







1.介绍
有时候需要爬取某个网站的大量信息时,可能由于爬的次数太多导致我们的ip被对方的服务器暂时屏蔽。
2.分析西刺代理ip网站


3.获取ip
from bs4 import BeautifulSoup
import requests
from urllib import request,error
def getProxy(url):
# 打开我们创建的txt文件
proxyFile = open('proxy.txt', 'a')
# 设置UA标识
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit '
'/ 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36'
}
# page是我们需要获取多少页的ip,这里我们获取到第9页
for page in range(1, 10):
# 通过观察URL,我们发现原网址+页码就是我们需要的网址了,这里的page需要转换成str类型
urls = url+str(page)
# 通过requests来获取网页源码
rsp = requests.get(urls, headers=headers)
html = rsp.text
# 通过BeautifulSoup,来解析html页面
soup = BeautifulSoup(html)
# 通过分析我们发现数据在 id为ip_list的table标签中的tr标签中
trs = soup.find('table', id='ip_list').find_all('tr') # 这里获得的是一个list列表
# 我们循环这个列表
for item in trs[1:]:
# 并至少出每个tr中的所有td标签
tds = item.find_all('td')
# 我们会发现有些img标签里面是空的,所以这里我们需要加一个判断
if tds[0].find('img') is None:
nation = '未知'
locate = '未知'
else:
nation = tds[0].find('img')['alt'].strip()
locate = tds[3].text.strip()
# 通过td列表里面的数据,我们分别把它们提取出来
ip = tds[1].text.strip()
port = tds[2].text.strip()
anony = tds[4].text.strip()
protocol = tds[5].text.strip()
speed = tds[6].find('div')['title'].strip()
time = tds[8].text.strip()
# 将获取到的数据按照规定格式写入txt文本中,这样方便我们获取
proxyFile.write('%s|%s|%s|%s|%s|%s|%s|%s\n' % (nation, ip, port, locate, anony, protocol, speed, time))
4. 验证代理ip可用性
去访问百度网页是否可行。如果状态码200正常。就为可用代理ip.
def verifyProxy(ip):
'''
验证代理的有效性
'''
requestHeader = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
}
url = "http://www.baidu.com"
# 填写代理地址
proxy = {'http': ip}
# 创建proxyHandler
proxy_handler = request.ProxyHandler(proxy)
# 创建opener
proxy_opener = request.build_opener(proxy_handler)
# 安装opener
request.install_opener(proxy_opener)
try:
req = request.Request(url, headers=requestHeader)
rsq = request.urlopen(req, timeout=5.0)
code = rsq.getcode()
return code
except error.URLError as e:
return e
5.代码
from bs4 import BeautifulSoup
import requests
from urllib import request,error
def getProxy(url):
# 打开我们创建的txt文件
proxyFile = open('proxy.txt', 'a',encoding="utf8")
# 设置UA标识
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit '
'/ 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36'
}
# page是我们需要获取多少页的ip,这里我们获取到第9页
for page in range(1, 50):
# 通过观察URL,我们发现原网址+页码就是我们需要的网址了,这里的page需要转换成str类型
urls = url+str(page)
