









 本文详细介绍了随机森林中的决策树原理,包括熵、信息增益、信息增益比等概念,并通过C4.5算法展示了决策树的构建过程。文中通过实例解释了如何选择最佳特征,并探讨了决策树的剪枝问题,旨在帮助读者深入理解随机森林分类机制。
本文详细介绍了随机森林中的决策树原理,包括熵、信息增益、信息增益比等概念,并通过C4.5算法展示了决策树的构建过程。文中通过实例解释了如何选择最佳特征,并探讨了决策树的剪枝问题,旨在帮助读者深入理解随机森林分类机制。
-
疑问:随机森林如何设置需要的分类总数?
- 本文摘自:随机森林分类(Random Forest Classification) - Kevin.Tu - 博客园
代码:C4.5决策树+代码实践_ice110956的专栏-CSDN博客
其实,之前就接触过随机森林,但仅仅是用来做分类和回归。最近,因为要实现一个idea,想到用随机森林做ensemble learning才具体的来看其理论知识。随机森林主要是用到决策树的理论,也就是用决策树来对特征进行选择。而在特征选择的过程中用到的是熵的概念,其主要实现算法有ID3和C4.5.下面我们先来看看决策树。
下面我们用一个例子具体的来说明

我们要选取一个最好的特征来判断是否贷款,上面给出了年龄,工作,房子,信贷四种特征。如果一种特征具有更好的分类能力,或者说,按照这一特征将训练数据集分割成子集,使得各个子集是当前条件下最好的分类,我们就应该选择这个特征。对于这个问题,直观上是否有房子应该是最好的特征。但这也仅仅是从直观上判断,具体上来讲哪个特征最好了,这里我们引入一个概念-信息增益。
假设X是一个取值无限的离散随机变量,其概率分布为:
![]()
则其熵计算如下,这里我们把![]() 定义为经验熵。
定义为经验熵。
![]()
由于熵只依赖X的分布,而与X的取值无关。所以,我们又把熵定义为:
![]()
假设我们有两个随机变量x,y(generally,X denote the feature vectors,and Y denote labels)。其联合概率分布为:
![]()
这里,假如给定一个X,要我们准确的判断其所属类别,也就是要准确的判断Y。很自然的,我们需要求解给定X下的条件熵:
![]()
假设,特征A 对训练集D的信息增益为![]() ,定义为集合D 的经验熵H(D)与特征A给定条件下D的经验熵H(D|A)之差,那么我们定义信息增益如下:
,定义为集合D 的经验熵H(D)与特征A给定条件下D的经验熵H(D|A)之差,那么我们定义信息增益如下:
![]()
一般的,我们把熵H(Y)与条件熵H(Y|X)只差定义为互信息,决策树中的信息增益就是训练数据集中的类与特征的互信息。下面给出计算信息增益的方法:

![]()

如果我们以信息增益为划分训练数据集的特征,存在于选择取值较多的特征的问题。这里我们使用信息增益比(information gain ratio),可以对这一问题进行校正。这是特征选择的另一准则。

