







solr概述及特点:

1. 安装solr
第一步: 配置Linux的环境
- 安装JDK (本教程使用的是JDK1.8)(略)
- 安装Tomcat (本教程使用的是Tomcat 8)(略)
- 安装Mysql (本教程使用的是Mysql 5.1.7)(略)
第二步: 下载solr的版本
-
下载最新版可以直接访问 链接: http://lucene.apache.org/solr/downloads.html -
下载老版本可以直接访问 链接: http://archive.apache.org/dist/lucene/solr/ - 本教程使用的 4.10.2 版本,可以在老版本链接里下载(如果觉的下载速度很慢,可以通过百度网盘下载)
-
【百度网盘下载】 链接: https://pan.baidu.com/s/1n1Y16R-Z2Ca24fiYVlnmpw 密码:pazj
-
- 将下载好的版本解压,然后打开解压后的文件:

- 将下载好的版本解压,然后打开解压后的文件:
-
- 打开example文件夹:(重点是被红色圈起来的目录)

solr目录:包含全文检索要存储的索引数据以及相关的一些配置文件。
solr-webapp和webapps:其实包含的是一样的内容,都是Solr的内置Web应用,我们可以通过Http请求 访问该应用,实现对Solr服务的管理和访问;
(solr-webapp用于存放运行时解压后的solr.war)
- 打开example文件夹:(重点是被红色圈起来的目录)
第三步:启动Solr
solr的服务本质是一个web服务,因此提供了war包,我们只要把war包加载到web容器中即可运行。 可以使用内置的jetty容器,或者是tomcat容器;
方式1:Jetty启动
步骤:
- 1.进入solr-4.10.2/example目录
- 2.打开命令行,执行java –jar start.jar命令,即可启动Solr服务
- 3.打开浏览器,通过http://localhost:8983/solr或http://ip:8983/solr来访问Solr管理页面。
(Jetty服务的默认端口是8983)
方式2:tomcat启动 (重点)
- 1.部署Web服务,将solr-4.10.2/example/webapps/solr.war文件复制到Tomcat下的webapps目录中,解压solr.war包,并删除解压前的solr.war文件;

- 2.要启动solr需要在Tomcat中添加相关的jar包:
【百度网盘下载】链接: https://pan.baidu.com/s/15PE4B9-XoiVKFCLh32SB0A 密码:q0cu

将上图两个文件夹拷贝到 Tomcat/webapps/solr/WEB-INF/lib下:
- 3.创建索引库:
这个索引库可以创建在任何地方,只要知道路径即可(路径不要有中文),我这是在Tomcat目录下创建
solrhome目录。
目录创建后,将原来solr-4.10.2/example/solr里的文件都复制到solrhome目录下;

复制好之后,那么solrhome就是索引库了,现在我们要去配置索引库地址。配置索引库地址有两种方式:
第一种方式:
在xml里配置,打开Tomcat/weapps/solr/WEB-INF/web.xml
修改前:

修改后:

第二种方式:
打开Tomcat/bin/catalina.bat文件(可以用记事本打开)
添加一条配置信息,指向我们的索引库及配置目录:
set "JAVA_OPTS=-Dsolr.solr.home=/usr/local/src/tomcat-8.5.27/solrhome"

第四步:启动solr
进入Tomcat/bin目录,输入命令:./startup.sh 启动tomcat服务器
打开浏览器,访问 http://localhost:8080/solr 进入Solr管理页面,我这是装在服务器上,没有装在本机,所以通过服务器的ip地址访问;




添加索引数据



Core详解

目录结构
 core.properties主要记录的是索引库的属性,比如:名称。
core.properties主要记录的是索引库的属性,比如:名称。
conf目录中有两个非常重要的配置文件:schema.xml和solrconfig.xml

修改索引库的名字
打开core.properties
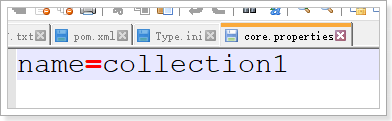
这显然是索引库的名称,索引库名称一般要跟文件夹名称一致,这里都是collection1。
name=collection1 改成 name=core1 ,并且把索引库文件夹名(collection1)改成core1。

添加新的Core
我们无法在Solr管理界面添加Core:

每个core都有自己独立的文件夹。我们可以直接将core1复制一份在当前文件夹下,把复制后的文件夹名改成core2,并且修改core2文件夹下core.properties文件,将 name=core1 改成 name=core2 改好之后,重启tomcat,打开Solr管理界面:

修改schema.xml文件
Solr中会提前对文档中的字段进行定义,并且在schema.xml中对这些字段的属性进行约束,例如:字段数据类型、字段是否索引、是否存储、是否分词等等

属性及含义:
-
name:字段名称
-
type:字段类型,指向的是本文件中的
<fieldType>标签 -
indexed:是否创建索引
-
stored:是否被存储
-
multiValued:是否可以有多个值,如果字段可以有多个值,设置为true
注意:在本文件中,有两个字段是Solr自带的字段,绝对不要删除:_version节点和_root节点