# 通过requests来获取网页源码
rsp = requests.get(urls, headers=headers)
html = rsp.text
# 通过BeautifulSoup,来解析html页面
soup = BeautifulSoup(html)
# 通过分析我们发现数据在 id为ip_list的table标签中的tr标签中
trs = soup.find('table', id='ip_list').find_all('tr') # 这里获得的是一个list列表
print(trs)
# 我们循环这个列表
for item in trs[1:]:
# 并至少出每个tr中的所有td标签
tds = item.find_all('td')
# 我们会发现有些img标签里面是空的,所以这里我们需要加一个判断
if tds[0].find('img') is None:
nation = '未知'
locate = '未知'
else:
nation = tds[0].find('img')['alt'].strip()
locate = tds[3].text.strip()
# 通过td列表里面的数据,我们分别把它们提取出来
ip = tds[1].text.strip()
port = tds[2].text.strip()
anony = tds[4].text.strip()
protocol = tds[5].text.strip()
speed = tds[6].find('div')['title'].strip()
time = tds[8].text.strip()
# 将获取到的数据按照规定格式写入txt文本中,这样方便我们获取
proxyFile.write('%s|%s|%s|%s|%s|%s|%s|%s\n' % (nation, ip, port, locate, anony, protocol, speed, time))
proxyFile.close()
def verifyProxy(ip):
'''
验证代理的有效性
'''
requestHeader = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
}
url = "http://www.baidu.com"
# 填写代理地址
proxy = {'https': ip}
# 创建proxyHandler
proxy_handler = request.ProxyHandler(proxy)
# 创建opener
proxy_opener = request.build_opener(proxy_handler)
# 安装opener
request.install_opener(proxy_opener)
try:
req = request.Request(url, headers=requestHeader)
rsq = request.urlopen(req, timeout=3.0)
code = rsq.getcode()
return code
except error.URLError as e:
return e
# 我们在这个方法中会得到一个状态码的返回,如果返回码是200,那么这个代理ip就是可用的。
def verifyProxyList():
inFile=open("proxy.txt","r",encoding="utf8")
verifiedFile = open('verified.txt', 'w',encoding="utf8")
while True:
ll = inFile.readline().strip()
if len(ll) == 0: break
line = ll.strip().split('|')
ip = line[1]
port = line[2]
realip = ip + ':' + port
code = verifyProxy(realip)
if code == 200:
print("---Success:" + ip + ":" + port)
verifiedFile.write(ll + "\n")
else:
print("---Failure:" + ip + ":" + port)
inFile.close()
verifiedFile.close()
if __name__ == '__main__':
getProxy("http://www.xicidaili.com/nn/")
getProxy("http://www.xicidaili.com/nt/")
getProxy("http://www.xicidaili.com/wn/")
getProxy("http://www.xicidaili.com/wt/")
verifyProxyList()
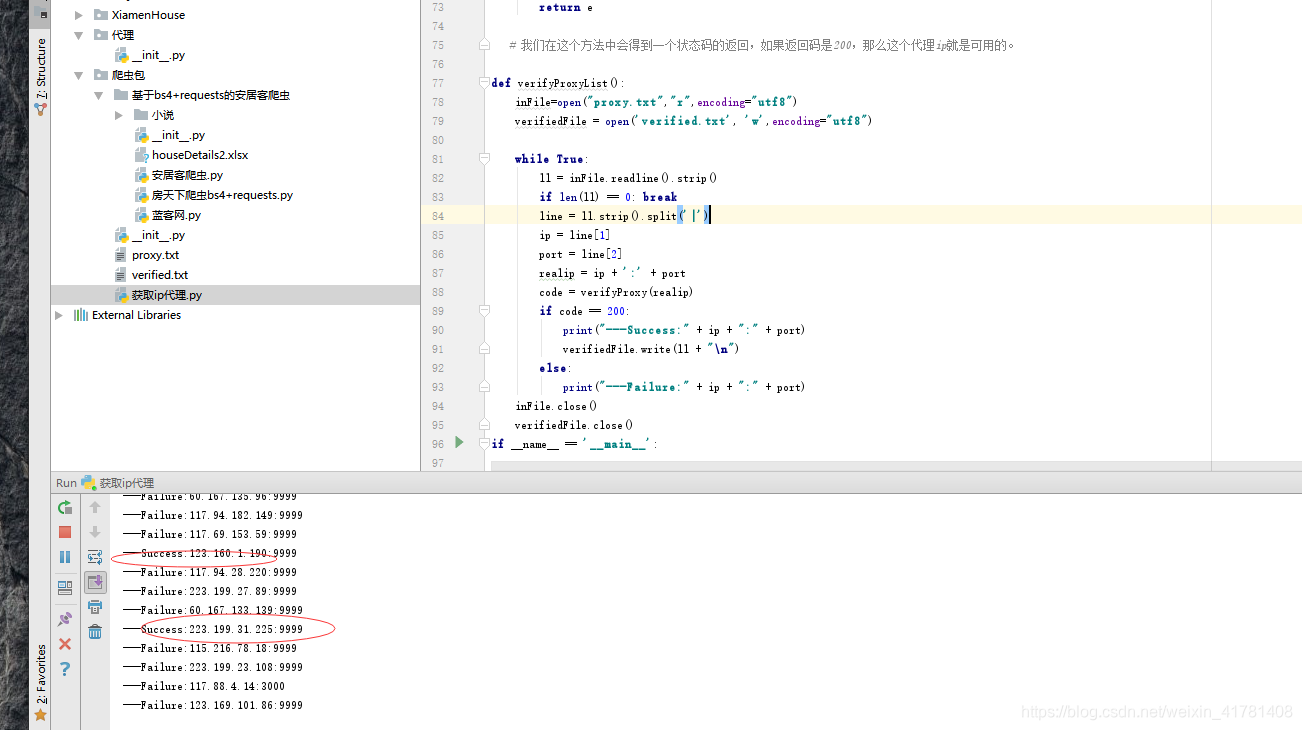
6. 结果
但是频繁爬会被封。。。。。。。
















 711
711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









