









一、什么是seq2seq,以及它和Attention机制有什么关系
- seq2seq是一种NLP常见的框架——这种框架不要求输入和输出序列是维度是一样的。许多NLP task的输入输出维度不统一,比如机器翻译、图像的图注生成、摘要生成、自动问答等。seq2seq框架大多包含encoder和decoder。
- Attention机制只是一种思想——即,人在理解一件事物并作出判断的时候,并不是概览了整个事物的全貌再作出判断,而是只着重关注了其中一部分。比如在机器翻译领域,每个英文单词翻译成中文词汇的时候,并不是这句英文里所有单词都做了平等的贡献,只是某一个或某几个单词作出了突出贡献。Attention机制就是要找到一种发现事物重要信息,然后被模型着重去学习的思想。
- Attention机制并不局限于某个特定框架,它在不同的框架下有不同的践行方案
二、Attention机制的基础定义
- 在传统的seq2seq模型中 ,encoder将一个个输入输入序列按顺序输入一个RNNcell中,然后在encoder的结尾生成一个语义编码向量C。这个C包含了输入序列的全部内容;decoder有两种形式——其一,将向量C考虑到每个输出步骤中,将C及y_t之前的所有步骤的输出都当做t时刻的输入,输入RNNcell计算(如图一),这种形式的seq2seq模型可以用以下数学公式表示:
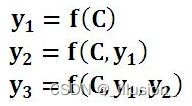
- 从公式可以看出,在传统的seq2seq模型中,语义编码向量C在整个过程中一视同仁。相似的,如图二,这里的唯一区别就是,encoder输出的语义编码向量C只作用于y_1的输出,其余都相似。如此一来,我们相当于将整个input的句子都看完以后,再进行理解和翻译,生成输出。而且输入句子中每个单词,在decoder中的价值是一样的。这显然还有进步的空间。因而,我们在此基础上增加了“Attention”机制,意图让decoder解码的时候,不要一下子关注输入序列全部的单词,一次只关注其中几个重要的。那么问题来了,假设翻译问题,当我们翻译第一个词的时候,我们如何知道该去关注哪些单词呢?比如将Natural language processing->自然语言处理,我们如何知道在翻译“自然”这个词的时候,主要去考虑Natural,而不是其他词语呢?

<seq2seq模式1>

<seq2seq模式2>
- 具体处理方式如下(如下图):
-

- 对于一般的Attention机制而言,我们在生成decoder的t时刻输出的时候,decoder考虑的语义编码向量C是不一样的,也就是说,随着t的变化,除了输入t时刻之前decoder的输出值之外,还需要考虑在不断变化的、根据encoder不同时刻隐状态决定的语义编码向量C。(如下图)

-
- 那么,这个C_i到底是如何计算出来的呢?公式如上。首先,根据Query(H_i),去计算它和encoder中每个隐状态Key(h_j)的Attention score。然后对所有的score进行softmax归一化,最后,将归一化后的向量分别乘以对应encoder隐状态Value(=Key, h_j)的值,最终得到c_i

如何理解Attention Model?
- 理解1:“对齐概率”。意即,还是“NLP->自然语言处理”的例子,你要计算”L“和“语言”对齐的概率,‘’P‘’和“处理”对齐的概率
- 理解2:“影响力模型”。意即,“L”对生成的“语言”和“处理”两个单词的影响力有多大。普遍的说,就是对于decoder中每个目标生成词而言,encoder中每个位置的单词对其有多大影响力。
- 理解3:如下公式。我们可以理解为,我们目前通过Source获得了Target,而我们目标中任意一个Target位置上的Query,获得的方式,其实就是对Source中每个位置的Value值加权求和。而这个权重,是由Query本身和Value对应的Key计算出来的

三、self-attention
- 就是query向量来自序列本身的Attention
四、回答几个问题:
回答下列问题:
a. 自注意力与注意力的区别?
- attention一般指的是encoder和decoder之间的Attention score的计算。其中,K和V来自encoder,先计算来自decoder的隐状态,即查询矩阵Q和对应encoder每个位置的隐状态键矩阵K之间的Attention值(这里是使用了矩阵的点乘),然后将结果经缩放后再softmax归一化,结果乘以K对应的值矩阵V,得到Attention结果
- 但self-attention,指的是encoder内部或decoder内部,自己和自己的Attention score的计算。如果说Attention机制计算的是decoder某时刻的输出与encoder所有位置的相关度的话,self-attention就是计算的encoder或decoder内部,比如一个句子中,某时刻的状态与其他时刻位置的相关度。因为self-attention都是一对一对计算的,所以它更善于捕获长距离的关系,如句法特征(一个动词和主语宾语介词的关系)、语义特征(its的指代)。
- Attention的query来自外部序列,而self-attention的query就来自于其本身
b. 为什么要进行残差连接?
- 随着层数的加深,没有残差连接可能使position embedding信息弥散。加上残差连接,可以缓解这样的问题
c. 为什么要设置多头注意力 ?
- 多头注意力,可以让模型学习到多个不同方向的表示,在不同的子空间中进行学习。如果只有single head,那么学到的相当于是多头的平均,这会削弱多头学习多个不同方向内容的能力
d. 一个自注意力层计算的复杂度是多少,为什么?
- O(n**2*d).因为每次计算一个self-Attention时,都需要计算t时刻与每个时刻的Attention score,这就说明有两次循环,每次循环都遍历所有时刻状态,序列长度为n,所以是n^2。而每次计算都要进行d维向量的乘积,所以还有d之后因数
e. 为什么要进行mask?
- 这个机制存在于decoder中,为了防止decoder在输出时考虑到t时刻以后的内容,所以将t+1及其以后的信息,在反向序列的输入中mask掉
f. 位置嵌入除了文中的这种形式还有哪些?
g. 比较一下CNN和self-attention?
- CNN可以通过卷积核的卷积运算和pooling运算获得局部的信息,但卷积核大小是有限的,距离特别远的信息,self-attention可以一步搞定,而CNN可能要通过卷积-池化而计算多次;
- CNN对比self-attention有个好出,那就是CNN可以同时考虑多个通道的输入。这个观点引入self-attention,就是“multi head self-attention”,同样,通过引入多个head,我们计算不同方向的内容表示,再将这些内容表示一同考虑
- 那么,multi head的多头是如何实现的?(如下图)其实,就是将QKV矩阵分别进行不同的线性变换,得到不同的QKV矩阵,再进行self-attention的计算。所以多头主要在于对QKV不同的线性映射方式。计算好self-attention权重后,再将结果concat在一起。最后再乘以Wo矩阵,其shape为(n_head*d_model, d_model),目的是将n和头拼接的,维度扩展了n倍的矩阵变换回d_model的shape

h. 为何模型选择了self-attention?
- 可以并行计算
- 可以捕获长距离的内容
i. 为何模型在计算Attention值的时候,对Q和K.T的矩阵除以和d_k^(1/2)?
- 可以防止Q和K.T点乘结果变得太大。因为二者结果要进行softmax归一化,如果结果太大,会导致其落在softmax函数的饱和区。
学习链接



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











