







 本文介绍了一种使用Pymupdf从PDF文档中精确提取带下划线文本的方法,包括处理多词下划线覆盖的技术细节。
本文介绍了一种使用Pymupdf从PDF文档中精确提取带下划线文本的方法,包括处理多词下划线覆盖的技术细节。
1,问题描述
最近,公司需要对一批pdf文档进行解析,获取其中文字,并再展示到前端页面上。如果单纯地提取文字,其实非常容易,但麻烦的在于保存原有文档中的文本格式,例如加粗、斜体、下划线,以及三者的各种组合(如加粗+下划线)。本文就要对这个问题进行解决
2,问题分析
首先在这里推荐一个Python语言下非常好用的pdf解析工具:Pymupdf。该工具除了比PDFMiner、pdfplumber等工具有更完善的功能外,更重要的一点,它的官方文档是非常详细的,而且在GitHub和Stack Overflow上都有足够多的问答。这对于一些少有人探寻过的功能的了解和使用是很重要的,有过这种体验的程序猿们肯定都懂
好了,我们开始分析这个问题。其实,对于加粗、斜体、下划线三者而言,使用pymupdf解析的方法是不同的,其中加粗和斜体很好解析,在此不多赘述。而下划线则要麻烦许多,为何如此呢?
其实,相比于另外两种,非批注式的下划线在PDF中并非是一种字体格式,它本质上是一种height极小的扁矩形、或干脆就是一条直线(后者我碰到的偏少),位置就位于被下划线修饰的文本下方(我们这里只探讨非批注式的下划线;通过批注新增的下划线很容易解析,借助pymupdf中的Annots类即可,也不是本文要说明的问题)。所以它的信息并不存在于page.get_text("dict")的结果中。
所以,获取下划线文本的逻辑与加粗or斜体完全不同:
- 我们要先将待解析下划线文本的页面的所有图样(get_drawings())先取回,设置过滤条件,只留下扁矩形和直线,并留下它们的坐标信息。对于直线而言,就是直线的左右两端的点;但对于扁矩形而言,应留下其(左上、右上)两个点的信息;
- 获取该页的`max_lineheight`,用于下面比较文本和待查下划线的距离(文本和其对应的下划线距离不可能大于此值);
- 使用page.get_text("words", sort=True)取得全部word的位置信息,并通过距离比较的方式,判断当前word有没有下划线、以及和哪个下划线相匹配;(这里需注意,由于page.get_text("words")方法获得的信息是按照空格进行切分的,这也就意味着如果一条下划线覆盖了多个单词,那么就需要进行更细一步的查找,具体就是当确认左侧首个单词被下划线覆盖后,一直向右查找,直到找到离下划线的右边界最近的word)
- 最后,将全部找到的下划线words返回
3,解决方案
BB less,show me the code
代码中包含详细注释,可仔细查看
def get_underlined_textLines(page):
'''
获取某页pdf上的所有下划线文本信息
:param page: fitz中的一页
:return: list of tuples,每个tuple都是一个完整的下划线覆盖的整体:[(下划线句, 所在blk_no, 所在line_no), ...]
'''
paths = page.get_drawings() # get drawings on the current page
# 获取该页内所有的height很小的bbox。因为下划线其实大多是这种矩形
# subselect things we may regard as lines
lines = []
for p in paths:
for item in p["items"]:
if item[0] == "l": # an actual line
p1, p2 = item[1:]
if p1.y == p2.y:
lines.append((p1, p2))
elif item[0] == "re": # a rectangle: check if height is small
r = item[1]
if r.width > r.height and r.height <= 2:
lines.append((r.tl, r.tr)) # take top left / right points
# 获取该页的`max_lineheight`,用于下面比较距离使用
blocks = page.get_text("dict", flags=fitz.TEXTFLAGS_TEXT)["blocks"]
max_lineheight = 0
for b in blocks:
for l in b["lines"]:
bbox = fitz.Rect(l["bbox"])
if bbox.height > max_lineheight:
max_lineheight = bbox.height
underlined_res = []
# 开始对下划线内容进行查询
# make a list of words
words = page.get_text("words", sort=True)
# if underlined, the bottom left / right of a word
# should not be too far away from left / right end of some line:
for wdx, w in enumerate(words): # w[4] is the actual word string
r = fitz.Rect(w[:4]) # first 4 items are the word bbox
for p1, p2 in lines: # check distances for start / end points
if abs(r.bl - p1) <= max_lineheight: # 当前word的左下满足下划线左下
if abs(r.br - p2) <= max_lineheight: # 当前word的右下满足下划线右下(单个词,无空格)
print(f"Word '{w[4]}' is underlined! Its block-line number is {w[-3], w[-2]}")
underlined_res.append((w[4], w[-3], w[-2])) # 分别是(下划线词,所在blk_no,所在line_no)
break # don't check more lines
else: # 继续寻找同line右侧的有缘人,因为有些下划线覆盖的词包含多个词,多个词之间有空格
curr_line_num = w[-2] # line nunmber
for right_wdx in range(wdx + 1, len(words), 1):
_next_w = words[right_wdx]
if _next_w[-2] != curr_line_num: # 当前遍历到的右侧word已经不是当前行的了(跨行是不行的)
break
_r_right = fitz.Rect(_next_w[:4]) # 获取当前同行右侧某word的方框4点
if abs(_r_right.br - p2) <= max_lineheight: # 用此word右下点和p2(目标下划线右上点)算距离,距离要小于max_lineheight
print(
f"Word '{' '.join([_one_word[4] for _one_word in words[wdx:right_wdx + 1]])}' is underlined! " +
f"Its block-line number is {w[-3], w[-2]}")
underlined_res.append(
(' '.join([_one_word[4] for _one_word in words[wdx:right_wdx + 1]]),
w[-3], w[-2])
) # 分别是(下划线词,所在blk_no,所在line_no)
break # don't check more lines
return underlined_res来个测试用例瞅瞅:
Triumeq.pdf文件第33页,具体如图所示:

该页PDF有3个带下划线的文本,那么用我的code试一下效果看看吧:
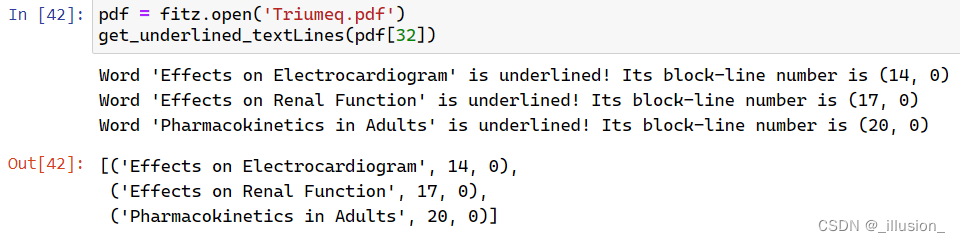
效果很棒, 比心~
4,尾声
此外,这里需要提到的是,该方法遇到部分特殊表格会误召回,毕竟有些表格的横向表格线和下划线,在pdf中实际上是一视同仁的;我的解决方案是,使用pdfplumber,将每个page内表格找到,并对应到pymupdf上,然后若下划线出现在表格所在line,则略过不处理。
最后,感谢原贴https://github.com/pymupdf/PyMuPDF/discussions/1756的探讨过程,部分代码借用



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











