







创建项目:

出现如下文件
在spiders/ 创建文件 *.py 文件名随意
来分析下页面

以上我们得知需要的内容


我们使用CSS选择器来爬取内容
我们来分析下页面
可以看都都是在一个 ol下的所有li 里面 总共是25个,这个就是每页的25条我们需要的信息


每个li下面 都有个 div class="item" 。 以此为基础爬取个总的
打开我们的 scrapy CSS调试器 scrapy shell 后面跟的是你要爬取的网页内容
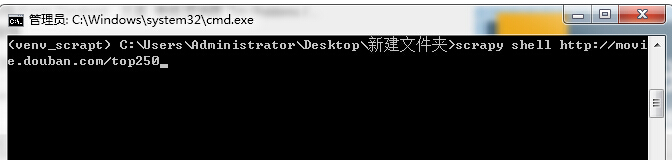

这里报个403,请求被拒绝。来添加下请求头
打开settings.py 文件里面找到

USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'重新打开一次 200 而后开始调试,首先获取所有的div.item
![]()
可以看到我们获取了25条信息,进行遍历 一个一个内容的取出来

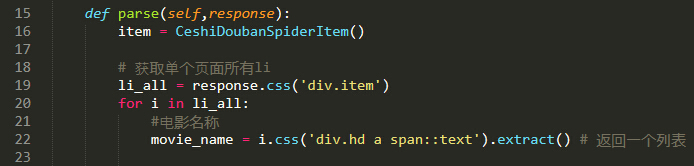
这一个一个的css调试找寻就不再操作,直接上代码 个人可自行体验查找
def parse(self,response):
item = CeshiDoubanSpiderItem()
# 获取单个页面所有li
li_all = response.css('div.item')
for i in li_all:
#电影名称
movie_name = i.css('div.hd a span::text').extract() # 返回一个列表
title = ''
for ii in movie_name:
title += ii.replace('\n','').replace(' ','').replace('\xa0',' ')
#导演
director_actor = i.css('div.bd p::text').extract()[0].replace('\n','').replace(' ','').replace('\xa0',' ') + i.css('div.bd p::text').extract()[1].replace('\n','').replace(' ','').replace('\xa0',' ')
# 评分
score = i.css('div.star span::text').extract()[0]
#评价
evaluate = i.css('div.star span::text').extract()[1]
#名言
language = i.css('div.bd p span::text').extract_first()
item['title'] = title
item['director_actor'] = director_actor
item['score'] = score
item['evaluate'] = evaluate
item['language'] = language一页的内容我们获取到了 就是上面说的五项
而后是翻页相
![]()
前面添加了个url,针对下面获取的href 合并后发送请求

#下一页
new_pape = response.css('span.next a::attr(href)').extract_first()
if new_pape:
print('*************' * 10)
yield Request(self.url + new_pape, callback= self.parse)打开 settings.py 输入一下内容来保存文件
本地路径
FEED_URI = u'file://C:/Users/Administrator/Desktop/新建文件夹/ceshi_douban_spider/ceshi_douban_spider/douban.csv'
FEED_FORMAT = 'CSV'运行
scrapy crawl itemdouban 















 1498
1498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









