






#在故障的数据库节点执行
repmgr node rejoin -h ${主库IP} -d esrep -U esrep -p ${主库port} [--force-rewind] [--no-check-wal]
#可以执行简化后的命令
kbha -A rejoin -h ${主库IP}
参数说明:
--force-rewind,当故障数据库和当前主库数据分歧后,需要指定此参数使用sys_rewind使得故障数据库和新主库保持数据一致;
--no-check-wal,一般情况下不允许时间线高的数据库恢复为时间线低的主库的备库,此选项可以忽略时间线和lsn检查,必须和--force-rewind一起使用;
1.Node101 由于数据库宕机,primary 切换到 node102

2.执行命令将 原主库node101 重新加入集群
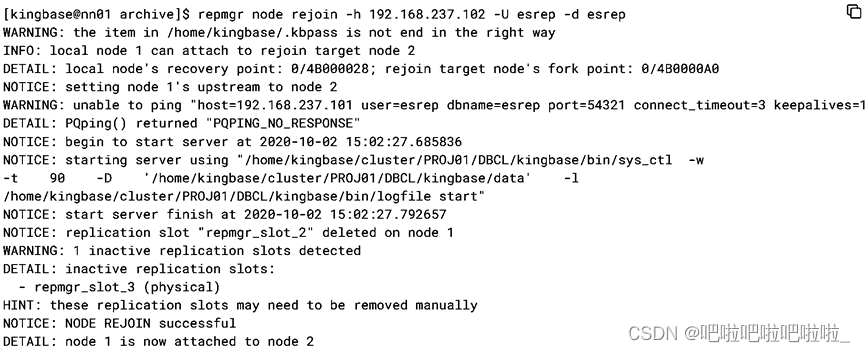
3.确认集群状态
















 2101
2101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









