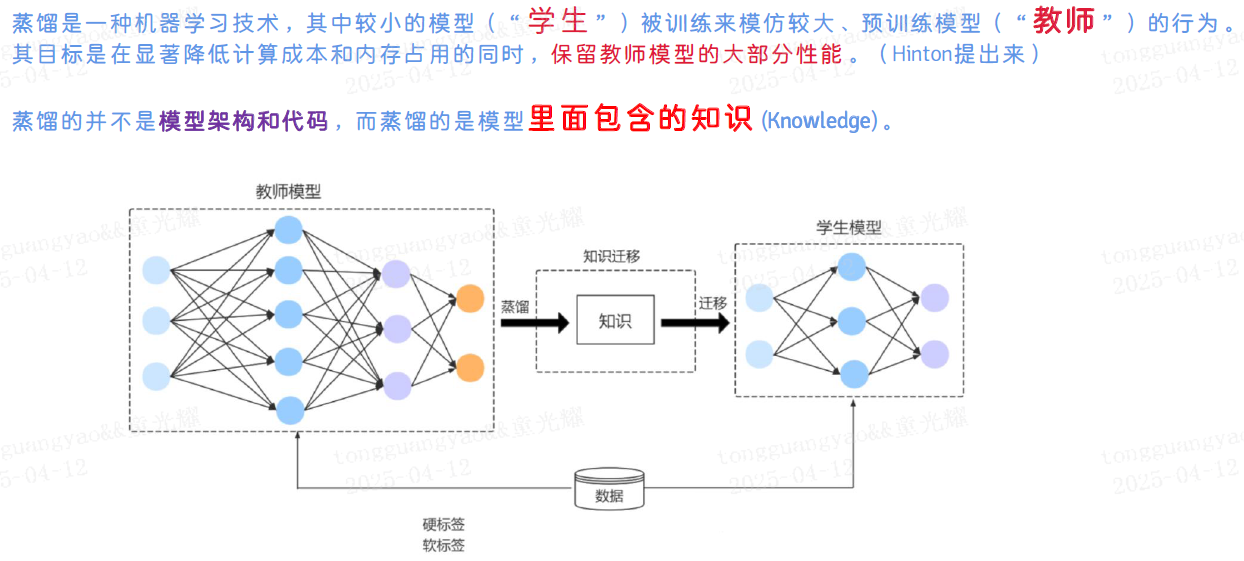
知识蒸馏通过将复杂模型的知识传递给小型模型,显著减少了模型的大小和计算复杂度,同时保持了较高的性能。它在自然语言处理、计算机视觉、推荐系统和语音识别等领域展现了广泛的应用前景,是模型压缩和优化的重要技术之一。
一、模型压缩方法介绍
深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、优化加速、异构计算等方法突破瓶颈。
模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署,具体可划分为如下几种方法(后续重点介绍剪枝与量化):
① 线性或非线性量化:1/2bits, int8 和 fp16等;
② 结构或非结构剪枝:deep compression, channel pruning 和 network slimming等;
③ 知识蒸馏与网络结构简化(squeeze-net, mobile-net, shuffle-net)等;
一、模型的剪枝、量化与知识蒸馏
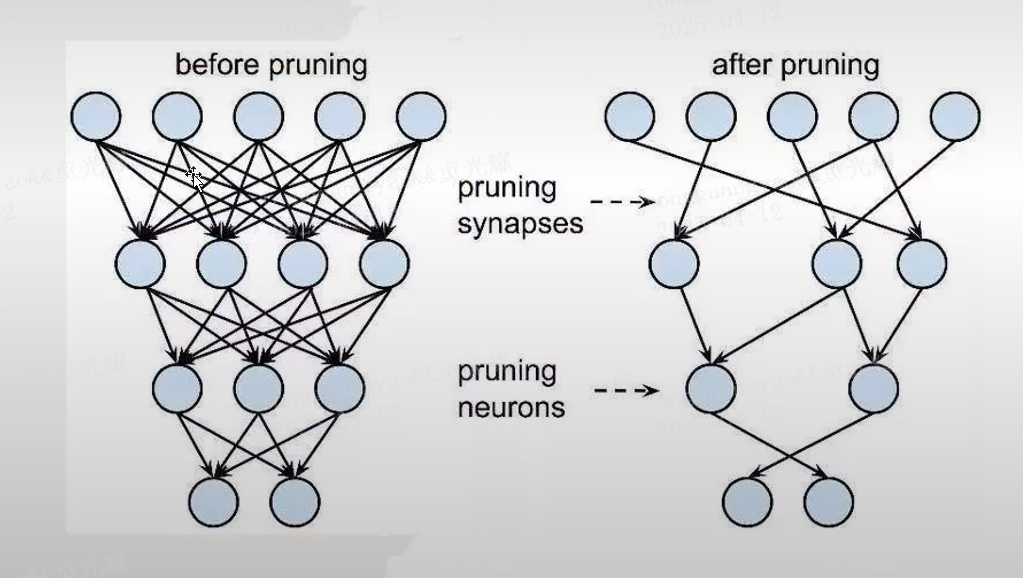
1. 剪枝
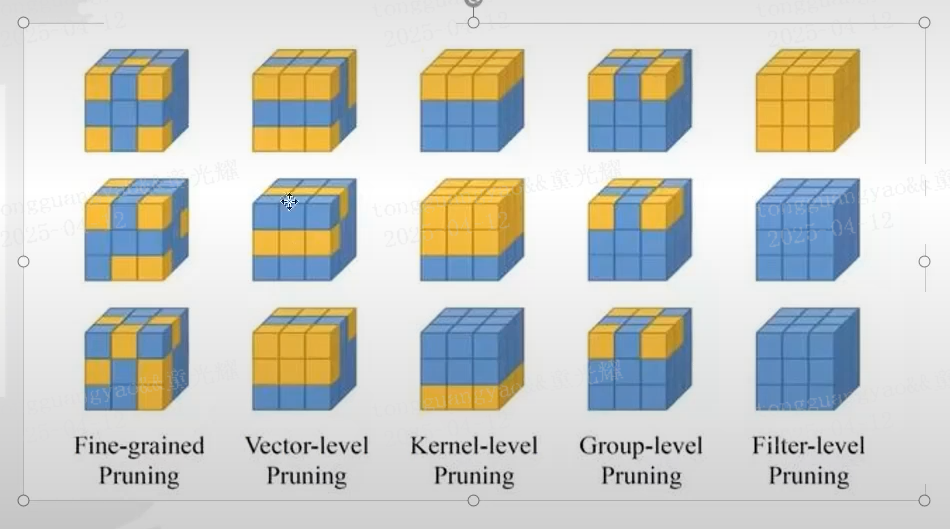
上面是一个3*3的卷积核,对应的5种剪枝方式
Fine-grained:最细粒化的,随机剪去某一维度的某些参数
Vector-level:按照固定的向量去剪
Kernel-level:分层剪,每个核减不同的层。
Group-level:细粒化剪枝,每个核固定的一层,某几个参数。
Filter-level:结构化剪枝,原本3个核,剪完剩2个。
2. 量化
1. 低精度
低精度(Low precision)可能是最通用的概念。常规精度一般使用 FP32(32位浮点,单
精度)存储模型权重;低精度则表示 FP16(半精度浮点),INT8(8位的定点整数)等等
数值格式。不过目前低精度往往指代 INT8。
2. 混合精度
混合精度(Mixed precision)在模型中使用 FP32 和 FP16 。 FP16 减少了一半的内存
大小,但有些参数或操作符必须采用 FP32 格式才能保持准确度。如果您对该主题感兴趣,
请查看 Mixed-Precision Training of Deep Neural Networks 。
3. INT8
量化一般指 INT8 。
根据存储一个权重元素所需的位数,还可以包括:
1. 二值神经网络
在运行时权重和激活只取两种值(例如 +1,-1)的神经网络,以及在训练时计算参数的梯度。
2. 三元权重网络
权重约束为+1,0和-1的神经网络。
3. XNOR网络
过滤器和卷积层的输入是二进制的。 XNOR 网络主要使用二进制运算来近似卷积。
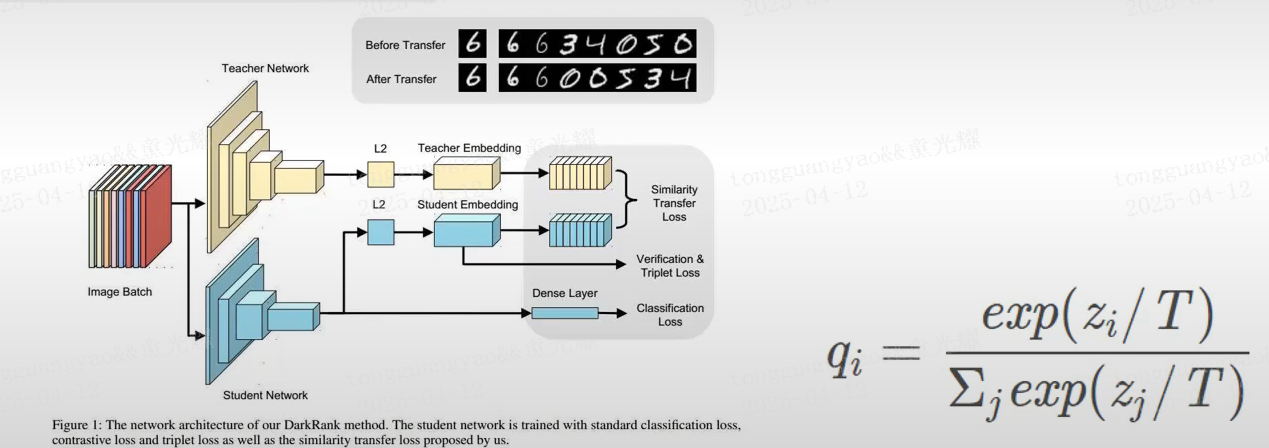
3. 蒸馏
知识蒸馏的核心思想是让学生模型模仿教师模型的输出分布或中间特征,而非仅学习原始标签。这种模仿过程类似于知识传承,教师模型的“暗知识”(Dark Knowledge)通过软标签(Soft Labels)或中间层特征传递给学生模型。