通过FieldType指定的数据类型
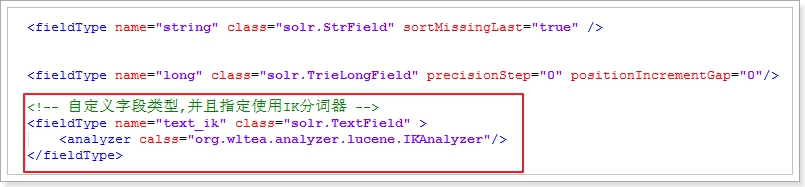
标签属性:
- name:字段类型的名称,可以自定义,
<field>标签的type属性可以引用该字段,来指定数据类型 - class:字段类型对应的Solr中的类。StrField可索引不可分词。TextField字段可索引,可以分词,所以需要指定分词器
- 子标签
<analyzer>:TextField类型的字段,需要指定分词器,这个子标签用来指定分词器类型
唯一主键:
Lucene中本来是没有主键的。删除和修改都需要根据词条进行匹配。而Solr却可以设置一个字段为唯一主键,这样增删改操作都可以根据主键来进行

引入IK分词器
-
1.引入IK分词器的jar包(我们之前已经引入过了(之前导入的lib目录里已经包含IK分词起的jar包了));
-
2.在schemal.xml中自定义fieldType,引入IK分词器
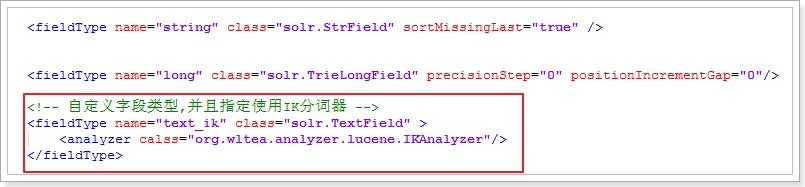
class = “org.wltea.analyzer.lucene.IKAnalyzer” -
3.让字段使用我们自定义数据类型,引入IK分词器

可以正确分词了:

完整的配置:
这里配置只是简单的添加了几个要索引的字段,如果在开发中,要索引的字段很多,可以根据情况自己添加;
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5">
<!-- solr的系统属性,不能删除 -->
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="_root_" type="string" indexed="true" stored="false"/>
<!-- 字段,name:字段名称;type:字段类型;indexed:是否创建索引;stored:是否保存;multivalued:是否允许有多个值 -->
<field name="id" type="long" indexed="true" stored="true" required="true" multiValued="false" />
<field name="title" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<field name="price" type="long" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>
<uniqueKey>id</uniqueKey>
<!-- 不分词字段类型 -->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<!-- 可分词字段类型 -->
<fieldType name="text_ik" class="solr.TextField" >
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType>
</schema>
修改solrconfig.xml文件
这个配置文件主要配置跟索引库和请求处理相关的配置。solr服务的优化主要通过这个配置文件进行:
solrconfig.xml配置文件支持使用变量,格式如下:${propertyname[:option default value]}冒号后面的是缺省值,冒号前面的值可以来自于:JVM的-D参数,比如:bin/solr start -Dpropertyname=none
<lib/>标签:
-
用途:配置插件依赖的jar包
-
注意事项:
-
如果引入多个jar包,要注意包和包的依赖关系,被依赖的包配置在前面
-
这里的jar包目录如果是相对路径,那么是相对于core所在目录
例如,在配置文件中默认有以下配置:这些是Solr中插件所依赖的Jar包

我们发现这些配置是在找两个文件夹下的jar包:contrib和dist。这两个文件夹其实在Solr的安装目录中有

而<lib dir="">标签中的dir是相对目录,默认相对于core目录。我们的core在Tomcat\solrhome位置,我们把这两个文件夹复制到solrhome下

然后修改相对路径,只留下…/即可

<requestHandler/>标签
- 用途:配置Solr处理各种请求(搜索/select、更新索引等)的各种参数
- 主要参数:
- name:请求类型,例如:select、update等
- class:处理请求的类
- initParams:可选,引用
<initParams>标签中的配置 <lst name="defaults">:定义各种缺省的配置,比如缺省的parser、缺省返回条数- 例子: 负责搜索请求的Handler

这里有一个默认选项:rows=10 ,就是设置默认查10条数据;
<str name="df"> text </str>这个是设置默认搜索的字段为:text 在这里我们可以设置为title,因为我们没有text字段;在开发中,可以自行设置;

数据导入插件
在Solr的管理界面的Dataimport功能里没有导入数据的插件,这时候我们需要配置一下导入插件;

打开配置文件 Tomcat/solrhome/collection1/conf/solrconfig.xml
-
添加依赖插件:
<lib dir="../dist/" regex="solr-dataimporthandler-\d.*\.jar"/> -
配置导入数据处理请求的Handler,并指定该Handler的数据库配置文件名称

