






jvm
1.jvm的内存模型

2.jvm的垃圾回收算法
1 复制算法
2 标记整理算法
3 标记清楚算法
3.jvm中的对象什么情况下面可以放入老年代
1 大对象直接进入老年代(可以参数配置)
2 长期存活的对象将进入老年代(默认15)
3 对象动态年龄判断(如果在Survivor空间中相同年龄所有对象大小的总和大于 Survivor 空间的一半,年龄大于或等 于该年龄的对象就可以直接进入老年代)
4 老年代空间分配担保
4.Java中的各种引用
1.强引用 (Object obj = new Object() 只要强引用关联还在,垃圾回收器就永远不会回收掉被引用的对象)
2.软引用 SoftReference (要发生OOM的时候会回收 ,如果这次回收后还是没有足够的 空间,才会抛出内存溢出)
3.弱引用 WeakReference (GC发生时不管内存够不够都会垃圾回收 ThreadLocal就是弱引用)
4.虚引用 PhantomReference(又称为幽灵引用,最弱(随时会被回收掉,用于垃圾回收的时候的一个通知,就是为了监控垃圾回收器是否正常工作。)
5.JVM、JRE、JDK 的关系
1.JVM (java虚拟机) java 编程语言的核心并且具有平台独立性
2.JRE(java运行时环境) 它除了包含 JVM 之外,提供了很多的类库(就是我们说的 jar 包,它可以提供一些即插即用的功能,比如读取或者操作文件,连接网络, 使用 I/O 等等之类的)这些东西就是 JRE 提供的基础类库。
3.JDK(Java Development Kit) 是整个JAVA的核心,包括了Java运行环境(Java Runtime Envirnment),一堆Java工具(javac/java/jdb等)和Java基础的类库(即Java API 包括rt.jar)
spring
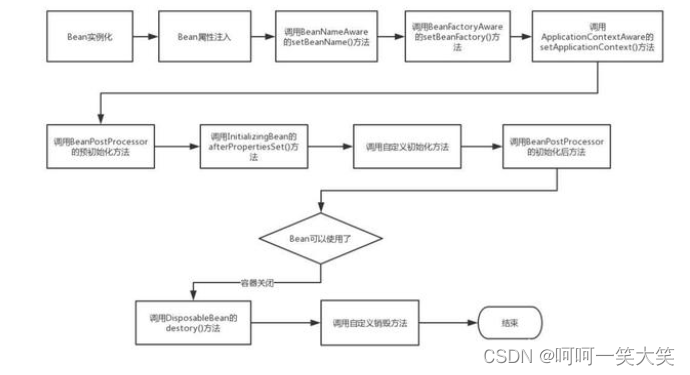
1.bean的生命周期
1、实例化(Instantiation)
2、属性设置(populate)
3、初始化(Initialization)
4、销毁(Destruction)
2.beanFactory和factoryBean的区别
这是两个完全不一样的东西,感觉面试官问这个就是坑。
beanFactory :bean工厂,所有的bean扫描成beanDefinition都会放在beanFactory里面的
一个beanDefinitionMap里面。
factoryBean :工厂Bean,也是一个Bean,作用是产生其他bean 实例。可以定义一个类实现factoryBean,
里面的getObject()方法可以自定义一个bean,getBean(beanName)参数前面加&符号可以获得