下面来介绍一下ID3算法,该算法的核心就是不断的利用信息增益准则选择特征,最终达到分类的目的。


C4.5算法其实就是在ID3算法上做了一点的改动,把特征选择的方法改为用信息增益比来计算,而不用ID3中的计算信息增益的方法。其算法流程和ID3差不多,这里就不介绍了。下面来简单的谈一下决策树的剪枝问题,由于决策树是严格的按照一定的规则进行计算,过多的考虑了训练样本的正确性,所以这导致其容易过拟合。所以这里引入剪枝的概念,通过优化损失函数,减少模型的复杂性。具体算法过程可以看课本P-66~P-67页。
function D = C4_5(train_features, train_targets, inc_node,test_features)
%http://blog.csdn.net/ice110956/article/details/10049149
% 1.train_features,为训练集; train_targets,为训练集标签;
% inc_node为防止过拟合参数,表示样本数小于一定阈值结束递归,可设置为5-10;test_features为测试集。
% 2.取消离散变量,上面说了,是因为我不知道如何处理Miss value的问题,至于影响,应该就是连贪心也算不上了吧,应该是一个理论上还过得去的处理方法。
% 3.图怎么画?介绍几个画图软件:http://www.cnblogs.com/damonlan/archive/2012/03/29/2410301.html
% 决策树扩展篇:http://blog.csdn.net/ice110956/article/details/29175215
[Ni, M] = size(train_features); %输入向量为NI*M的矩阵,其中M表示训练样本个数,Ni为特征维数维数
inc_node = inc_node*M/100;
disp('Building tree')
tree = make_tree(train_features, train_targets, inc_node);
%Make the decision region according to the tree %根据产生的数产生决策域
disp('Building decision surface using the tree')
[n,m]=size(test_features);
targets = use_tree(test_features, 1:m, tree, unique(train_targets)); %target里包含了对应的测试样本分类所得的类别数
D = targets;
%END
function targets = use_tree(features, indices, tree, Uc) %target里包含了对应的测试样本分类所得的类别
targets = zeros(1, size(features,2)); %1*M的向量
if (tree.dim == 0)
%Reached the end of the tree
targets(indices) = tree.child;
return %child里面包含了类别信息,indeces包含了测试样本中当前测试的样本索引
end
dim = tree.dim; %当前节点的特征参数
dims= 1:size(features,1); %dims为1-特征维数的向量
%Discrete feature
in = indices(find(features(dim, indices) <= tree.split_loc)); %in为左子树在原矩阵的index
targets = targets + use_tree(features(dims, :), in, tree.child_1, Uc);
in = indices(find(features(dim, indices) > tree.split_loc));
targets = targets + use_tree(features(dims, :), in, tree.child_2, Uc);
return
function tree = make_tree(features, targets, inc_node)
[Ni, L] = size(features);
Uc = unique(targets); %UC表示类别数
tree.dim = 0; %数的维度为0
%tree.child(1:maxNbin) = zeros(1,maxNbin);
if isempty(features), %如果特征为空,退出
return
end
%When to stop: If the dimension is one or the number of examples is small
if ((inc_node > L) | (L == 1) | (length(Uc) == 1)), %剩余训练集只剩一个,或太小,小于inc_node,或只剩一类,退出
H = hist(targets, length(Uc)); %返回类别数的直方图
[m, largest] = max(H); %更大的一类,m为大的值,即个数,largest为位置,即类别的位置
tree.child = Uc(largest); %直接返回其中更大的一类作为其类别
return
end