可以放在跟标签下的任意位置;
上述提到【数据库配置文件】我们需要创建xml文件,里面填写数据库信息;
在Tomcat/solrhome/collection1/conf目录下创建 db-data-config.xml (文件名要上面配置的名称一样)
并输入下列内容:
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://ip:3306/solr"
user="root"
password="root"/>
<document>
<!--name 随便命名;query 查询语句 items:solr数据库下的items表-->
<entity name="item" query="select id,title,price from items"></entity>
</document>
</dataConfig>
dataSource:用来配置数据库的连接信息;
entity:用来配置文档的数据来源,其实就是SQL语句,查询结果会自动匹配到索引库中;
数据库的连接信息设置为你自己的数据库信息;
因为要连接数据库,所以这里还要添加数据驱动jar包
【百度网盘下载】链接:https://pan.baidu.com/s/1RWAIRcWU-iLgV9qiuDycOQ 密码:c6jl
下载好之后放到 Tomcat/webapps/solr/WEB-INF/lib 下;
在Mysql中新建数据库solr,并将测试数据导入;
INSERT INTO `items` VALUES (1, '华为 荣耀 畅玩6X 4GB 32GB 全网通4G手机 高配版 铂光金', 1399);
INSERT INTO `items` VALUES (2, '一加手机3T (A3010) 6GB+64GB 枪灰版 全网通 双卡双待 移动联通电信4G手机', 2699);
INSERT INTO `items` VALUES (3, 'OPPO R9s 全网通4G+64G 双卡双待手机 金色', 2799);
INSERT INTO `items` VALUES (4, '华为 荣耀 畅玩5C 全网通 高配版 3GB+32GB 落日金 移动联通电信4G手机 双卡双待', 1199);
INSERT INTO `items` VALUES (5, 'VOTO Xplay5 移动4G 双卡双待 智能手机 金色', 799);
INSERT INTO `items` VALUES (6, '华为 荣耀 V8 全网通 高配版 4GB+64GB 典雅灰 移动联通电信4G手机 双卡双待双通', 2599);
INSERT INTO `items` VALUES (7, 'vivo X9 全网通 4GB+64GB 移动联通电信4G手机 双卡双待 玫瑰金', 2798);
INSERT INTO `items` VALUES (8, 'Apple iPhone 7 Plus (A1661) 32G 黑色 移动联通电信4G手机', 6399);
INSERT INTO `items` VALUES (9, '小米5s 全网通 高配版 3GB内存 64GB ROM 哑光金 移动联通电信4G手机', 1999);
INSERT INTO `items` VALUES (10, 'Apple iPhone 7 (A1660) 128G 亮黑色 移动联通电信4G手机', 5899);
INSERT INTO `items` VALUES (11, '华为 荣耀 NOTE 8 4GB+64GB 全网通4G手机 冰河银, 2K大屏,长续航,4500毫安电池', 2499);
INSERT INTO `items` VALUES (12, 'OPPO R9s Plus 6GB+64GB内存版 全网通4G手机 双卡双待 玫瑰金, 6英寸大屏,1300万像素,光学防抖', 3499);
INSERT INTO `items` VALUES (13, '华为 Mate 9 4GB+64GB版 香槟金 移动联通电信4G手机 双卡双待,麒麟960芯片!第二代徕卡双摄像头', 3899);
INSERT INTO `items` VALUES (14, 'Apple iPhone 6s (A1700) 32G 深空灰色 移动联通电信4G手机', 4299);
导入好之后,我们就要启动Tomcat,并访问solr;
如果出现这个异常页面

我们只需要在solrconfig.xml文件中把这几行删除,或者注释掉即可;

出现这种情况是因为:这个组件底层会用到id属性,它会认为id是String类型,但是我们数据库中id是bigint类型对应schema.xml配置里是long类型,所以会报错;
然后再次重启Tomcat就可以了

查询索引数据,可以查到我们数据库的信息,说明导入成功:

