







在几天前的红杉资本2024年
AI Ascent上
安德烈·卡帕西Andrej Karpathy与红杉资本合伙人Stephanie Zhan
深入探讨了AI的未来发展方向

以及对初创企业生态系统的影响
Andrej Karpathy大家应该不陌生
他曾经是OpenAI创始成员、前特斯拉人工智能高级总监
前一段刚从OpenAI离职

在Andrej看来
Llama和Mixtral并不算是真正意义上的开源
更像是一个二进制文件

同时
Andrej还分享了他与埃隆·马斯克共事的经验
揭示了马斯克独特的管理风格
以及对小而精技术团队的偏好

他还讨论了AI技术的现状
指出目前AI仍处于模仿学习的初级阶段
距离实现强化学习的目标还有一段距离
在与观众的互动环节中
他回答了关于模型合成、企业理念、以及如何平衡性能与成本的问题
并强调当下的AI发展应先追求大模型性能
再考虑降低成本
接下来,我们就详细梳理一下
Andrej Karpathy这次谈话的核心内容
大语言模型操作系统LLM OS

首先是关于大语言模型操作系统LLM OS的看法
Andrej首先认为几年前
他还不清楚AGI会如何发展
因为它非常学术化
但是现在他觉得已经非常清晰了
简单来说
现在每个人都在努力构建他所说的LLM OS
为开发人员提供免费、快速的LLM API