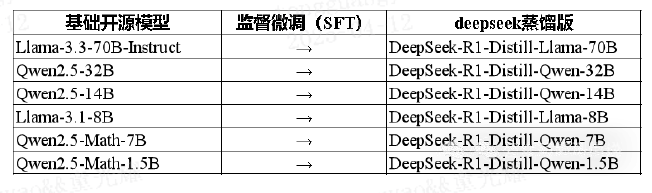
三、知识蒸馏在大模型中的应用
1. 模型压缩与推理加速
将大型模型(如 GPT-3.5、LLaMA-2-70B)蒸馏为更小的模型(如 7B 或 13B 规模),显著降低推理延迟。
例如,DistilBERT 将 12 层的 BERT-base 蒸馏为 6 层的学生模型,模型大小缩小约 40%,推理速度提升 60%,同时保留了 97% 的性能。
2. 边缘/移动端部署
在算力和内存有限的设备(如移动设备、嵌入式设备)上部署轻量级模型。例如,将 BERT-base 蒸馏为 MobileBERT 或 TinyBERT。
3. 多语言或多任务能力
大模型在多语言和多任务上的表现可以通过蒸馏传递给学生模型,使其继承多任务能力。
4. 知识迁移
教师模型在私有数据或增量数据上训练后,通过蒸馏将新知识迁移到学生模型中,避免学生从零开始大规模训练。
四、知识蒸馏快速训练大模型意义
1. 降低算力与成本
DeepSeek通过蒸馏技术将模型训练成本压缩至OpenAI同类模型的1/20。例如,DeepSeek-V3仅消耗278.8万GPU小时(成本约557.6万美元),而OpenAI类似模型的训练成本高达数亿美
元49。这种低成本特性使中小企业也能负担高性能AI模型的开发。
2. 加速推理与边缘部署
蒸馏后的小模型(如32B/70B版本)推理速度提升3倍以上,延迟从850ms降至150ms,显存占用从320GB减少至8GB。这使得模型可在手机、工业设备等边缘端实时运行,满足医疗诊断、自动驾驶等场景的低延迟需求
3. 推动行业应用落地
教育领域:DeepSeek蒸馏模型可快速生成个性化学习内容,根据学生反馈动态调整教学策略,降低教育平台运营成本。
工业场景:本地化部署的蒸馏模型减少对云端的依赖,数据隐私与响应速度显著提升,助力智能制造中的质检、供应链优化等任务。
内容创作:AI写作工具结合蒸馏模型,创作效率提升50%,同时API调用成本仅为OpenAI的1/4,推动新媒体运营与创意产业发展。
4. 技术自主可控
面对美国GPU芯片禁运,DeepSeek通过蒸馏技术降低对算力的依赖,结合FP8混合精度训练和DualPipe流水线机制,在国产芯片(如华为昇腾)上实现高性能推理,增强中国AI产业的自主可控能力。
五、案例:基于Qwen模型的知识蒸馏案例
1. 参数配置
模型设置:教师模型和学生模型分别设置为 “Qwen/Qwen-7B” 和 “Qwen/Qwen-1.8B”。
训练参数:包括批次大小、学习率、蒸馏温度(temperature)、蒸馏损失权重(alpha)等。
设备设置:根据设备可用性选择使用 GPU 或 CPU。
2. 数据加载
数据集类:DistillationDataset 是一个自定义的数据集类,用于加载和处理文本数据。
示例数据:代码中使用了示例文本数据(实际应用中需替换为真实数据集)。
数据预处理:使用 tokenizer 对文本进行编码,生成输入 ID 和注意力掩码。
3. 模型初始化
教师模型:加载教师模型并冻结其参数,确保在训练过程中不更新。
学生模型:加载学生模型并设置为训练模式。
4. 蒸馏损失函数