完整的solrconfig.xml配置文件:
<?xml version="1.0" encoding="UTF-8" ?>
<config>
<luceneMatchVersion>4.10.2</luceneMatchVersion>
<lib dir="../contrib/extraction/lib" regex=".*\.jar" />
<lib dir="../dist/" regex="solr-cell-\d.*\.jar" />
<lib dir="../contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="../dist/" regex="solr-clustering-\d.*\.jar" />
<lib dir="../contrib/langid/lib/" regex=".*\.jar" />
<lib dir="../dist/" regex="solr-langid-\d.*\.jar" />
<lib dir="../contrib/velocity/lib" regex=".*\.jar" />
<lib dir="../dist/" regex="solr-velocity-\d.*\.jar" />
<!-- 处理文件导入的插件依赖-->
<lib dir="../dist/" regex="solr-dataimporthandler-\d.*\.jar" />
<!-- 处理文件导入的插件Handler配置信息 -->
<requestHandler name="/import" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<!-- 这个是插件Handler的配置文件名称 -->
<str name="config">db-data-config.xml</str>
</lst>
</requestHandler>
<dataDir>${solr.data.dir:}</dataDir>
<directoryFactory name="DirectoryFactory"
class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}">
<!-- These will be used if you are using the solr.HdfsDirectoryFactory,
otherwise they will be ignored. If you don't plan on using hdfs,
you can safely remove this section. -->
<!-- The root directory that collection data should be written to. -->
<str name="solr.hdfs.home">${solr.hdfs.home:}</str>
<!-- The hadoop configuration files to use for the hdfs client. -->
<str name="solr.hdfs.confdir">${solr.hdfs.confdir:}</str>
<!-- Enable/Disable the hdfs cache. -->
<str name="solr.hdfs.blockcache.enabled">${solr.hdfs.blockcache.enabled:true}</str>
<!-- Enable/Disable using one global cache for all SolrCores.
The settings used will be from the first HdfsDirectoryFactory created. -->
<str name="solr.hdfs.blockcache.global">${solr.hdfs.blockcache.global:true}</str>
</directoryFactory>
<codecFactory class="solr.SchemaCodecFactory"/>
<schemaFactory class="ClassicIndexSchemaFactory"/>
<indexConfig>
<lockType>${solr.lock.type:native}</lockType>
<infoStream>true</infoStream>
<checkIntegrityAtMerge>false</checkIntegrityAtMerge>
</indexConfig>
<jmx />
<updateHandler class="solr.DirectUpdateHandler2">
<updateLog>
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
<autoCommit>
<maxTime>${solr.autoCommit.maxTime:15000}</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>
<autoSoftCommit>
<maxTime>${solr.autoSoftCommit.maxTime:-1}</maxTime>
</autoSoftCommit>
</updateHandler>
<query>
<maxBooleanClauses>1024</maxBooleanClauses>
<filterCache class="solr.FastLRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
<queryResultCache class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
<documentCache class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
<!-- custom cache currently used by block join -->
<cache name="perSegFilter"
class="solr.search.LRUCache"
size="10"
initialSize="0"
autowarmCount="10"
regenerator="solr.NoOpRegenerator" />
<enableLazyFieldLoading>true</enableLazyFieldLoading>
<queryResultWindowSize>20</queryResultWindowSize>
<queryResultMaxDocsCached>200</queryResultMaxDocsCached>
<listener event="newSearcher" class="solr.QuerySenderListener">
<arr name="queries">
</arr>
</listener>
<listener event="firstSearcher" class="solr.QuerySenderListener">
<arr name="queries">
<lst>
<str name="q">static firstSearcher warming in solrconfig.xml</str>
</lst>
</arr>
</listener>
<useColdSearcher>false</useColdSearcher>
<maxWarmingSearchers>2</maxWarmingSearchers>
</query>
<requestDispatcher handleSelect="false" >
<requestParsers enableRemoteStreaming="true"
multipartUploadLimitInKB="2048000"
formdataUploadLimitInKB="2048"
addHttpRequestToContext="false"/>
<httpCaching never304="true" />
</requestDispatcher>
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">title</str>
</lst>
</requestHandler>
<!-- A request handler that returns indented JSON by default -->
<requestHandler name="/query" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="wt">json</str>
<str name="indent">true</str>
<str name="df">text</str>
</lst>
</requestHandler>
<requestHandler name="/get" class="solr.RealTimeGetHandler">
<lst name="defaults">
<str name="omitHeader">true</str>
<str name="wt">json</str>
<str name="indent">true</str>
</lst>
</requestHandler>
<requestHandler name="/export" class="solr.SearchHandler">
<lst name="invariants">
<str name="rq">{!xport}</str>
<str name="wt">xsort</str>
<str name="distrib">false</str>
</lst>
<arr name="components">
<str>query</str>
</arr>
</requestHandler>
<requestHandler name="/browse" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<!-- VelocityResponseWriter settings -->
<str name="wt">velocity</str>
<str name="v.template">browse</str>
<str name="v.layout">layout</str>
<str name="title">Solritas</str>
<!-- Query settings -->
<str name="defType">edismax</str>
<str name="qf">
text^0.5 features^1.0 name^1.2 sku^1.5 id^10.0 manu^1.1 cat^1.4
title^10.0 description^5.0 keywords^5.0 author^2.0 resourcename^1.0
</str>
<str name="df">text</str>
<str name="mm">100%</str>
<str name="q.alt">*:*</str>
<str name="rows">10</str>
<str name="fl">*,score</str>
<str name="mlt.qf">
text^0.5 features^1.0 name^1.2 sku^1.5 id^10.0 manu^1.1 cat^1.4
title^10.0 description^5.0 keywords^5.0 author^2.0 resourcename^1.0
</str>
<str name="mlt.fl">text,features,name,sku,id,manu,cat,title,description,keywords,author,resourcename</str>