它就像一个操作系统一样
可以把一堆外设插入这个新的CPU中
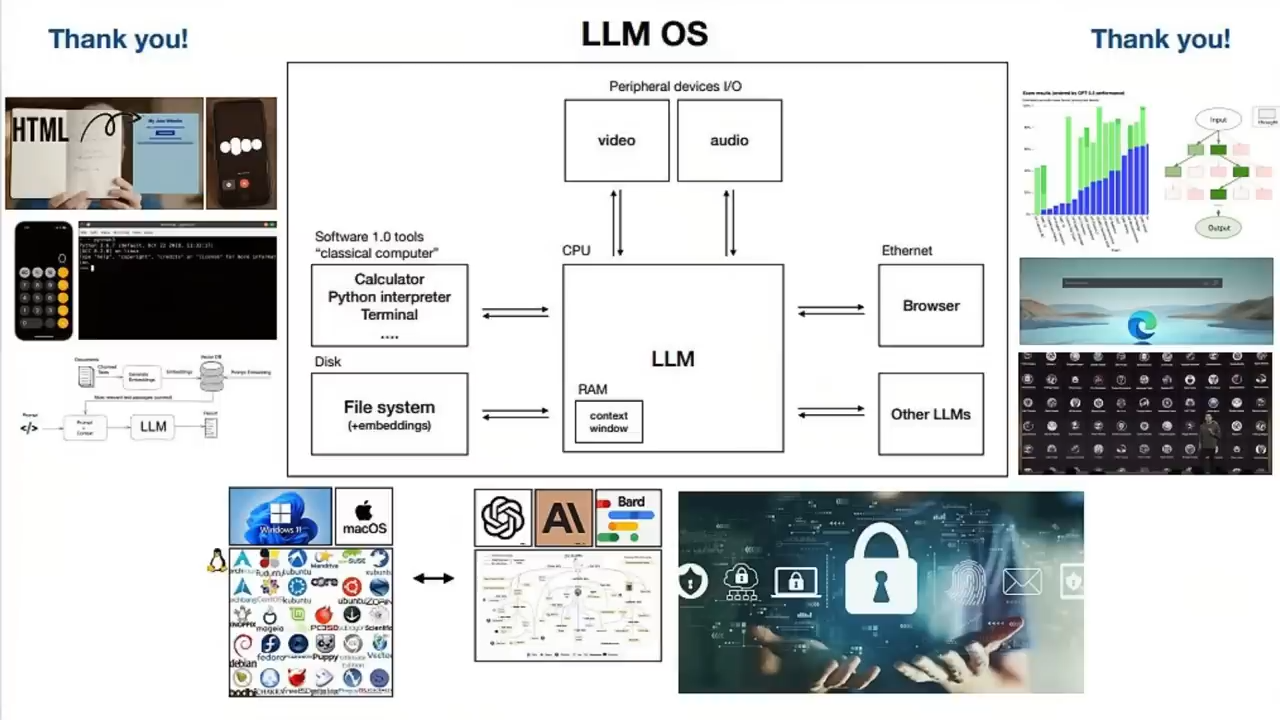
这些外设包括文本、图像、音频和所有模式
然后是中央处理器
也就是LLM Transformer本身
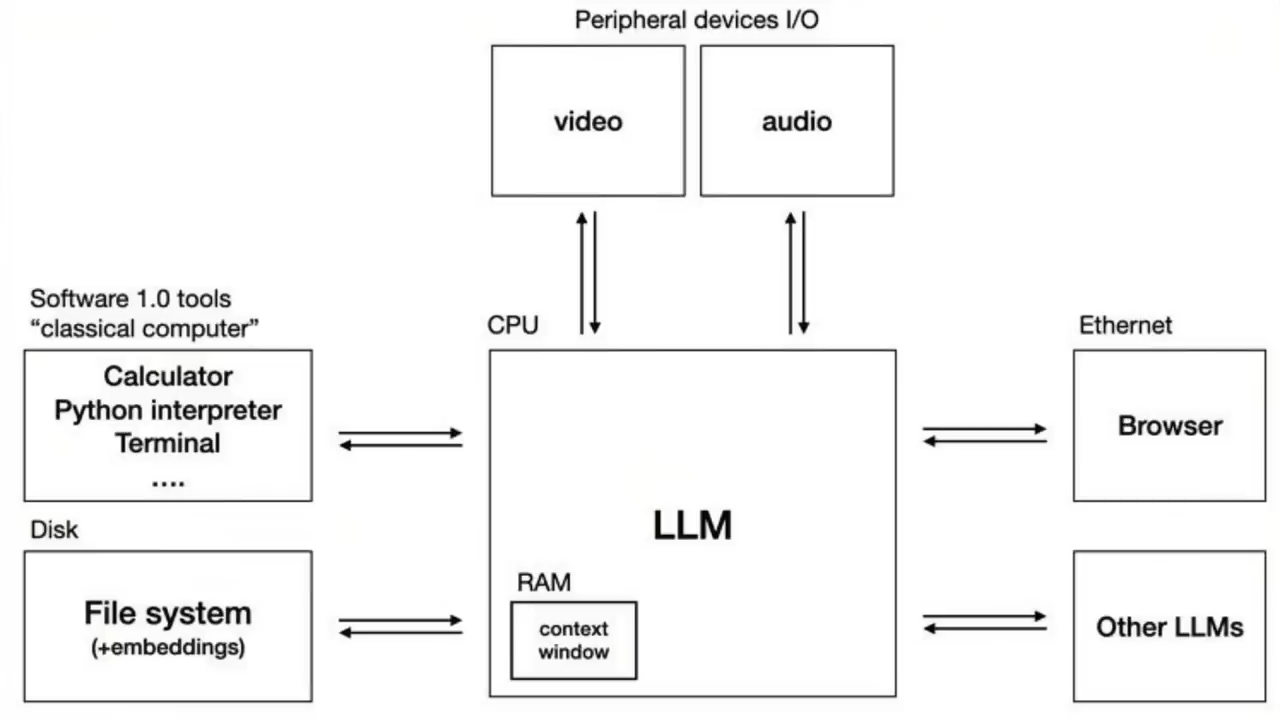
再将它跟已有的软件1.0基础设施连起来
大致上
这就是大家大致在努力的方向
我们可以给相对独立的AI代理分配高级任务
并且以各种方式进行专业化
这是非常有趣和令人兴奋的
因为不仅仅是一个代理
而是许多代理
OpenAI基本上也是在试图建立这个LLM OS
以Windows操作系统为例
它里面自带了一些默认的应用程序
比如Edge浏览器
所以,OpenAI或者其他大模型公司
也会以同样的方式推出一些默认应用程序
但也可能会形成一个生态系统
就像早期的iPhone应用程序一样
不过这需要时间
我们现在还在试图弄明白
大语言模型到底擅长什么?
它不擅长什么?
该如何使用它?
如何编程?
如何调试?
如何才能让它真正执行实际任务
以及如何对它进行监督
如何评估?
有很多事情需要搞清楚
才能让大模型与基础设施协同工作
现在PC的操作系统已经被寡头垄断了
比如Windows、Mac OS等等
大模型未来也会出现类似的情况

