







1、pycharm的常用配置
1.1修改主题配置
- 1、点击菜单file,选择settings选项
- 2、选择editor,点击color scheme配色方案
- 3、在右侧选择对应的主题配置
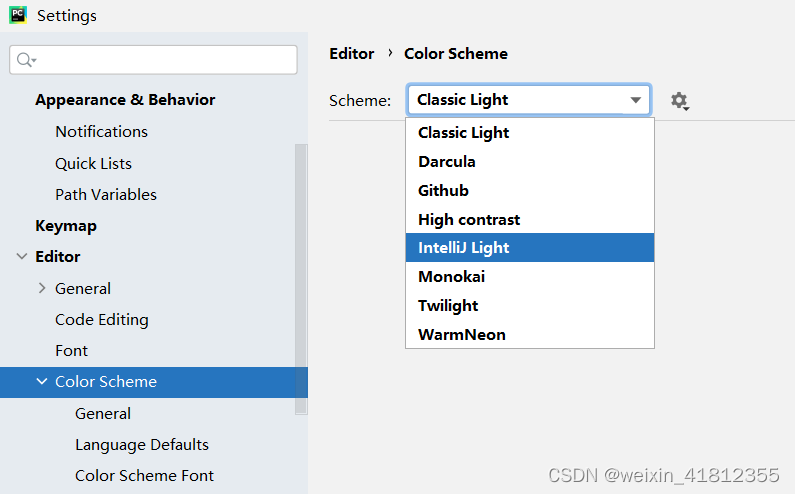
1.2修改背景颜色
- 1、点击菜单file,选择settings选项
- 2、选择appearance,点击Theme
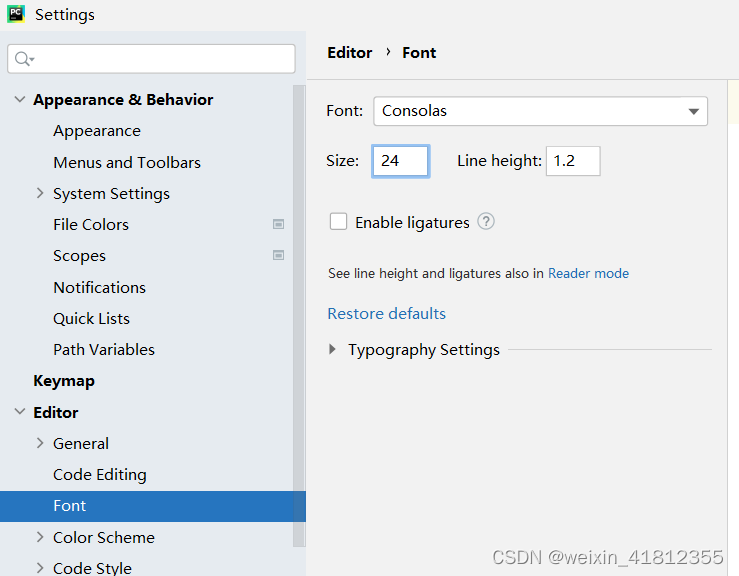
 1.3调整字体大小
1.3调整字体大小