KL 散度损失:计算学生模型和教师模型的软目标分布之间的 KL 散度。
交叉熵损失:计算学生模型的自训练损失。
综合损失:通过权重(alpha)结合 KL 散度损失和交叉熵损失。
5. 训练流程
数据加载:使用 DataLoader 将数据集加载为批次。
教师模型前向传播:教师模型的输出用于指导学生模型的训练。
学生模型前向传播:学生模型的输出用于计算蒸馏损失。
反向传播:使用梯度累积和混合精度训练来提高训练效率。
学习率调整:根据训练步骤动态调整学习率。
模型保存:训练完成后,保存蒸馏后的学生模型。
6. 总结
这段代码实现了一个完整的知识蒸馏流程,通过将大型语言模型的知识传递给小型语言模型,显著减少了模型的大小和计算复杂度,同时保持了较高的性能。代码结构清晰,涵盖了从数据加载到模型训练和保存的完整流程,适用于实际的模型压缩和优化任务。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AdamW
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
# ========== 配置参数 ==========
class Config:
# 模型设置
teacher_model_name = "Qwen/Qwen-7B"
student_model_name = "Qwen/Qwen-1.8B"
# 训练参数
batch_size = 16
num_epochs = 3
learning_rate = 2e-5
max_seq_length = 512
temperature = 5.0
alpha = 0.7 # 蒸馏损失权重
# 设备设置
device = "cuda" if torch.cuda.is_available() else "cpu"
grad_accum_steps = 4 # 梯度累积步数
config = Config()
# ========== 数据加载 ==========
class DistillationDataset(Dataset):
def __init__(self, tokenizer, sample_texts):
self.tokenizer = tokenizer
self.examples = []
# 示例数据(实际需替换为真实数据集)
sample_texts = [
"人工智能的核心理念是",
"大语言模型蒸馏的关键在于",
"深度学习模型的压缩方法包括"
]
for text in sample_texts:
encoding = tokenizer(
text,
max_length=config.max_seq_length,
padding="max_length",
truncation=True,
return_tensors="pt"
)
self.examples.append(encoding)
def __len__(self):
return len(self.examples)
def __getitem__(self, idx):
return {
"input_ids": self.examples[idx]["input_ids"].squeeze(),