<int name="mlt.count">3</int>
<!-- Faceting defaults -->
<str name="facet">on</str>
<str name="facet.missing">true</str>
<str name="facet.field">cat</str>
<str name="facet.field">manu_exact</str>
<str name="facet.field">content_type</str>
<str name="facet.field">author_s</str>
<str name="facet.query">ipod</str>
<str name="facet.query">GB</str>
<str name="facet.mincount">1</str>
<str name="facet.pivot">cat,inStock</str>
<str name="facet.range.other">after</str>
<str name="facet.range">price</str>
<int name="f.price.facet.range.start">0</int>
<int name="f.price.facet.range.end">600</int>
<int name="f.price.facet.range.gap">50</int>
<str name="facet.range">popularity</str>
<int name="f.popularity.facet.range.start">0</int>
<int name="f.popularity.facet.range.end">10</int>
<int name="f.popularity.facet.range.gap">3</int>
<str name="facet.range">manufacturedate_dt</str>
<str name="f.manufacturedate_dt.facet.range.start">NOW/YEAR-10YEARS</str>
<str name="f.manufacturedate_dt.facet.range.end">NOW</str>
<str name="f.manufacturedate_dt.facet.range.gap">+1YEAR</str>
<str name="f.manufacturedate_dt.facet.range.other">before</str>
<str name="f.manufacturedate_dt.facet.range.other">after</str>
<!-- Highlighting defaults -->
<str name="hl">on</str>
<str name="hl.fl">content features title name</str>
<str name="hl.preserveMulti">true</str>
<str name="hl.encoder">html</str>
<str name="hl.simple.pre"><b></str>
<str name="hl.simple.post"></b></str>
<str name="f.title.hl.fragsize">0</str>
<str name="f.title.hl.alternateField">title</str>
<str name="f.name.hl.fragsize">0</str>
<str name="f.name.hl.alternateField">name</str>
<str name="f.content.hl.snippets">3</str>
<str name="f.content.hl.fragsize">200</str>
<str name="f.content.hl.alternateField">content</str>
<str name="f.content.hl.maxAlternateFieldLength">750</str>
<!-- Spell checking defaults -->
<str name="spellcheck">on</str>
<str name="spellcheck.extendedResults">false</str>
<str name="spellcheck.count">5</str>
<str name="spellcheck.alternativeTermCount">2</str>
<str name="spellcheck.maxResultsForSuggest">5</str>
<str name="spellcheck.collate">true</str>
<str name="spellcheck.collateExtendedResults">true</str>
<str name="spellcheck.maxCollationTries">5</str>
<str name="spellcheck.maxCollations">3</str>
</lst>
<!-- append spellchecking to our list of components -->
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
<requestHandler name="/update" class="solr.UpdateRequestHandler">
</requestHandler>
<requestHandler name="/update/extract"
startup="lazy"
class="solr.extraction.ExtractingRequestHandler" >
<lst name="defaults">
<str name="lowernames">true</str>
<str name="uprefix">ignored_</str>
<!-- capture link hrefs but ignore div attributes -->
<str name="captureAttr">true</str>
<str name="fmap.a">links</str>
<str name="fmap.div">ignored_</str>
</lst>
</requestHandler>
<requestHandler name="/analysis/field"
startup="lazy"
class="solr.FieldAnalysisRequestHandler" />
<requestHandler name="/analysis/document"
class="solr.DocumentAnalysisRequestHandler"
startup="lazy" />
<requestHandler name="/admin/"
class="solr.admin.AdminHandlers" />
<!-- ping/healthcheck -->
<requestHandler name="/admin/ping" class="solr.PingRequestHandler">
<lst name="invariants">
<str name="q">solrpingquery</str>
</lst>
<lst name="defaults">
<str name="echoParams">all</str>
</lst>
</requestHandler>
<!-- Echo the request contents back to the client -->
<requestHandler name="/debug/dump" class="solr.DumpRequestHandler" >
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="echoHandler">true</str>
</lst>
</requestHandler>
<requestHandler name="/replication" class="solr.ReplicationHandler" >
</requestHandler>
ponent name="spellcheck" class="solr.SpellCheckComponent">
<str name="queryAnalyzerFieldType">text_general</str>
<!-- a spellchecker built from a field of the main index -->
<lst name="spellchecker">
<str name="name">default</str>
<str name="field">text</str>
<str name="classname">solr.DirectSolrSpellChecker</str>
<!-- the spellcheck distance measure used, the default is the internal levenshtein -->
<str name="distanceMeasure">internal</str>
<!-- minimum accuracy needed to be considered a valid spellcheck suggestion -->
<float name="accuracy">0.5</float>
<!-- the maximum #edits we consider when enumerating terms: can be 1 or 2 -->
<int name="maxEdits">2</int>
<!-- the minimum shared prefix when enumerating terms -->
<int name="minPrefix">1</int>
<!-- maximum number of inspections per result. -->
<int name="maxInspections">5</int>
<!-- minimum length of a query term to be considered for correction -->
<int name="minQueryLength">4</int>
<!-- maximum threshold of documents a query term can appear to be considered for correction -->
<float name="maxQueryFrequency">0.01</float>
<!-- uncomment this to require suggestions to occur in 1% of the documents
<float name="thresholdTokenFrequency">.01</float>
-->
</lst>
<!-- a spellchecker that can break or combine words. See "/spell" handler below for usage -->
<lst name="spellchecker">
<str name="name">wordbreak</str>
<str name="classname">solr.WordBreakSolrSpellChecker</str>
<str name="field">name</str>
<str name="combineWords">true</str>