对开源的看法
在Andrej看来
Llama和Mixtral等模型不算是开源
他们有点像是操作系统的二进制文件
虽然可以用它们来微调模型
但是又不能完全微调模型
因为对模型微调的越多
就越可能在其他方面退化
如果想要增加模型的能力
就需要把以前的数据集和新的数据集混合在一起
重新进行训练

如果只有权重
实际上是无法做到这一点的
在整个生态中
应该有开放权重模型、开源模型和专有模型
这和我们现在的操作系统也非常相似

大语言模型的关键
对于大语言模型来说
规模绝对是第一位的
当然数据集的准备工作也很重要
有助于计算效率的提升
但是,规模是主要的决定因素
它就像事物的第一要素
就像设定了某种速度限制
如果没有规模
就无法训练一些庞大的模型
另外基础设施也很重要
大规模训练模型是极其困难的
是一个非常复杂的分布式优化问题
而且现在这方面的人才相当稀缺
模型的训练会在数以万计的GPU上运行
所有的GPU都会在不同的时间点随机失效
因此,对故障的监控和修复
实际上是一项极其艰巨的挑战
现在,如果给你一大笔钱、一大堆GPU
你还真不一定能训练出好的模型
还需要大量的专业知识
包括基础设施、算法
数据和数据处理等等
大语言模型的其他挑战
除此以外,还有很多其他的挑战
比如在算法方面,Andrej正在思考
如何将扩散模型和自回归模型统一起来
以及如何让计算机架构适应新的模型运行
其次是精度
精度已经从最初的64位双精度
下降到现在的4、5、6,甚至1.58
这取决于你读的是哪篇论文
因此,精度是一个重要的杠杆
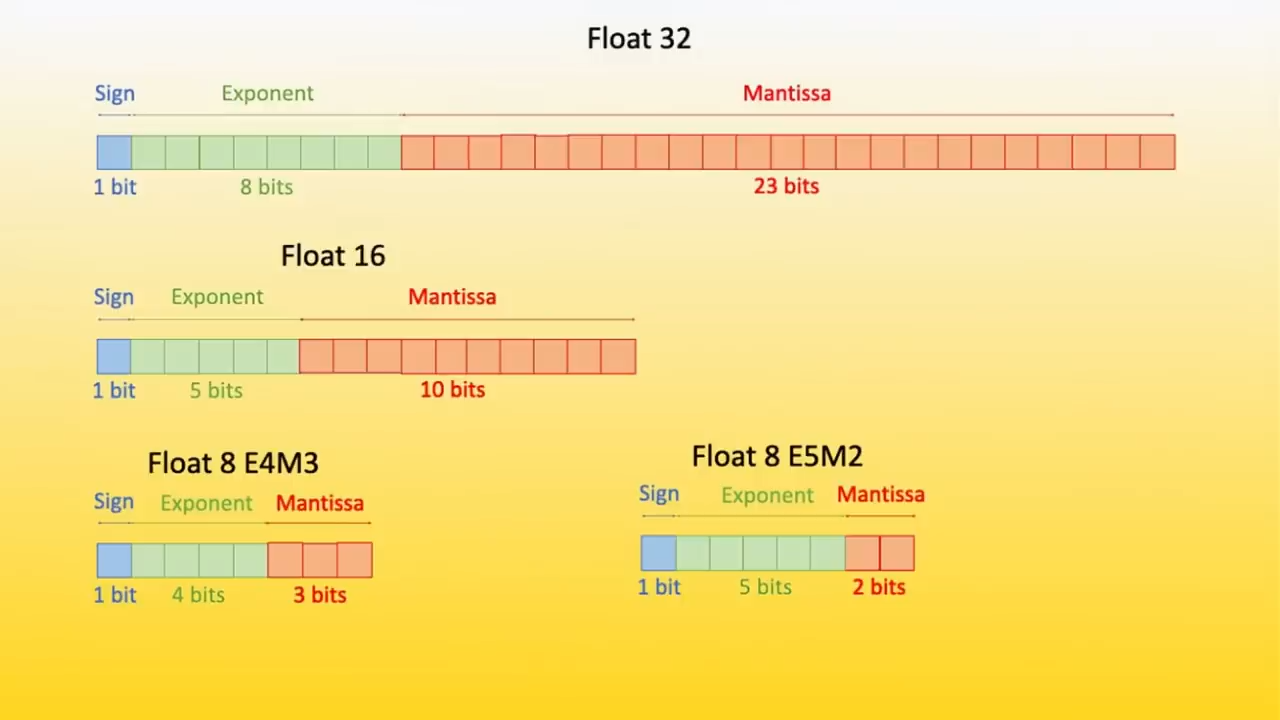
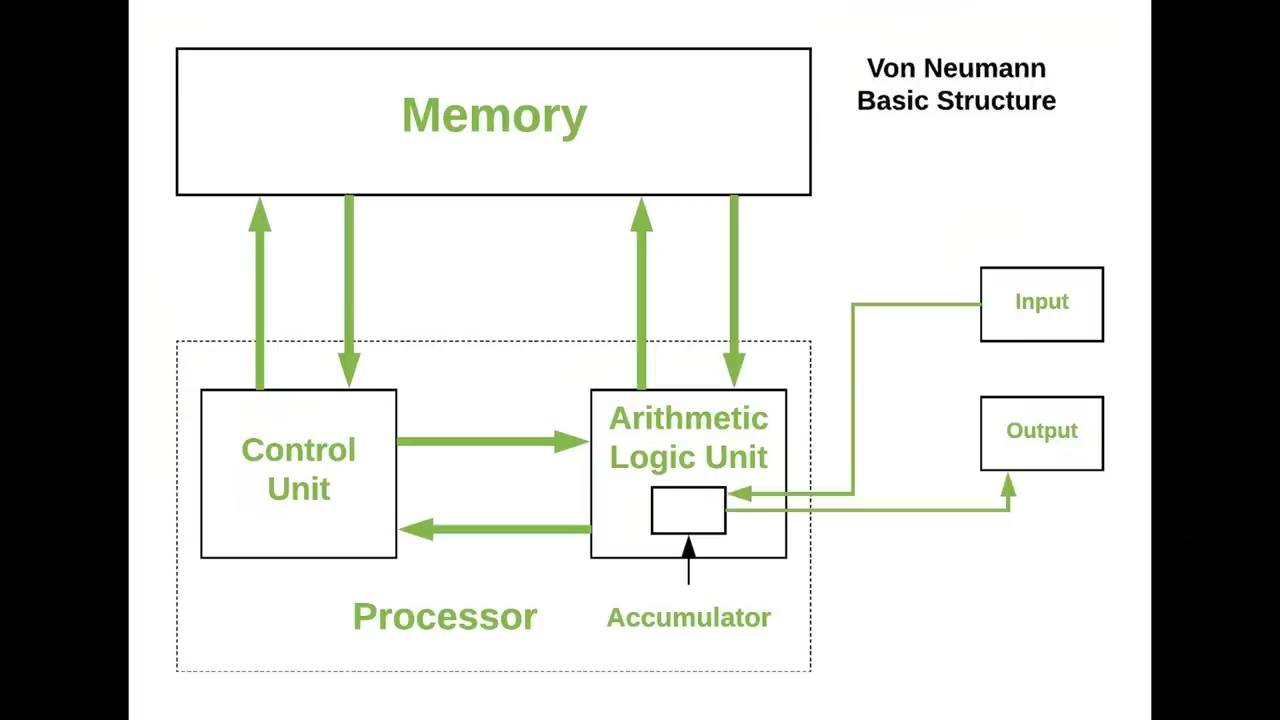
然后是稀疏性
它是另一个重要的杠杆
如今的冯-诺依曼架构的计算机
在内存和CPU之间进行大量的数据移动
这不是大脑的工作方式
所以现在运行大模型的效率低了一千到一百万倍
他认为,在计算机架构领域
应该会有一些令人兴奋的创新出现
技术团队管理
接下来
Stephanie把话题转向技术团队管理的方向