- 1、点击菜单file,选择settings选项
- 2、选择editor,点击font
- 3、右侧可以调整字体的大小以及样式,样式建议选择consolas
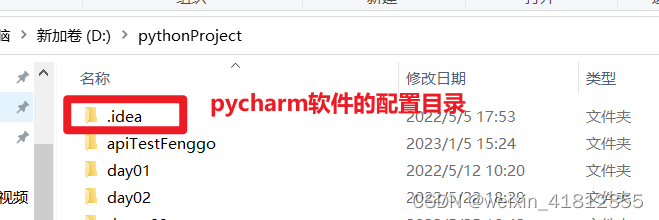
1.4pycharm软件的配置目录
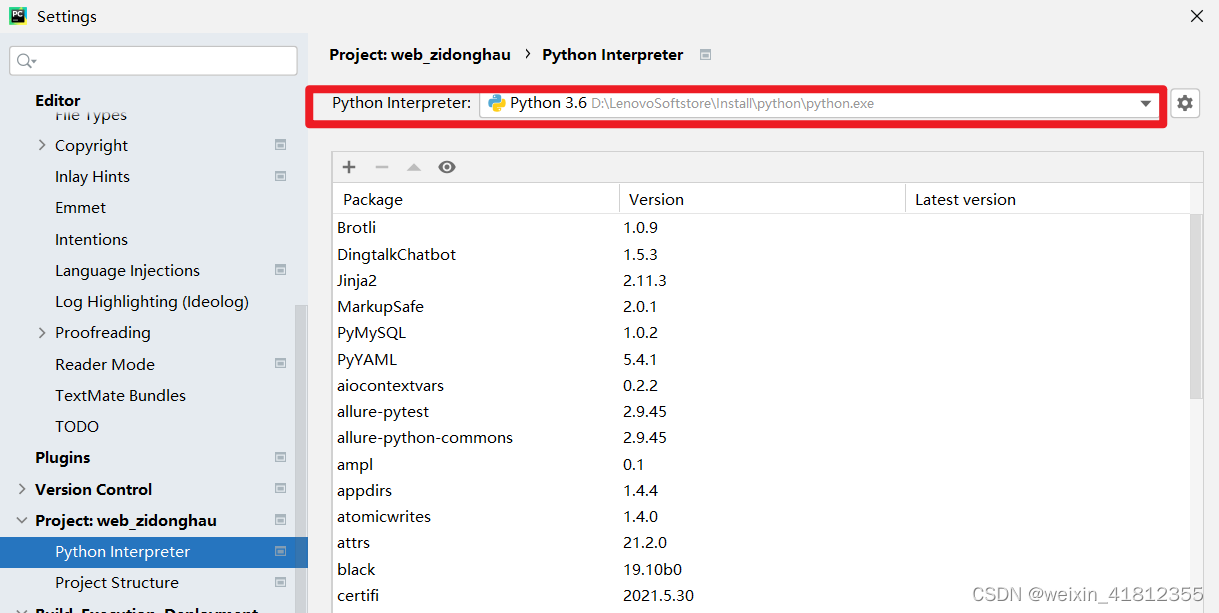
1.5设置解释器
 1.6 因没有配置python解释器报错
1.6 因没有配置python解释器报错

1.7 动态代码模板
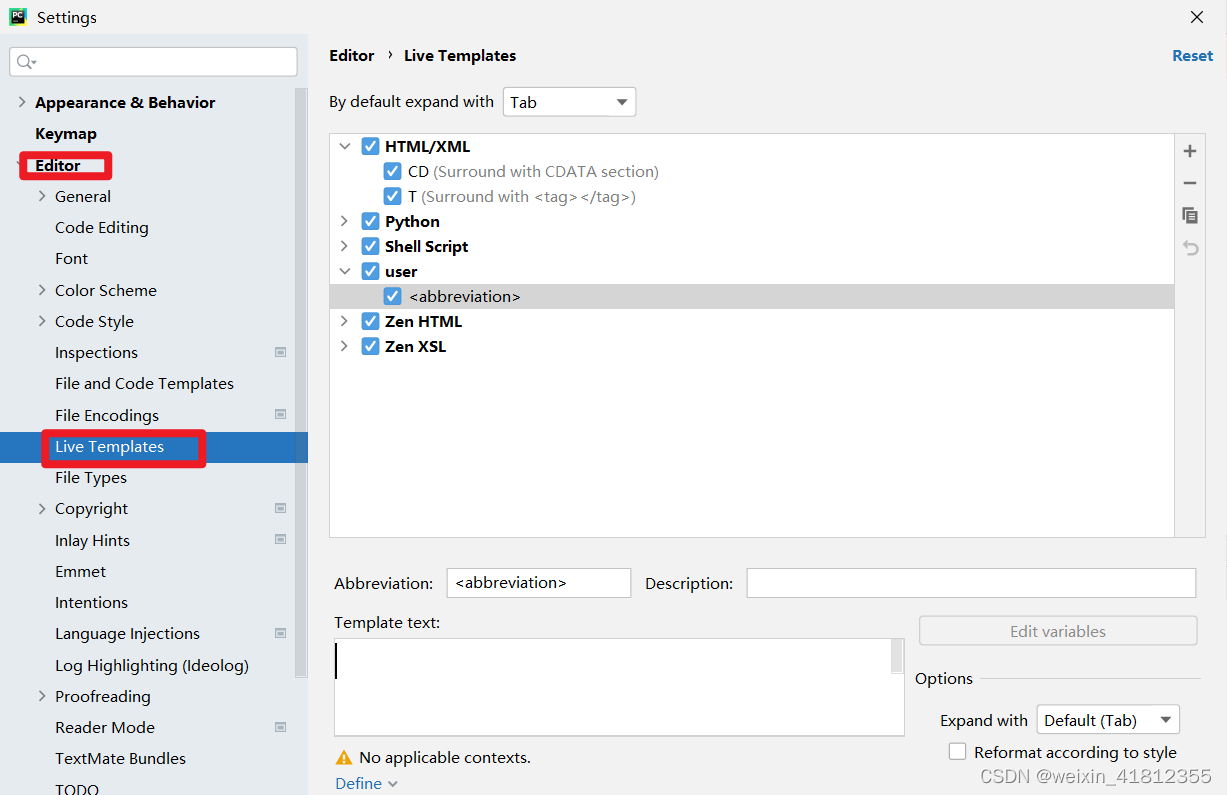
