






因为自己做跨境,需要很多视频,就从网商相册里下载,但是网商相册一次只能下载20篇,而且下载的很慢,对于做跨境矩阵来讲,每天需要大量的成千上万的视频素材,那就去网上搜索。下面我贴图出来,以免大家再有人走弯路。
鉴定为假的,打开就是一个官网,就是一个卖视频剪辑的网站,垃圾的要死!
废话不多说:
第一步:打开网站www.szwego.com
第二步扫描登陆
第三步运行如下代码:
import time
import requests
import json
timestamp = "0"
has_more = True
while has_more:
url = f'https://www.szwego.com/album/personal/all?&albumId=_du3u3eNyp76LxAJLhdzLqtPlcQH7hLs131C26kw&searchValue=&searchImg=&startDate=&endDate=&sourceId=&requestDataType=×tamp={timestamp}'
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Cookie':'替换成自己的cookie',
'Host':'www.szwego.com',
# Sec-Ch-Ua-Mobile:?1
# Sec-Ch-Ua-Platform:"Android"
# Sec-Fetch-Dest:document
# Sec-Fetch-Mode:navigate
# Sec-Fetch-Site:same-origin
# Sec-Fetch-User:?1
# Upgrade-Insecure-Requests:1
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Mobile Safari/537.36'
}
res = requests.get(url=url, headers=headers)
datatype = res.json()
cursor = datatype.get("result").get("pagination").get("pageTimestamp")
if cursor:
timestamp = cursor
items = datatype.get('result').get("items")
for item in items:
with open("data.txt",'a') as f:
f.write(item.get('videoURL')+"\n")
has_more = datatype.get("result").get("pagination").get("isLoadMore")
time.sleep(0.1)
print("采集完成")
然后会有一个这样的文件生成:

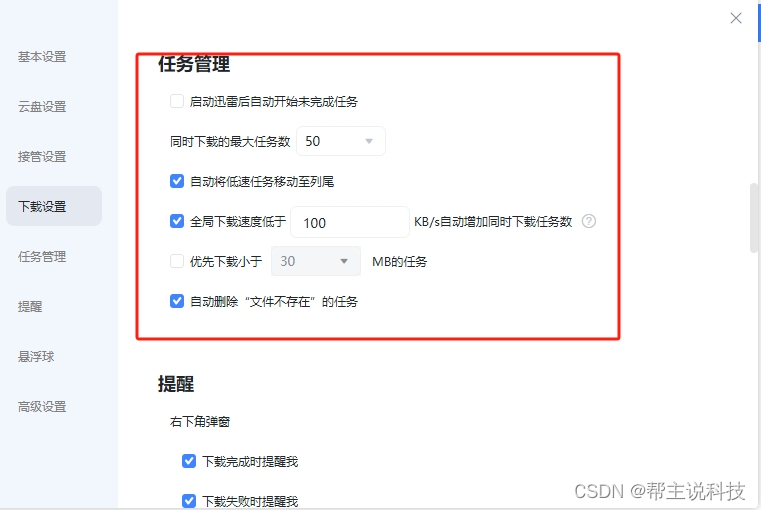
有的人可能会说了,那为啥不写一个直接下载这些视频地址的代码呢。本来是想写来着,后来一不小心复制了这些地址,结果调皮的迅雷就弹出来了,我心想,这迅雷肯定比咱们写的代码要快不,所以直接用迅雷下载很快的,但是记得在迅雷那配置好。我把配置好的截图贴上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