因为Andrej和埃隆马斯克、萨姆奥特曼、格雷格布罗克曼都工作过
所以重点聊了下马斯克的管理风格
马斯克经营公司的风格非常独特
而且人们很难能够理解这种独特性

第一点
他喜欢非常小的、强大的、高度技术化的团队
一般来说
公司都会喜欢团队不断壮大
但是马斯克总是喜欢反对扩大团队
因此雇人很难
而且,马斯克还很喜欢裁人
他总是希望保持一个小而强、技术含量高的团队
也基本没有管理人员
因为他们不懂技术
第二点
他喜欢充满活力的工作氛围和环境

所以在办公室里,人们经常走来走去
马斯克必须看到员工在绘制图表
在编码
他不喜欢闲散的氛围
他也很抵触开会
讨厌没有意义的会议
在马斯克看来
只要你不能对团队有所贡献
你就得走人,而这在别的公司很少见
很多大公司都表现的很宠爱员工
因此,马斯克的企业文化就是
你要尽全力做好技术工作
还要有一定的强度
最后一点很有趣、也很奇怪
那就是他与团队的联系是非常紧密的

通常情况下
公司的CEO就像一个很遥远的人
远在五层楼之上,他跟VP对话
VP再跟下属和主管对话
最终他们再跟你的经理对话
一般都是这样的
但是马斯克不是这样的
他会来到办公室和工程师们直接对话
很多会议都是50个人和埃隆在一个房间里

他会直接跟工程师对话
顶多只会花50%的时间跟VP和总监对话
在他看来,在一个小而强的团队里
工程师和代码就是一切的基础
是真相的源头
因此
作为CEO却与技术工程师有如此紧密的联系
这也是马斯克独有的风格

他经常会问工程师在研发过程遇到了什么困难
有时候他们会说
没有足够的GPU来运行这个程序
马斯克就会让GPU集群的负责人现在就把GPU集群加倍
他会让负责人每天给他发送更新进度
直到集群规模翻倍
有时负责人可能会说
我们已经制定了采购计划
但是英伟达现在没有足够的GPU
需要六个月准备
然后你就会看到马斯克眉毛一挑
随即说道
那我和黄仁勋谈谈
然后,他就解决了这个问题
外界并不知道马斯克在公司内部
解决了多少像这样琐碎又关键的问题
对一个CEO来说,这是很少见的
至少在大部分公司都不会看到
马斯克的管理风格真的非常独特、非常有效
也非常有趣
AI创业
下一个话题跟AI创业有关
Andrej认为自己虽然在一些AI顶级公司工作过
但是他最终关心的不是任何一家公司
而是更关心整个AI生态系统是否能够良性的运作
他希望创业公司能够像珊瑚礁一样
触及经济的各个角落
从而形成一个健康的、充满活力的生态系统
但是他担心
基于AGI对资本放大和集中的能力
未来会有几大巨头控制住这个游戏
他也顺便回答了观众的一个问题
就是创业公司的管理风格
取决于创始人的基因
应该始终保持一致
突然改变管理风格可能会让员工感觉很混乱
前面说到的马斯克的管理风格
可以考虑效仿和借鉴
但是关键还是要取决于创始人
强化学习
在随后与观众更多的问答中
Andrej谈到了有关于强化学习的观点
目前的AI的发展
仅仅完成了AlphaGo的第一步
也就是机器的模仿学习部分