<str name="breakWords">true</str>
<int name="maxChanges">10</int>
</lst>
</searchComponent>
<requestHandler name="/spell" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="df">text</str>
<str name="spellcheck.dictionary">default</str>
<str name="spellcheck.dictionary">wordbreak</str>
<str name="spellcheck">on</str>
<str name="spellcheck.extendedResults">true</str>
<str name="spellcheck.count">10</str>
<str name="spellcheck.alternativeTermCount">5</str>
<str name="spellcheck.maxResultsForSuggest">5</str>
<str name="spellcheck.collate">true</str>
<str name="spellcheck.collateExtendedResults">true</str>
<str name="spellcheck.maxCollationTries">10</str>
<str name="spellcheck.maxCollations">5</str>
</lst>
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<str name="name">mySuggester</str>
<str name="lookupImpl">FuzzyLookupFactory</str> <!-- org.apache.solr.spelling.suggest.fst -->
<str name="dictionaryImpl">DocumentDictionaryFactory</str> <!-- org.apache.solr.spelling.suggest.HighFrequencyDictionaryFactory -->
<str name="field">cat</str>
<str name="weightField">price</str>
<str name="suggestAnalyzerFieldType">string</str>
</lst>
</searchComponent>
<requestHandler name="/suggest" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="suggest">true</str>
<str name="suggest.count">10</str>
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>
<!-- Term Vector Component
http://wiki.apache.org/solr/TermVectorComponent
-->
<searchComponent name="tvComponent" class="solr.TermVectorComponent"/>
<requestHandler name="/tvrh" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="df">text</str>
<bool name="tv">true</bool>
</lst>
<arr name="last-components">
<str>tvComponent</str>
</arr>
</requestHandler>
<searchComponent name="clustering"
enable="${solr.clustering.enabled:false}"
class="solr.clustering.ClusteringComponent" >
<lst name="engine">
<str name="name">lingo</str>
<str name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm</str>
<str name="carrot.resourcesDir">clustering/carrot2</str>
</lst>
<!-- An example definition for the STC clustering algorithm. -->
<lst name="engine">
<str name="name">stc</str>
<str name="carrot.algorithm">org.carrot2.clustering.stc.STCClusteringAlgorithm</str>
</lst>
<!-- An example definition for the bisecting kmeans clustering algorithm. -->
<lst name="engine">
<str name="name">kmeans</str>
<str name="carrot.algorithm">org.carrot2.clustering.kmeans.BisectingKMeansClusteringAlgorithm</str>
</lst>
</searchComponent>
<requestHandler name="/clustering"
startup="lazy"
enable="${solr.clustering.enabled:false}"
class="solr.SearchHandler">
<lst name="defaults">
<bool name="clustering">true</bool>
<bool name="clustering.results">true</bool>
<!-- Field name with the logical "title" of a each document (optional) -->
<str name="carrot.title">name</str>
<!-- Field name with the logical "URL" of a each document (optional) -->
<str name="carrot.url">id</str>
<!-- Field name with the logical "content" of a each document (optional) -->
<str name="carrot.snippet">features</str>
<!-- Apply highlighter to the title/ content and use this for clustering. -->
<bool name="carrot.produceSummary">true</bool>
<!-- the maximum number of labels per cluster -->
<!--<int name="carrot.numDescriptions">5</int>-->
<!-- produce sub clusters -->
<bool name="carrot.outputSubClusters">false</bool>
<!-- Configure the remaining request handler parameters. -->
<str name="defType">edismax</str>
<str name="qf">
text^0.5 features^1.0 name^1.2 sku^1.5 id^10.0 manu^1.1 cat^1.4
</str>
<str name="q.alt">*:*</str>
<str name="rows">10</str>
<str name="fl">*,score</str>
</lst>
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>
<searchComponent name="terms" class="solr.TermsComponent"/>
<!-- A request handler for demonstrating the terms component -->
<requestHandler name="/terms" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<bool name="terms">true</bool>
<bool name="distrib">false</bool>
</lst>
<arr name="components">
<str>terms</str>
</arr>
</requestHandler>
<!-- A request handler for demonstrating the elevator component -->
<requestHandler name="/elevate" class="solr.SearchHandler" startup="lazy">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="df">text</str>
</lst>
<arr name="last-components">
<str>elevator</str>
</arr>
</requestHandler>
<!-- Highlighting Component
http://wiki.apache.org/solr/HighlightingParameters
-->
<searchComponent class="solr.HighlightComponent" name="highlight">
<highlighting>
<!-- Configure the standard fragmenter -->
<!-- This could most likely be commented out in the "default" case -->
<fragmenter name="gap"
default="true"
class="solr.highlight.GapFragmenter">
<lst name="defaults">
<int name="hl.fragsize">100</int>
</lst>
</fragmenter>
<!-- A regular-expression-based fragmenter
(for sentence extraction)
-->
<fragmenter name="regex"
class="solr.highlight.RegexFragmenter">
<lst name="defaults">
<!-- slightly smaller fragsizes work better because of slop -->
<int name="hl.fragsize">70</int>
<!-- allow 50% slop on fragment sizes -->
<float name="hl.regex.slop">0.5</float>
<!-- a basic sentence pattern -->
<str name="hl.regex.pattern">[-\w ,/\n\"']{20,200}</str>
</lst>
</fragmenter>
<!-- Configure the standard formatter -->
<formatter name="html"
