






0 绪论
0.1 有关历史人文的扯淡
机器学习并不是一个新兴的概念,它的存在是一个漫长的故事,这需要从人和宇宙的关系讲起,话说当年盘古开天辟地的时候$#%&@%¥……哔——!。咳咳,扯远了,不过关于机器学习的早期记载,还真要从人和宇宙的关系来讲起。
十六世纪后期,丹麦天文学家第谷布拉赫,在大量的天文数据的基础上,拟合出了早期的天体运动规律。虽然他的结论是错误的((╬◣д◢)那你还讲这么多干什么!!!),但这一结论在根本上动摇了亚里士多德的天体不动学说,开启了近代天文学研究的大门。后来,开普勒正是在他的研究基础上,总结出了开普勒三大定律。你问开普勒定律是干啥用的,嗯……可以说,没有这些定律,我们的卫星和航天飞船只能在307国道上转悠。
我们提到了“拟合”这个词,这个词是什么意思呢。还记得初中时学函数的时候老师是怎么教我们画函数图像的吗?现在坐标系中描出几个点,然后再用平滑的曲线把它们连起来,拟合就是划线的过程。笼统地讲,机器学习就是收集大量数据(在坐标系上描出一坨一坨的点),然后再找一条“平滑的曲线”把它们连接起来的过程。描点就是特征提取的过程,连线就是训练的过程,然后根据自变量,在曲线上找因变量就是预测的过程。只不过在机器学习中,划线可不能仅仅凭借肉眼观察数据点的走向,然后大笔一挥,一条拟合曲线就有了。而是要通过一系列严谨的数学计算过程,使曲线尽量逼近数据点并且保证异常点(可以理解为你手一抖,描错的点,具体内容后面再说)对曲线的影响尽可能小。
上帝说,要有光,于是就有了光。上帝说,要有数据,于是就有了机器学习。上帝说,数据不够,于是就有了深度学习。
2016年1月27日,《自然》封面文章报道,谷歌研究者基于深度学习开发的名为“阿尔法狗(Alpha Go)”的人工智能机器人,以5:0完胜欧洲围棋冠军、职业二段选手樊麾。这是第一次人类在AI面前毫无招架之力。据说这条狗狗集成了1202个CPU,176个GPU,完成一场比赛(以5h计)要800多度电。那些打起刺客信条大革命、最终幻想、仁王神马的丝毫不卡的“神机”,在这条狗狗面前,全都是渣渣。自2012年依赖,硬件技术,尤其是显卡的发展,用计算机实现深度学习算法成为了可能
0.2 有关各种混淆不清的概念
人工智能(Artificial Intelligence,AI)是让计算机有独立学习能力的技术。机器学习(Machine Learning,ML)是用来实现人工智能的一种方法。而从机器学习的定义上讲,深度学习(Deep Learning,DL)是机器学习的一个分支,只不过由于深度学习的实现方法,与传统的机器学习算法大相径庭,因此经常会有人把深度学习从机器学习中独立出来。它们的关系可以概括为下图:
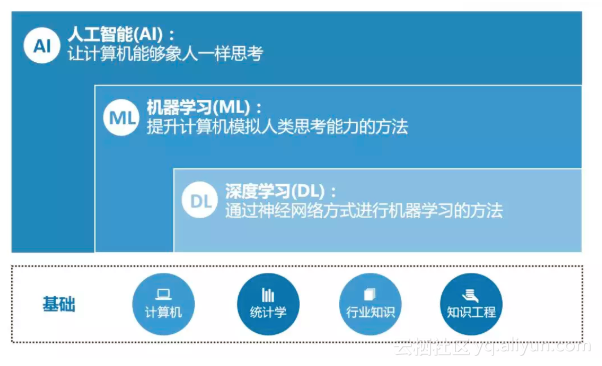
而机器学习的过程,可以概括为:
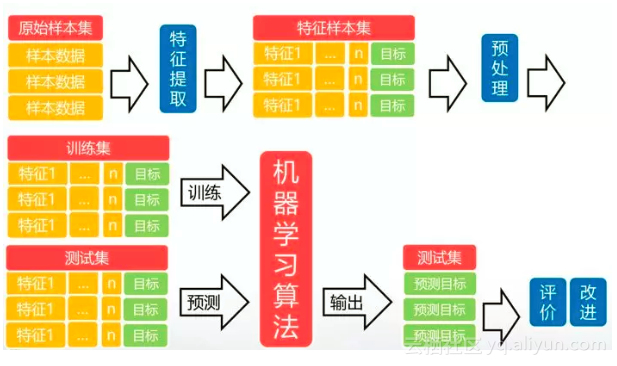
简单来讲,机器学习就是通过一系列特征和它们的目标(描点),来推测他们之间的关系(画图)的过程。
0.3 机器学习的相关概念
什么叫做特征提取,什么叫做预处理,什么叫做训练,什么叫做预测,这些概念性的东西在这里就不背书了,尽量简单形象地讲一下。