2、python代码中的三种波浪线和PEP8
2.1红色波浪线
红色波浪线是代码错误,必须处理,代码才能执行;
如果代码没有写完时也会出现红色波浪线;
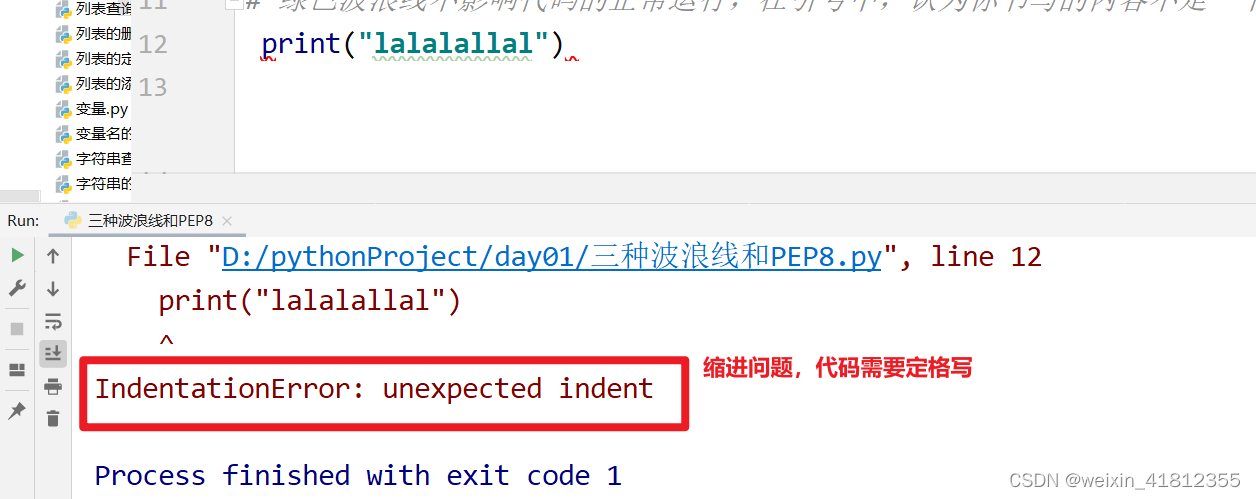
2.2灰色波浪线
灰色波浪线不影响代码的正常执行,可以使用快捷键ctrl+Alt+L进行消除,或者点击code->reformat code;
符合PEP8就不会展示灰色波浪线;
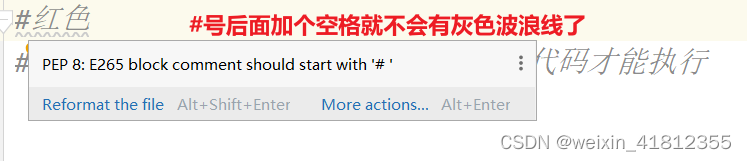