实现factoryBean的bean ,不加符号(传入bean)会获得getObject()方法里面返回的Bean。

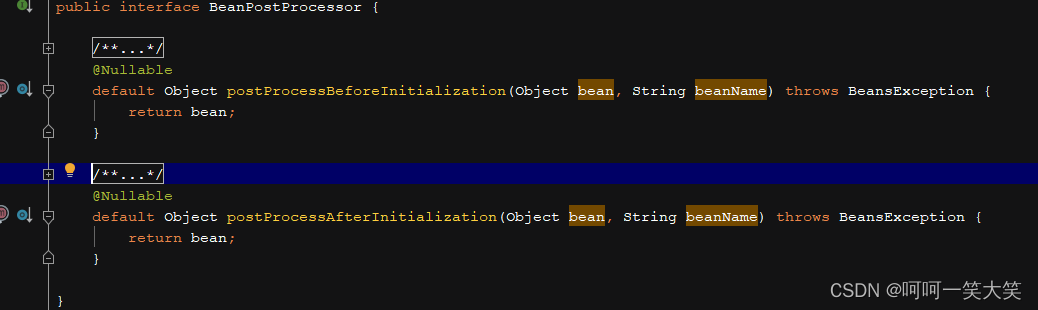
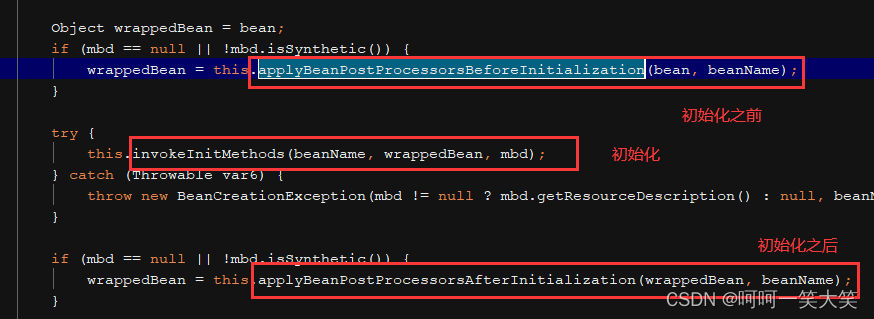
3.beanPostProcessor和beanFactoryPostProcessor的区别
beanPostProcessor里面有两个方法 ,分别是bean初始化前,初始化后调用
beanFactoryPostProcessor里面有一个postProcessBeanFactory方法,可以实现postProcessBeanFactory接口重写postProcessBeanFactory拿到 beanFactory 对bean或者bean工厂坐一些自定义操作,也可以注册bean。

4.bean的作用域
1.单例(默认)
2.多例
3.request
4.session
5.global session 作用域
自定义作用域:第一要获取 BeanFactory,第二调用 registerScope 方法把
自定义的 scope 注册进去,第三写一个类实现 scope 接口。
5.spring怎么解决单例的并发安全问题的
ThreadLocal解决并发安全问题
6.说说spring的IOC
ioc控制反转,意思就是由spring来负责控制对象的生命周期和对象间的关系。所有类的创建和销毁都由
spring来控制,也就是说控制对象生命周期的不再是引用它的对象,而是spring。所以这叫控制反转。
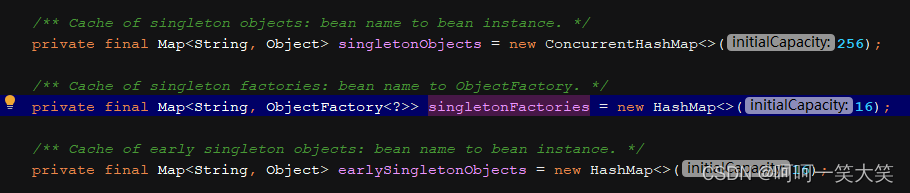
7.说说spring的循环依赖
对象A里面@Autowired对象B,对象B里面@Autowired对象A,这就是循环依赖。spring里面是采用
三级缓存来解决循环依赖问题的。
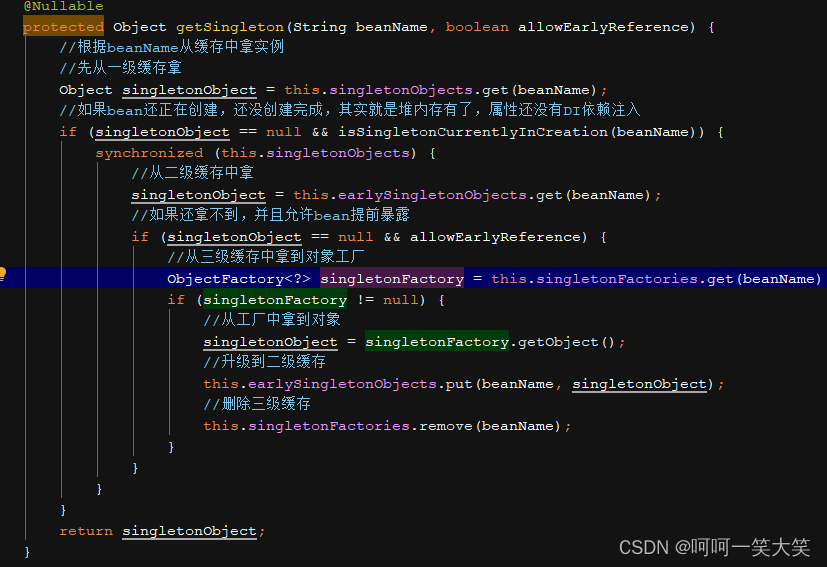
1.首先getBean(A)的时候会把A放到三级缓存,
2.然后去注入B的时候会触发B的getBean(B),把B也放到三级缓存
3.然后B里面又会注入A,然后去缓存里面拿A对象,发现三级缓存里面有A对象,就会调用getObject()方法拿到A,
然后把A放到二级缓存,三级缓存删除。然后B就实例化完成就会放到一级缓存,删除二级三级缓存。
4.B实例化完成了,A里面也完成了,也会去删除二级三级缓存放到一级缓存。
其中还有一些细节有兴趣的伙伴可以去研究研究,比如加入三级缓存时传了一个getEarlyBeanReference()方法,该方法就是为了提前进行AOP。还有表示当前bean正在实例化的set容器。