default="true"
class="solr.highlight.HtmlFormatter">
<lst name="defaults">
<str name="hl.simple.pre"><![CDATA[<em>]]></str>
<str name="hl.simple.post"><![CDATA[</em>]]></str>
</lst>
</formatter>
<!-- Configure the standard encoder -->
<encoder name="html"
class="solr.highlight.HtmlEncoder" />
<!-- Configure the standard fragListBuilder -->
<fragListBuilder name="simple"
class="solr.highlight.SimpleFragListBuilder"/>
<!-- Configure the single fragListBuilder -->
<fragListBuilder name="single"
class="solr.highlight.SingleFragListBuilder"/>
<!-- Configure the weighted fragListBuilder -->
<fragListBuilder name="weighted"
default="true"
class="solr.highlight.WeightedFragListBuilder"/>
<!-- default tag FragmentsBuilder -->
<fragmentsBuilder name="default"
default="true"
class="solr.highlight.ScoreOrderFragmentsBuilder">
</fragmentsBuilder>
<!-- multi-colored tag FragmentsBuilder -->
<fragmentsBuilder name="colored"
class="solr.highlight.ScoreOrderFragmentsBuilder">
<lst name="defaults">
<str name="hl.tag.pre"><![CDATA[
<b style="background:yellow">,<b style="background:lawgreen">,
<b style="background:aquamarine">,<b style="background:magenta">,
<b style="background:palegreen">,<b style="background:coral">,
<b style="background:wheat">,<b style="background:khaki">,
<b style="background:lime">,<b style="background:deepskyblue">]]></str>
<str name="hl.tag.post"><![CDATA[</b>]]></str>
</lst>
</fragmentsBuilder>
<boundaryScanner name="default"
default="true"
class="solr.highlight.SimpleBoundaryScanner">
<lst name="defaults">
<str name="hl.bs.maxScan">10</str>
<str name="hl.bs.chars">.,!? 	 </str>
</lst>
</boundaryScanner>
<boundaryScanner name="breakIterator"
class="solr.highlight.BreakIteratorBoundaryScanner">
<lst name="defaults">
<!-- type should be one of CHARACTER, WORD(default), LINE and SENTENCE -->
<str name="hl.bs.type">WORD</str>
<!-- language and country are used when constructing Locale object. -->
<!-- And the Locale object will be used when getting instance of BreakIterator -->
<str name="hl.bs.language">en</str>
<str name="hl.bs.country">US</str>
</lst>
</boundaryScanner>
</highlighting>
</searchComponent>
<queryResponseWriter name="json" class="solr.JSONResponseWriter">
<str name="content-type">text/plain; charset=UTF-8</str>
</queryResponseWriter>
<queryResponseWriter name="velocity" class="solr.VelocityResponseWriter" startup="lazy"/>
<queryResponseWriter name="xslt" class="solr.XSLTResponseWriter">
<int name="xsltCacheLifetimeSeconds">5</int>
</queryResponseWriter>
<!-- Legacy config for the admin interface -->
<admin>
<defaultQuery>*:*</defaultQuery>
</admin>
</config>
通过Java代码操作索引库
SolrJ的使用
SolrJ是Apache官方提供的一套Java开发的,访问Solr服务的API,通过这套API可以让我们的程序与Solr服务产生交互,让我们的程序可以实现对Solr索引库的增删改查!
SolrJ的官方地址:https://wiki.apache.org/solr/Solrj
添加依赖
<dependencies>
<!--solrj核心jar包-->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
</dependency>
<!--免写getter/setter、构造函数、EqualsAndHashCode、ToString方法-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--日志相关 start-->
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</dependency>
<!--日志相关 end-->
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
创建实体类
package 中国.ilove.entity;
import lombok.Data;
/**
* 实体类对应数据库字段
* @author Zhang Ziheng
* @date Created in 2019-08-09 16:44
* 使用Data注解里包含:getter/setter、构造函数、EqualsAndHashCode、ToString方法
*/
@Data
public class Item {
private long id;
private String title;
private long price;
}
创建测试用例
添加或修改索引
- 以Document形式操作
public class SolrTest {
private HttpSolrServer solrServer;
/**
* 根据Document新增索引
* id存在就是更新,id不存在就是新增
*/
@Test
public void createIndex() throws Exception {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 创建文档
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", 15L);
doc.addField("title", "iphone 11");
doc.addField("price", 9999L);
// 添加
solrServer.add(doc);
// 提交
solrServer.commit();
}
}
- 用注解和JavaBean形式
javaBean
import lombok.Data;
import org.apache.solr.client.solrj.beans.Field;
/**
* 实体类对应数据库字段
* @author Zhang Ziheng
* @date Created in 2019-08-09 16:44
* 使用Data注解里包含:getter/setter、构造函数、EqualsAndHashCode、ToString方法
*/
@Data
public class Item {
@Field
private long id;
@Field
private String title;
@Field
private long price;
}
public class SolrTest {
private HttpSolrServer solrServer;
/**
* 根据实体类新增索引
*
* @throws Exception
*/
@Test
public void createIndexByBean() throws Exception {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 需要在实体类上加 @Filed 注解
// 否则会报异常:org.apache.solr.client.solrj.beans.BindingException:
// class: class 中国.ilove.entity.Item does not define any fields
Item item = new Item();
item.setId(16L);
item.setTitle("MacBook Pro 2020");
item.setPrice(21888L);
// 添加
solrServer.addBean(item);
// 提交
solrServer.commit();
}
}
删除索引信息
/**
* 删除索引信息
*/
public class SolrTest {
private HttpSolrServer solrServer;
@Test
public void deleteIndex() throws IOException, SolrServerException {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 根据id删除
solrServer.deleteById("14");
// 根据条件删除,语法:(字段:值) (*:*)删除所有;
// solrServer.deleteByQuery("title:Apple");
// solrServer.deleteByQuery("*:*");
// 提交
solrServer.commit();
}
}
查询索引信息
public class SolrTest {
private HttpSolrServer solrServer;
/**
* 查询索引信息
*/
@Test