"attention_mask": self.examples[idx]["attention_mask"].squeeze()
}
# ========== 模型初始化 ==========
def load_models():
# 加载教师模型(冻结参数)
teacher = AutoModelForCausalLM.from_pretrained(
config.teacher_model_name,
device_map="auto",
torch_dtype=torch.bfloat16
).eval()
# 加载学生模型
student = AutoModelForCausalLM.from_pretrained(
config.student_model_name,
device_map="auto",
torch_dtype=torch.bfloat16
).train()
return teacher, student
# ========== 蒸馏损失函数 ==========
class DistillationLoss:
@staticmethod
def calculate(
teacher_logits, # 教师模型logits [batch, seq_len, vocab]
student_logits, # 学生模型logits [batch, seq_len, vocab]
temperature=config.temperature,
alpha=config.alpha
):
# 软目标蒸馏损失
soft_teacher = F.softmax(teacher_logits / temperature, dim=-1)
soft_student = F.log_softmax(student_logits / temperature, dim=-1)
kl_loss = F.kl_div(
soft_student,
soft_teacher,
reduction="batchmean",
log_target=False
) * (temperature ** 2)
# 学生自训练损失(交叉熵)
shift_logits = student_logits[..., :-1, :].contiguous()
shift_labels = teacher_logits.argmax(-1)[..., 1:].contiguous()
ce_loss = F.cross_entropy(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1)
)
return alpha * kl_loss + (1 - alpha) * ce_loss
# ========== 训练流程 ==========
def train():
# 初始化组件
tokenizer = AutoTokenizer.from_pretrained(config.teacher_model_name)
teacher, student = load_models()
# 数据集示例
dataset = DistillationDataset(tokenizer)