AlphaGo的第二步是reinforcement learning
也就是强化学习
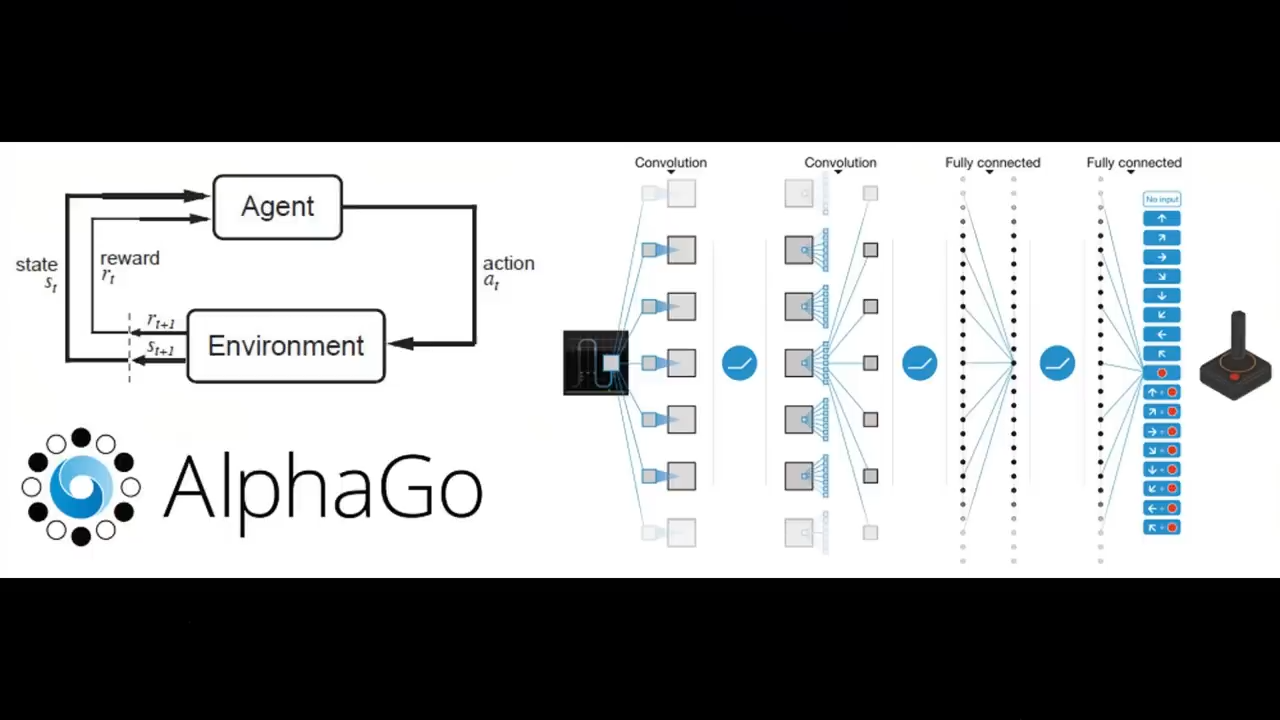
它会从根本上改变AlphaGo
但是现在其实还没做到
这是需要攻克的难题
也有很多棘手的细节
长话短说,就是AI还处在模仿阶段
就是AlphaGo的第一阶段
像ChatGPT这样的数据收集和推理
并没有我们想象中那么强大
比如,当你遇到了一个问题
提示是某种数学问题
我们就想让ChatGPT给出正确的答案
问题在于
我们的问题不只是数学问题
人类的心理与模型的心理是不同的
人类思维的难易程度与模型的难易程度也是不同的
人类在处理问题的时候
会有一个抽丝剥茧的逻辑推理过程
但是其中有些推理对模型来说很容易理解
有些推理过程则像天书一样
模型是无法理解的
从根本上说
我们需要的是让模型自己练习如何解决这些问题
它需要搞清楚什么对它有用
什么对它没用
也许它不太擅长四位数加法
所以它会退回去使用计算器
但是它需要根据自己的能力和知识
自己学习
还有一点
现在的AI仍然是在从人类的反馈中进行强化学习
但是这是一种超级弱的强化学习形式
这甚至不能算作强化学习
AlphaGo中的RLHF相当于什么?
是奖励模型么?
我称之为 "氛围检查vibe check"。
想象一下
如果你想训练一个AlphaGo的RLHF
你会给两个人两个棋盘
然后说,你更喜欢哪一个棋盘?
然后你就会使用这些标签来训练模型
并且针对这些标签进行强化学习
如果奖励模型是一个神经网络
那么你在优化模型时