%Compute the node's I
%计算现有的信息量
for i = 1:length(Uc),
Pnode(i) = length(find(targets == Uc(i))) / L;
end
Inode = -sum(Pnode.*log(Pnode)/log(2));
%For each dimension, compute the gain ratio impurity
%This is done separately for discrete and continuous features
delta_Ib = zeros(1, Ni);
S=[];
for i = 1:Ni,
data = features(i,:);
temp=unique(data);
P = zeros(length(Uc), 2);
%Sort the features
[sorted_data, indices] = sort(data);
sorted_targets = targets(indices);
%结果为排序后的特征和类别
%Calculate the information for each possible split
I = zeros(1, L-1);
for j = 1:L-1,
for k =1:length(Uc),
P(k,1) = length(find(sorted_targets(1:j) == Uc(k)));
P(k,2) = length(find(sorted_targets(j+1:end) == Uc(k)));
end
Ps = sum(P)/L; %两个子树的权重
temp1=[P(:,1)];
temp2=[P(:,2)];
fo=[Info(temp1),Info(temp2)];
%info = sum(-P.*log(eps+P)/log(2)); %两个子树的I
I(j) = Inode - sum(fo.*Ps);
end
[delta_Ib(i), s] = max(I);
S=[S,s];
end
%Find the dimension minimizing delta_Ib
%找到最大的划分方法
[m, dim] = max(delta_Ib);
dims = 1:Ni;
tree.dim = dim;
%Split along the 'dim' dimension
%分裂树
%Continuous feature
[sorted_data, indices] = sort(features(dim,:));
%tree.split_loc = split_loc(dim);
%disp(tree.split_loc);
S(dim)
indices1=indices(1:S(dim))
indices2=indices(S(dim)+1:end)
tree.split_loc=sorted_data(S(dim))
tree.child_1 = make_tree(features(dims, indices1), targets(indices1), inc_node);
tree.child_2 = make_tree(features(dims, indices2), targets(indices2), inc_node);
%D = C4_5_new(train_features, train_targets, inc_node);
————————————————
版权声明:本文为CSDN博主「ice110956」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ice110956/article/details/10049149其实代码不难,下面我给出我的理解。
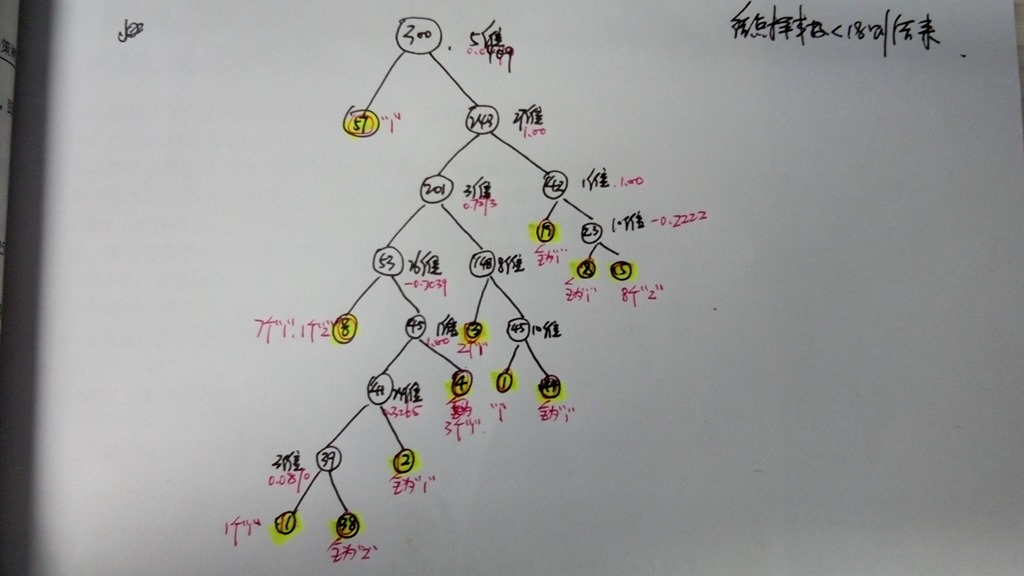
Here we split the data into two sets,with 300 training samples and 51 testing samples,each data is a 34-dimensional vector. Here, each dimension can be regarded as a variable,with respect to a kind of “feature”.
在这个决策树中,对每个节点我们计算它的信息增益比,如果信息增益比小于某个阈值。或者,节点包含的样本数小于18(自己设定),则结束递归。从上图中可以看出,从根节点出发(这个节点包含300个样本),第5维特征最好,所以用这个特征进行划分。得到左子树(57个样本全为“1”),右子树(包含243个样本)。所以左子树结束递归,接着计算右子树的特征,第27维特征最好。一直循环….
最后我们得到这样的一个决策树,除了叶节点,中间节点都包含一个最佳分类的特征,和这个特征对应的特征值。每个叶节点包含一定数量的样本,叶节点的类别规定为多数样本对应的类别。得到了这样的一个决策树后,我们就可以对测试样本进行分类了。使用中间节点记录的特征对测试样本进行划分,直到测试样本划分到每个叶节点中。叶节点中样本的类别就是该测试样本的类别了。















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