dataloader = DataLoader(dataset, batch_size=config.batch_size)
# 优化器设置
optimizer = AdamW(student.parameters(), lr=config.learning_rate)
# 混合精度训练
scaler = torch.cuda.amp.GradScaler()
# 训练循环
step_count = 0
student.to(config.device)
for epoch in range(config.num_epochs):
for batch_idx, batch in enumerate(dataloader):
inputs = {k: v.to(config.device) for k, v in batch.items()}
# 教师模型前向(不计算梯度)
with torch.no_grad(), torch.cuda.amp.autocast():
teacher_outputs = teacher(**inputs)
# 学生模型前向
with torch.cuda.amp.autocast():
student_outputs = student(**inputs)
loss = DistillationLoss.calculate(
teacher_outputs.logits,
student_outputs.logits
)
# 反向传播(带梯度累积)
scaler.scale(loss / config.grad_accum_steps).backward()
if (batch_idx + 1) % config.grad_accum_steps == 0:
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(student.parameters(), 1.0)
# 参数更新
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
step_count += 1
# 学习率调整(示例)
lr = config.learning_rate * min(step_count ** -0.5, step_count * (300 ** -1.5))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# 打印训练信息
if step_count % 10 == 0:
print(f"Epoch {epoch + 1} | Step {step_count} | Loss: {loss.item():.4f}")
# 保存蒸馏后的模型
student.save_pretrained("./distilled_qwen")
tokenizer.save_pretrained("./distilled_qwen")
if __name__ == "__main__":
train()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