所谓特征,就是字变量,相对应的,目标(或者叫做标签)就是因变量。要想画图,就要描点,要想描点,就得有坐标。自变量的坐标值得是一个数,才能描到坐标系上。比如说某个社会学家某一天闲着没事,找了一个课题,研究一下消费欲望和性别的关系。那么消费欲望(一次购物能花多少钱)就是目标,也就是因变量,性别就是特征,也就是自变量。那么,就描点吧。问题来了,这点咋描?你见过像(男性,368块5毛3)这样的坐标吗?所以我们就要把这些特征转变为数值,才能描到坐标系里。花多少钱不用说了,就写成368.53好了。那么性别怎么转换成数字呢,可以用编码的方式。我们把“男性”记作1,女性记作0,所以上面那个坐标就可以记为(1,368.53)。把特征用数值来描述的过程就叫做特征提取。当然一个人的消费欲望是由很多因素决定的,不单单是性别,这里只是举个例子,大家不要较真儿。
预处理说的是是在把数据送到机器学习模型中训练之前,先要把数据处理一下。比如说,数据中有几个因为记录的时候手又抖了一下(这博主怕不是有帕金森综合征把彡(-_-;)彡),记错了。比如身高的数据,发现有个人的身高记成了3米28,这肯定是记错了,那就要看看有没有办法把这个数据改对,实在搞不清楚到底多高那就删掉这条数据算了。或者是数据有缺失,比如有一位不愿意透露性别的小朋友参与了调查,导致性别属性缺失。那么就想想有没有办法推测一下他的性别(比如发现该小朋友喜欢买包包,买口红,推测为女性),或者实在猜不出来(哼,我才不会告诉你是因为我懒得猜),那就删掉好了。还有就是把数据划分为训练集和测试集。训练集就是你拿来描点的数据,测试集就是等你画完图来看看这条线画得准不准的数据。为啥要这么干呢?如果把数据都用来训练,那我让曲线经过每一个点,大家看,我的训练结果准确率100%(也不知道这傻缺博主哪来的蜜汁自信)。这么做当然是不可能的,所以要留出一部分数据来测试一下你画的线准不准。
训练嘛,就是画图的过程。预测嘛,顾名思义,就是预测出没有出现在你手头里数据的特征对应的目标值。在评估机器学习模型的好坏的时候,就会用测试集的特征在模型上的预测结果,来和测试集的真实目标值做对比,来评估一个模型的好坏。
0.4 机器学习能干啥
万恶的资本家,为了压榨干净机器学习的全部剩余价值,给每一个机器学习算法都分配了相应的工作,丝毫没有浪费一点点的劳动力:

0.4.1 回归
所谓回归,就是刚才提到的描点画图。和我们初中画的图不一样的地方就在于,自变量不仅仅只有一个。初中的时候学过一元函数
y
=
f
(
x
)
y = f(x)
y=f(x),就是在二维的空间中用一个自变量来拟合一条曲线;高中的时候学了二元函数
y
=
f
(
x
1
,
x
2
)
y = f(x_1,x_2)
y=f(x1,x2),就变成了在二维空间中用两个自变量来拟合一个曲面。那么同样的,如果一个因变量(目标)由n个自变量(特征)来决定的,那就是n元函数
y
=
f
(
x
1
,
x
2
,
…
…
,
x
n
)
y = f(x_1,x_2,……,x_n)
y=f(x1,x2,……,xn),是一个在n+1维空间里的超平面。啥叫超平面,就是维度超过了3维,超过了人类眼睛能识别的范围,就叫超平面。正常人可以理解一维的直线,二维的平面,三维的空间,但是却无法理解四维或者四维以上的空间是什么玩艺儿(爱因斯坦不是正常人)。于是聪明的人类就想出了一个办法,既然画不出来,那就说出来好了。所以对于高维空间的描述,第n个维度就用
