







MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取,将下载来的数据解压保存到datesets文件下,四个文件分别包括了images和labels,其中labels是images所对应的数字,训练集为50000个样本,测试集为10000个样本。
像素为28x28,单通道
图片是以字节的形式进行存储,需要把它转换成矩阵形式,
import os
import struct
import numpy as np
def load_mnist(path, kind='train'):
"""Load MNta from `path`"""
labels_path = os.path.join(path,IST da
'%s-labels.idx1-ubyte'
% kind)
images_path = os.path.join(path,
'%s-images.idx3-ubyte'
% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',
lbpath.read(8))
labels = np.fromfile(lbpath,
dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
magic, num, rows, cols = struct.unpack('>IIII',
imgpath.read(16))
images = np.fromfile(imgpath,
dtype=np.uint8).reshape(len(labels), 784)
return images, labels
X_train, y_train = load_mnist('E:\datasets')
import matplotlib.pyplot as plt
fig, ax = plt.subplots(
nrows=2,
ncols=5,
sharex=True,
sharey=True, )
ax = ax.flatten()
for i in range(10):
img = X_train[y_train == i][1].reshape(28, 28)
ax[i].imshow(img, cmap='Reds', interpolation='nearest')
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
fig, ax = plt.subplots(
nrows=5,
ncols=5,
sharex=True,
sharey=True, )
ax = ax.flatten()
for i in range(25):
img = X_train[y_train == 3][i].reshape(28, 28)
ax[i].imshow(img, cmap='Greens', interpolation='nearest')
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
load_mnist 函数返回两个数组, 第一个是一个 n x m 维的 NumPy array(images), 这里的 n 是样本数(行数), m 是特征数(列数). 在 MNIST 数据集中的每张图片由 28 x 28 个像素点构成, 每个像素点用一个灰度值表示. 在这里, 我们将 28 x 28 的像素展开为一个一维的行向量, 这些行向量就是图片数组里的行(每行 784 个值, 或者说每行就是代表了一张图片). load_mnist 函数返回的第二个数组(labels) 包含了相应的目标变量, 也就是手写数字的类标签(整数 0-9).

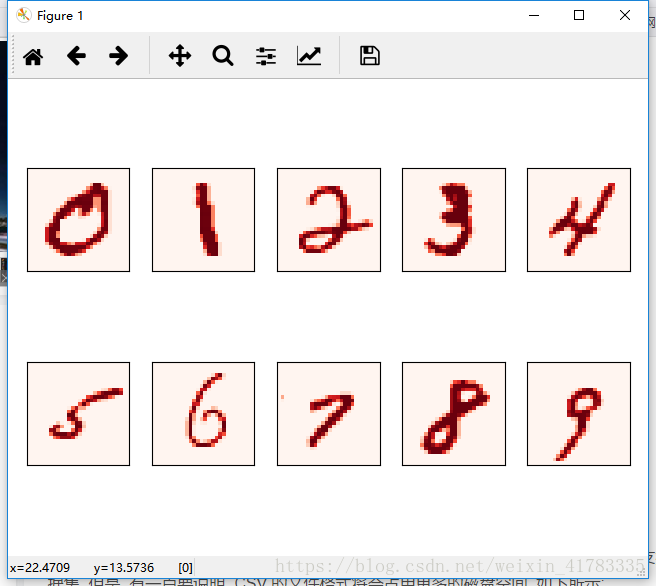

分别是一组0到9的图片和数字是3的图片.















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