8.spring的事务传播属性
REQUIRED:默认值,支持当前事务,如果没有事务会创建一个新的事务
SUPPORTS:支持当前事务,如果没有事务的话以非事务方式执行
MANDATORY:支持当前事务,如果没有事务抛出异常
REQUIRES_NEW:创建一个新的事务并挂起当前事务
NOT_SUPPORTED:以非事务方式执行,如果当前存在事务则将当前事务挂起
NEVER:以非事务方式进行,如果存在事务则抛出异常
NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与REQUIRED类似的操作
最常用的就三种REQUIRED REQUIRES_NEW NESTED 有兴趣可以写伪代码去试试
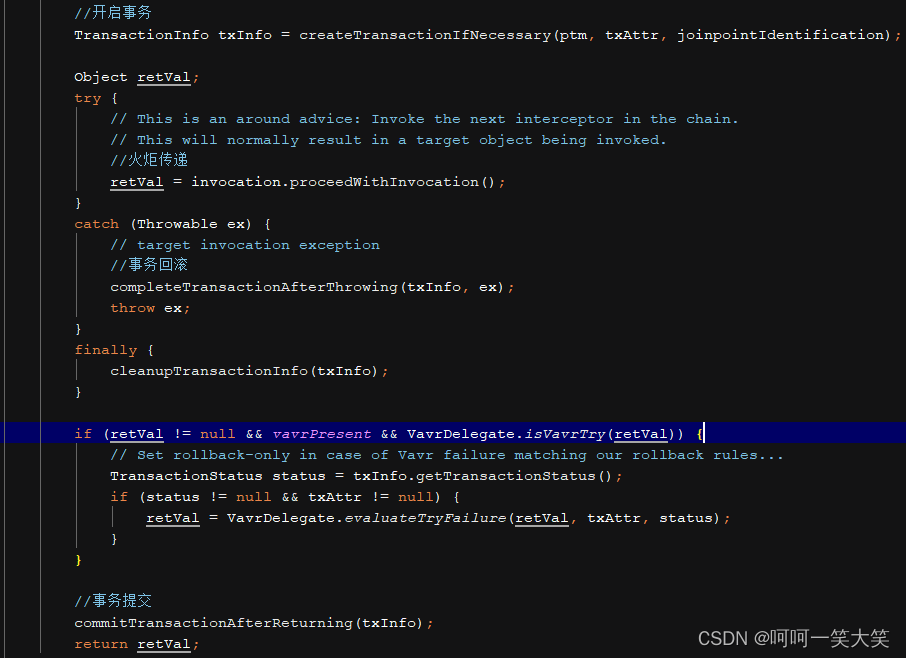
开启事务
try{
goodService.add();
areaService.add();
}catch(Exception e){
事务回滚
}
事务提交
9.说说spring的AOP
AOP面向切面编程,基于JDK和cglib动态代理生成代理对象。切点+增强逻辑=切面
Advisor = pointCut + advice
spring会判断是否有切面,有则会生成代理对象
mysql
1.mysql的体系结构

可以看出 MySQL 最上层是连接组件。下面服务器是由连接池、管理工具和 服务、SQL 接口、解析器、优化器、缓存、存储引擎、文件系统组成。
2.mysql的索引结构
InnoDB引擎是B+树结构
3.mysql有哪些存储引擎
1.InnoDB 存储引擎 (InnoDB 是 MySQL 的默认事务型引擎)
2.MylSAM 存储引擎(在 MySQL 5.1 及之前的版本,MyISAM 是默认的存储引擎)
3.Mrg_MylSAM
4.Archive 引擎
5.Blackhole 引擎
6.CSV 引擎
7.Federated 引擎
8.Memory 引擎
9.NDB 集群引擎
4.mysql索引失效的原因
1.不在索引列上做任何操作(比如加减运算,作为函数参数等)
2.尽量全值匹配(因为联合索引有一个最佳左前缀法则,比如索引abc 你where b 或者 where c 是用不到索引的 因为索引会按a排序,
然后在a相同的基础上按b排序,类推。。。)
3.like 以通配符开头('%abc...')
4.字符串不加单引号索引失效(mysql查询优化器会自动的进行类型转换)还有很多情况 比如 不等于 null、not null 排序都有可能导致失效,得具体看情况.
5.mysql的MVCC
mvcc多版本并发控制,mysql利用mvcc和undo日期基本解决了幻读的问题。