x
n
x_n
xn来表示。
例如之前说的对于购买欲望这个目标,可能由性别(
x
1
x_1
x1)、收入(
x
2
x_2
x2)、年龄(
x
3
x_3
x3)、有几个孩子(
x
4
x_4
x4)、有没有结婚(
x
5
x_5
x5)这些因素决定的(姑且就假装这么多吧,举个例子而已,不用较真儿)。那么对于目标(
y
y
y),就可以用函数关系式
y
=
f
(
x
1
,
x
2
,
x
3
,
x
4
,
x
5
)
y = f(x_1,x_2,x_3,x_4,x_5)
y=f(x1,x2,x3,x4,x5)来表示,这就是一个六维的函数图像。我们没法画出它的图,但是可以写出它的表达式。最终由这5个特征,通过某种映射关系,计算出目标。这个过程就叫做线性回归。
0.4.2 分类
还是以买东西为例,分类就是说我们需要计算的目标,不再是一个具体的数字(花了多少钱),而是类别(有人喜欢买化妆品,有人喜欢买吃的,有人喜欢买数码产品,按照这个就可以分为3类)。但是我们通过一个函数关系式 y = f ( x 1 , x 2 , … … , x n ) y = f(x_1,x_2,……,x_n) y=f(x1,x2,……,xn),依然会得到一个数。聪明的人类又想到一个办法,我们再把得到的 y y y代入另一个式子,让这个 z = g ( y ) z = g(y) z=g(y)得到一个在0到1之间的结果,就认为 z z z是 y y y属于某一类的概率。把 y y y属于这三类的概率都算出来,哪个概率大就认为 y y y属于哪一类。
0.4.3 聚类
说道聚类,就要先科普一个概念,有监督学习和与监督学习。我们之前说的回归和分类,都是有目标的,称为有监督学习;对于一堆没有目标的数据,我们对它们归类就是无监督学习,聚类就是无监督学习的一种。所谓物以类聚,我们看这些数据点,三三两两地聚在一块,就把这些离得近的数据归为一类,所以叫聚类。比如说对一些电影分类,是爱情片,还是动作片,还是爱情动……咳咳,总之要把他们归为几类。这些电影没有标签(导演是打死都不会剧透的),也不好界定(你说一场电影里即有打戏,又有吻戏,你说它是动作片还是爱情片),所以就根据它们特征的相似程度,把它们归为几类。这几个打戏多,就是动作片,那几个吻戏多,就是爱情片。
聚类算法还有一个重要的作用,就是剔除异常点。由于聚类是把特征比较相近的数据聚为一类,如果我们只聚一类,那些特立独行的数据点就会被挑出来。没的说,这些很有个性的点,肯定就是异常点了。
0.4.4 关联性分析
这又是一个很神奇的故事。20世纪90年代,美国沃尔玛超市发现了一件很神奇的事情。啤酒和尿布,这两件看似没有半毛钱关系的商品,经常会出现在同一辆购物车里。经社会学家研究发现(我才不信你们认真研究过,肯定是瞎编的(﹁"﹁)),因为妈妈们在家忙带孩子,腾不开时间去给孩子买尿布,就嘱咐在外工(gui)作(hun)的爸爸们下班的时候顺便去超市买尿布(这也就是在美国,要是换了中国,你还指望巨婴式的男人去买尿布?)。男人嘛,买尿布就成了自己顺便买酒的合理借口(全世界的男人都一个德行)。如果在超市只能买到两件商品之一,大猪蹄子们不肯为了迁就宝妈放弃啤酒,也不敢只买啤酒不买尿布,为了节约时间(呵,你们就是懒)他们可能就会去另一家可以同时买到啤酒与尿布的超市。由此,沃尔玛发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同区域,让年轻的父亲可以同时找到这两件商品,从而获得了很好的商品销售收入。这种研究两个东西关联性的算法就是关联分析。