就很容易过度拟合奖励模型
这样就会找到所有欺骗这个大模型的方法
AlphaGo之所以可以解决这些问题
因为他们有一个非常明确的目标函数
你可以针对它来进行强化学习
所以基于人类反馈的强化学习RLHF还远远不够
就像傻子一样
另外模仿学习也非常傻
人们需要寻找更好的方法来训练这些模型
这有点像AI模型的研究生阶段
它需要坐在一个房间里
拿着一本书,静静地质疑自己十年
举个例子
当你在学习知识并阅读教材的时候
教科书里会有一些练习
这些练习就是让你运用所学知识的提示
但是
阅读教材不是简单的从左往右读
就好像Alphago的第一阶段模仿学习一样
你还需要做练习,做笔记
你需要重新的表述,重新的构思
实际上
你在以某种方式操纵这些知识
从而让自己能够更好地学会这些知识
而在AI领域
我们还没有看到类似的东西
因此AI还处于非常早期的阶段
Transformer架构
当问到Transformer架构的发展时
Andrej回答到
在Transformer问世之前
他曾经一度以为神经网络会疯狂地分化
但是事实并非如此,甚至完全相反
它是完全统一的模型
从历史来看
Transformer应该不会是神经网络的终点
在某种程度上
Transformer是为GPU而设计的
可以说
这是Transformer论文中的一大突破
也是他们的出发点
即我们想要一个从根本上来说非常善于并行化的架构
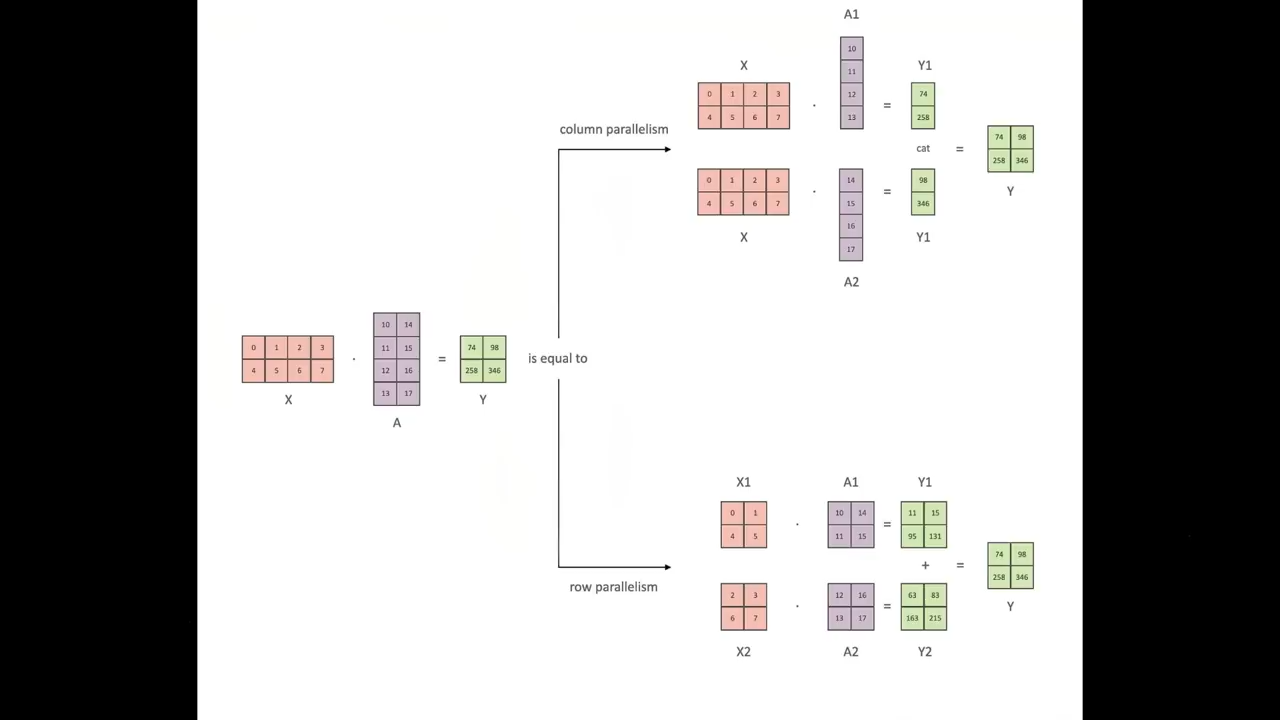
由于循环神经网络具有顺序依赖性
而Transformer则通过注意力打破了这一限制