public void query() throws SolrServerException {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 查询条件
SolrQuery solrQuery = new SolrQuery("*:*");
// (查询所有,只显示10条数据出来)这里设置查询行数并都显示出来
solrQuery.setRows(14);
// 执行查询,获取响应
QueryResponse response = solrServer.query(solrQuery);
// 解析响应
SolrDocumentList list = response.getResults();
System.out.println("本次共查询到:" + list.getNumFound() + "条");
// 遍历集合
for (SolrDocument document : list) {
System.out.print("id = " + document.getFieldValue("id") + " ");
System.out.print("title = " + document.getFieldValue("title") + " ");
System.out.println("price = " + document.getFieldValue("price"));
}
}
}
查询索引信息 封装到实体类中
public class SolrTest {
private HttpSolrServer solrServer;
/**
* 查询索引信息 封装到实体类中
*/
@Test
public void queryByBean() throws SolrServerException {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 查询条件
SolrQuery solrQuery = new SolrQuery("*:*");
// SolrQuery solrQuery = new SolrQuery("title:华为");
// (查询所有,只显示10条数据出来)这里设置查询行数
// solrQuery.setRows(14);
// 执行查询,获取响应
QueryResponse response = solrServer.query(solrQuery);
// 解析响应 封装到实体类中
List<Item> listBeans = response.getBeans(Item.class);
// 遍历输出
// listBeans.forEach(item -> System.out.println(item));
listBeans.forEach(System.out::println);
}
}
布尔查询
public class SolrTest {
private HttpSolrServer solrServer;
/**
* 特殊查询——布尔查询
*/
@Test
public void specialQuery() throws SolrServerException {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 布尔查询 OR或 AND与 NOT非 (大写)
SolrQuery specialQuery = new SolrQuery("title:华为 OR title:小米");
// SolrQuery specialQuery = new SolrQuery("title:华为 AND title:小米");
// SolrQuery specialQuery = new SolrQuery("title:华为 NOT title:小米");
// SolrQuery specialQuery = new SolrQuery("(title:华为 OR title:小米) AND 条件");
// 设置查询行数
specialQuery.setRows(10);
// 执行查询,获取响应
QueryResponse response = solrServer.query(specialQuery);
// 解析响应,封装到实体类中
List<Item> list = response.getBeans(Item.class);
// 遍历
list.forEach(System.out::println);
}
}
范围查询
public class SolrTest {
private HttpSolrServer solrServer;
/**
* 特殊查询——范围查询
*/
@Test
public void specialQueryTest() throws SolrServerException {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 范围 [起值 TO 终值] 华为价格在1000到2000之间 包含1199 和 2000
SolrQuery specialQuery = new SolrQuery("title:华为 AND price:[1199 TO 2000]");
// 华为价格在1000到2000之间 包含1000 和 2000 不包含 1199 和 2000
// SolrQuery specialQuery = new SolrQuery("title:华为 AND price:{1199 TO 2000}");
// 执行查询,获取响应
QueryResponse response = solrServer.query(specialQuery);
// 解析响应,封装到实体类中
List<Item> list = response.getBeans(Item.class);
// 遍历集合
list.forEach(System.out::println);
}
}
模糊查询(相似度查询)
public class SolrTest {
private HttpSolrServer solrServer;
/**
* 特殊查询——模糊查询(相似度查询)
*/
@Test
public void specialQuery() throws SolrServerException {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 在后面添加 ~ 符号,即可以开启模糊查询;appla 模糊查询能查到 apple
SolrQuery specialQuery = new SolrQuery("title:appla~");
// 执行查询,获取响应
QueryResponse response = solrServer.query(specialQuery);
// 解析响应,封装到实体类中
List<Item> list = response.getBeans(Item.class);
// 遍历
list.forEach(System.out::println);
}
}
查询排序
public class SolrTest {
private HttpSolrServer solrServer;
/**
* 特殊查询——升序、降序
*/
@Test
public void specialQuery() throws SolrServerException {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 查询条件
SolrQuery specialQuery = new SolrQuery("title:华为");
// 根据价格升序
specialQuery.setSort("price", SolrQuery.ORDER.asc);
// 根据价格降序
// specialQuery.setSort("price", SolrQuery.ORDER.desc);
// 执行查询,获取响应
QueryResponse response = solrServer.query(specialQuery);
// 解析响应,封装到实体类中
List<Item> list = response.getBeans(Item.class);
// 遍历
list.forEach(System.out::println);
}
}
分页查询
public class SolrTest {
private HttpSolrServer solrServer;
/**
* 特殊查询——分页查询
*/
@Test
public void specialQuery() throws SolrServerException {
// 连接solr服务端
solrServer = new HttpSolrServer("http://172.16.xx.xxx:8080/solr/collection1");
// 查询条件
SolrQuery specialQuery = new SolrQuery("*:*");
// 分页
int page = 1;
int size = 10;
int start = (page - 1) * size;
specialQuery.setStart(start);
specialQuery.setRows(size);
// 执行查询,获取响应
QueryResponse response = solrServer.query(specialQuery);
// 解析响应,封装到实体类中
List<Item> list = response.getBeans(Item.class);
// 遍历
list.forEach(System.out::println);
}
}
高亮显示
/**
* 设置高亮
*/
@Test
public void highlight() throws SolrServerException {
SolrQuery solrQuery = new SolrQuery("title:华为");
// 开启高亮
solrQuery.setHighlight(true);
// 设置前置标签 <em>
solrQuery.setHighlightSimplePre("<em>");
// 设置后置标签 </em>
solrQuery.setHighlightSimplePost("</em>");
// 添加高亮字段,可以添加多个高亮字段
solrQuery.addHighlightField("title");
// 执行查询,获取响应
QueryResponse response = solrServer.query(solrQuery);
// 解析响应,获取结果(这个结果是非高亮结果)
List<Item> listBean = response.getBeans(Item.class);
// 获取高亮结果,是一个map key是文档id,value 也是一个map: key是 字段名称 value是高亮结果的集合,如果只有一个值,就取第一个既可
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
// 处理高亮,封装到JavaBean中,遍历输出
// for (Item item : listBean) {
// item.setTitle(highlighting.get(item.getId()).get("title").get(0));
// }
// listBean.forEach(System.out::println);
// 更简单做法
listBean.stream().map(item -> {
item.setTitle(highlighting.get(item.getId()).get("title").get(0));
return item;
}).forEach(System.out::println);
}















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