0.4.5 降维
降维,就是把特征维度降低。如果一个数据的特征有很多维度(比如说图像处理,一张图片的一个像素点就是一个特征,如果是一张高清图片的化就会……),那肯定会大大增加计算量(放过我们的计算机吧,他还是个孩子)。那么有没有办法去掉其中的几个没有必要计算的维度呢?方法当然是有的,比如当几个特征相关性很强(例如我们闲着没事抛硬币,收集正面朝上、反面朝上和抛硬币次数三个数据,而正面朝上和反面朝上的和等于总次数,知道其中两个另一个也就能知道,那么我们用其中两个数据就可以完全代表这三个数据),就可以用其中的一部分来表示总体,从而删除掉没有必要计算的特征,以减小计算量。
0.4.6 人工神将网络和深度学习
这里就进入了深度学习的范畴。它是建立在机器学习基础上的算法,可以理解为它模拟人脑神经网络而设计的模型,由多个节点(人工神经元)相互联结而成,每个节点都对数据进行一次机器学习,然后再传导到下一个神经元再进行机器学习,知道得到满意的结果。深度学习的算法比较抽象,而且需要机器学习的基础,所以这里就先不废话了,说完机器学习之后我们再说(其实是我也没有研究透彻)。
0.5 作者想哔哔的一些废话
本系列学习笔记中用来实现算法的语言统一为Python,Python语言自开发出来之后,强大的接口功能、便捷的书写语法和对底层语言惨无人道的集成能力使它成为目前用来写机器学习代码最方便的语言(别的我也不会啊( ̄ェ ̄;))。尤其是主流的算法代码已经被大神们封装好了,我们拿来直接用就好(对一个程序猿来说,世界上最快乐的事莫过于当一个调包侠了)。
而且本人也是处于学习阶段,对于一些算法的原理,自己要新研究透彻才能拿出来说,所以本系列文章更新是不定期的(打死也不承认是因为我懒)。而且文中所述都是自己对机器学习的理解,就中有什么谬误或疏漏,还请各位大神批评指正。所谓尽信书不如无书,更何况我还是一个刚刚跻身机器学习领域的小白。
关于本系列文章的写作丰富,我会尽量保持通俗和轻松的风格。本人也听过很多老师对于机器学习和讲授,但是其中通篇的名词术语搞得很是头大,学习成果就是背过了很多专有名词,在聊天的时候可以成功把人侃晕,然后把天聊死(这就是我至今单身的独家秘诀,哪位小姐姐来拯救一下我)。学术是严谨的,但学术的教授可以是轻松的。说实话我对这样的老师是很鄙视的,我认为一个老师,即便是无法把课讲的妙语连珠、趣味横生,但通俗易懂是最起码的要求了。本人也在努力,把机器学习的内容以最简单的方式表达出来,就中不妥之处,还请大家批评指正。
0.6 参考文献
终于可以不用管参考文献的格式了,真TM爽。
1 《Pattern Recognition and Machine Learning》Christopher Bishop 著
2 拥抱人工智能,从机器学习开始














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