但是这还是一种针对于现有硬件的算法
因此未来很可能还会有变化
不得不说,Transformer自从问世以来
已经被证明有非凡的适应能力
所以最初的Transformer和我们现在用的并没有太大区别
模型开源
最后
Andrej聊了下自己对于模型开源的看法
虽然Meta等公司有能力大规模训练开源模型
但是这并不是他们的核心业务
也不是他们的摇钱树
因此
他们有动机去发布其中的一些模型
从而增强整个生态系统的能力
这样他们就能借鉴所有创新的点子
但是到目前为止
他们只做到了开放权重的模式
应该更进一步
如果想让这个生态变得更好
一个重要的方面就是AI是否是开放的、可触及的
正所谓第一步,设计产品
第二,加速发展
很多人都在做第一件事
也就是设计更多的AI产品
但是很少有人关注创新的加速发展
在AI领域,我们还都是新手
都在试图了解AI是如何工作的
我们需要加强合作
弄清楚如何有效地使用它
所以
大家应该能够更加开放地分享心得
比如这些东西是如何训练的
哪些有效,哪些无效
这样我们才能互相从彼此身上学到更多
好了
以上就是Andrej Karpathy这次访谈的主要内容
强化学习
无独有偶,Andrej对强化学习的观点
与Mistral CEO的观点一致

