







一、SQL语句优化
1、优化count
每次分页操作都要获取一次count(),都需要扫描大量的行(意味着需要访问大量的数据)才能获得精确的结果,因此可以增加汇总表,或者redis缓存来专门记录该表对应的记录数,这样的话,就可以很轻松的实现汇总数据的查询,而且效率很高,但是这种统计并不能保证百分之百的准确。
创建一张表用来记录日志表的总数据量:
create table log_counter(
logcount bigint not null
)
在每次插入数据之后,更新该表 :
<update id="updateLogCounter" >
update log_counter set logcount = logcount + 1
</update>
在进行分页查询时, 获取总记录数,从该表中查询既可:
<select id="countLogFromCounter" resultType="long">
select logcount from log_counter limit 1
</select>
2、优化limit
查询越靠后的页码,查询效率则越慢:
select * from operation_log 1 limit 3000000 , 10;
将上述SQL优化为 :
select * from operation_log t , (select id from operation_log order by id limit
3000000,10) b where t.id = b.id ;
3、条件查询优化
针对于条件查询,需要对查询条件,及排序字段建立索引。

create index idx_id_username_roleid on t_user(id,username,role_id);
create index idx_username_roleid on t_user(username,role_id);
create index idx_roleid on t_user(role_id);
使用explain语句查看优化效果:


可以看到无论哪种组合查询都走了索引,查询效率明显提升。
4、优化排序
在查询数据时,如果业务需求中需要我们对结果内容进行了排序处理 , 这个时候,我们还需要对排序的字段建立适当的索引, 来提高排序的效率 。
二、服务器优化
1、MySQL主从复制和读写分离
服务器主从复制是指将主数据库的DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行,从而使得从库和主库的数据保持同步。在Mysql主从复制的基础上,可以使用读写分离来降低单台Mysql节点的压力,从而来提高访问效率,对于读写分离的实现,可以通过Spring AOP 来进行动态的切换数据源。
2、应用服务器优化
(1)缓存:可以在业务系统中使用redis来做缓存,缓存一些基础性的数据,来降低关系型数据库的压力,提高访问效率。
(2)全文检索:如果业务系统中的数据量比较大(达到千万级别),这个时候,如果再对数据库进行查询,特别是进行分页查询,速度将变得很慢(因为在分页时首先需要count求合计数),为了提高访问效率,这个时候,可以考虑加入Solr 或者 ElasticSearch全文检索服务,来提高访问效率。
(3)非关系型数据库:也可以考虑将非核心(重要)数据,存在 MongoDB 中,这样可以提高插入以及查询的效率。
注:联合索引的结构
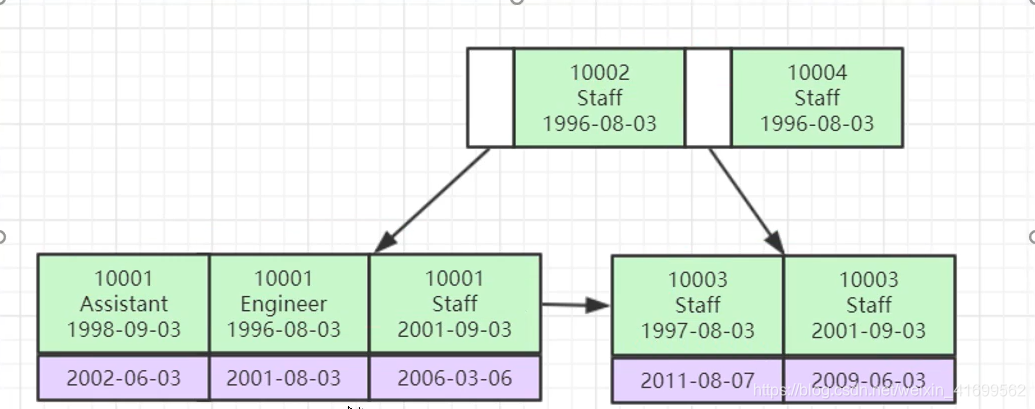
create index idx_id_username_roleid on t_user(id,username,role_id);
B+树排序时先比较id,再比较username,最后比较role_id.















 2018
2018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