每次对记录进行改动,都会记录一条 undo 日志,每条 undo 日志也都有一 个 roll_pointer 属性
(INSERT 操作对应的 undo 日志没有该属性,因为该记录并没 有更早的版本),可以将这些 undo 日志都连起来,串成一个链表。
对该记录每次更新后,都会将旧值放到一条 undo 日志中,就算是该记录的 一个旧版本,随着更新次数的增多,所有的版本都会被
roll_pointer 属性连接成 一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的 值。另外,每个版本中还
包含生成该版本时对应的事务 id。于是可以利用这个记 录的版本链来控制并发事务访问相同记录的行为,那么这种机制就被称之
为多版 本并发控制(Mulit-Version Concurrency Control MVCC)。
6.听说过select ----- for update吗?
for update手动加锁, 在mysql中如果查询条件带有主键,会锁行数据。如果没有,会锁表。直到事务提交或回滚后为止。
7.说说mysql的锁
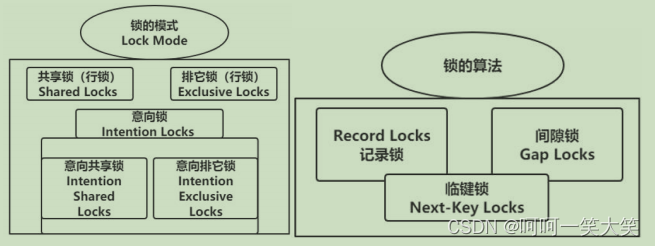
8.听说过mysql的间隙锁吗?
间隙锁实质上是对索引前后的间隙上锁,不对索引本身上锁。
redis
1.redis有哪些数据类型
1.String
2.hash
3.list
4.set
5.zset
2.你们项目redis使用场景
1.缓存
2. 分布式锁
3.redis的缓存穿透,缓存击穿,缓存雪崩,如何解决?
缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。
比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有。(解决:缓存空对象,布隆过滤器)
缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,
这个时候大并发的请求可能会瞬间把后端DB压垮。(解决:加锁)
缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。(解决:失效时间随机)
4.你们怎么解决redis的一致性问题
https://blog.csdn.net/wode3157695297/article/details/121961388
5.zk会存贮redis的哪些内容
一般存贮一些集群节点数据















 3806
3806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