就是现在的基于人类反馈的强化学习还很弱
离AI的自主学习阶段还差的很远
下一个阶段应该是如何大力发展基于AI反馈的强化学习RLAIF了
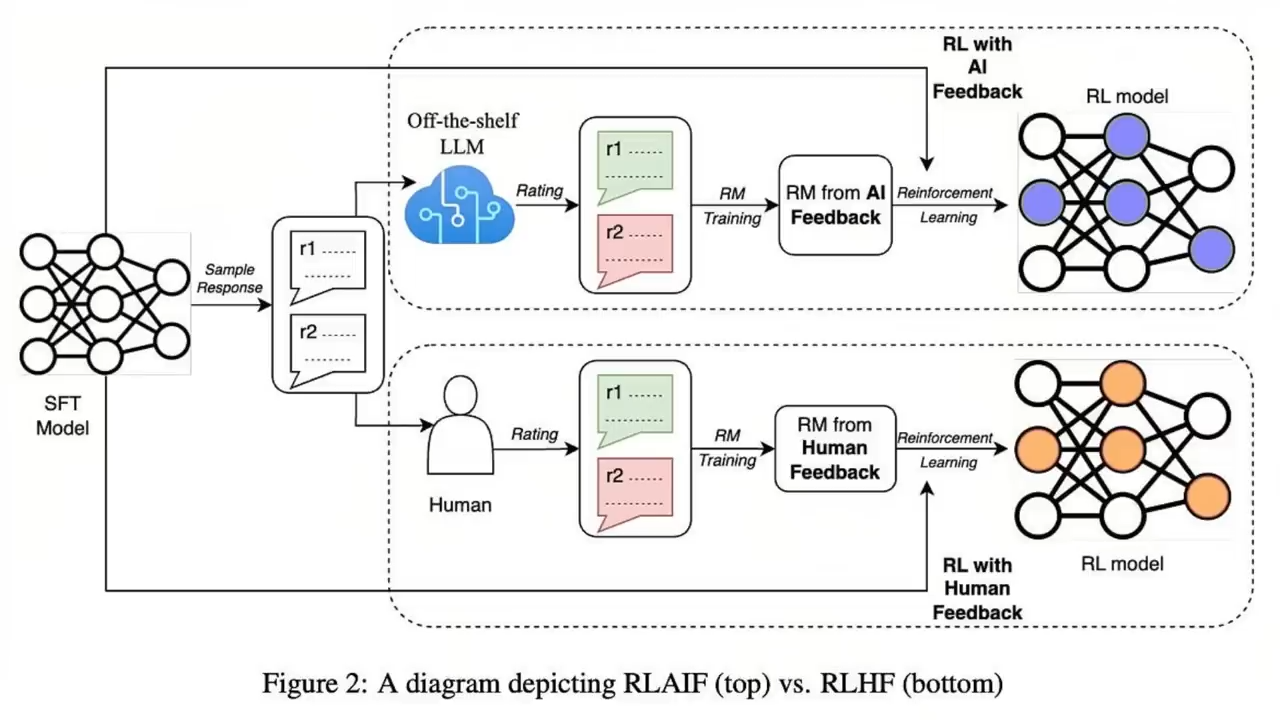
到那个时候
可能才是AI真正的宇宙大爆炸时刻
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









