







pandas数据重构与数据转换
重构
import numpy as np
import pandas as pd
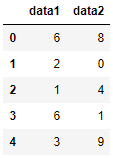
df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])
df_obj
运行结果:
-
stack
-
将列索引旋转为行索引,完成层级索引
stacked = df_obj.stack() print(stacked)运行结果:

-
dataframe 转换为 series
print(type(stacked)) print(type(stacked.index))运行结果:
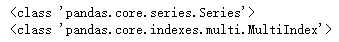
-
-
unstack
-
将层级索引展开
-
series转化为dataframe
-
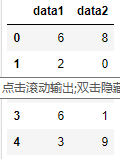
默认操作内层索引
# 默认操作内层索引 stacked.unstack()运行结果:
-
# 通过level指定操作索引的级别
stacked.unstack(level=0)
运行结果:

转换
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1' : ['a'] * 4 + ['b'] * 4,
'data2' : np.random.randint(0, 4, 8)})
df_obj
运行结果:

-
处理重复数据
-
duplicated() 返回布尔型series表示每行是否为重复行
df_obj.duplicated()运行结果:

-
drop_duplicates()过滤重复行
-
默认判断全部列
df_obj.drop_duplicates()运行结果:

-
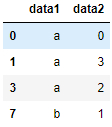
可指定按某些列判断
df_obj.drop_duplicates('data2')运行结果:
-
-
-
map
ser_obj = pd.Series(np.random.randint(0,10,10)) ser_obj运行结果:

-
series根据map传入的函数对每行或每列进行转换
ser_obj.map(lambda x : x ** 2)运行结果:

-
-
数据替换 replace
# 替换单个值 ser_obj.replace(0, -100)运行结果:
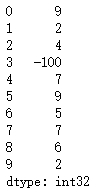
# 替换多个值 ser_obj.replace([0, 2], [-100, -200])运行结果:
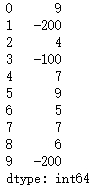















 2120
2120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