补充:ctrl+alt+L这个快捷键如果和其他软件冲突,可以进行修改;
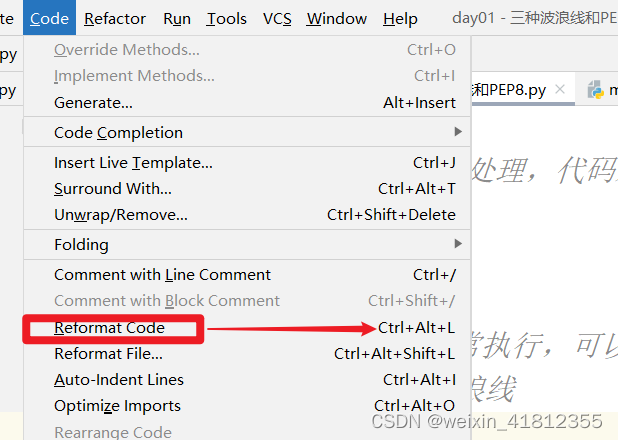
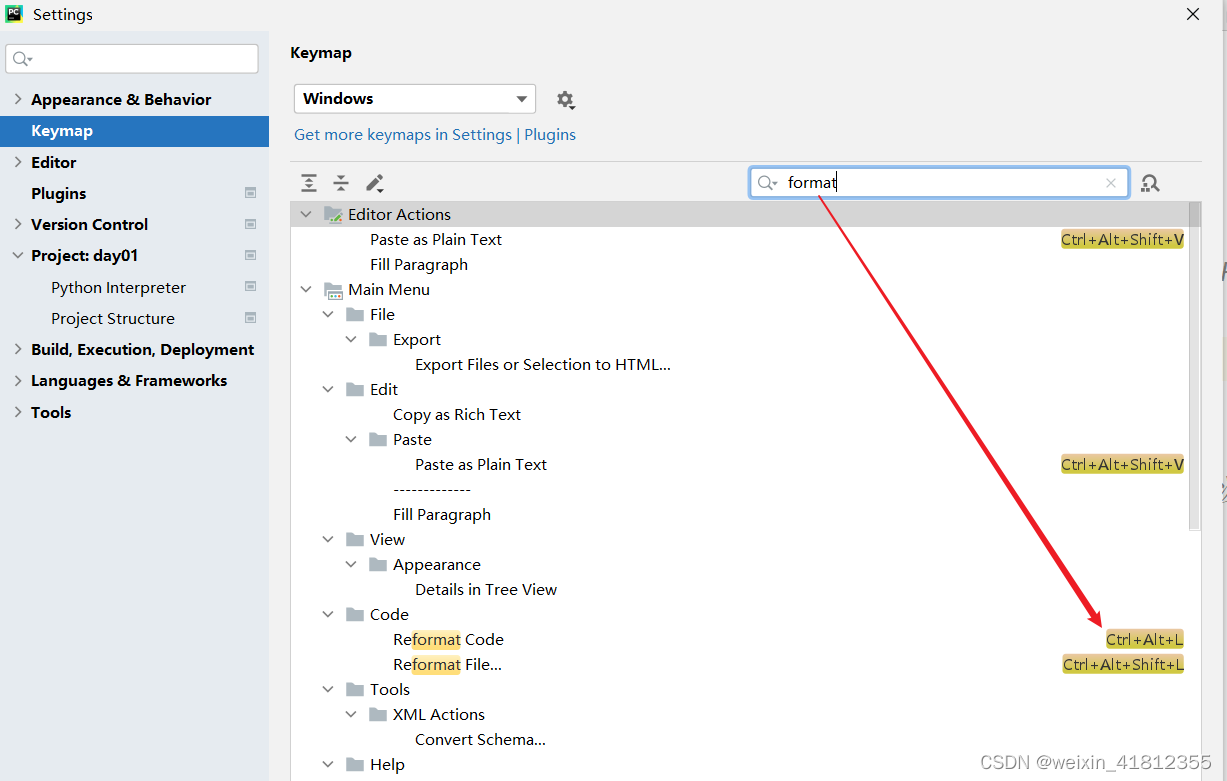
2.3绿色波浪线
绿色波浪线不影响代码的正常运行,在引号中,认为你书写的内容不是一个单词,就会给个绿色波浪线提示;
3、python代码运行方式
3.1在cmd终端中运行python代码
python 代码文件中的名字三种在cmd运行方式
(1). windows+R,输入cmd进入到dos命令窗口中,书写python 代码文件中的名字;

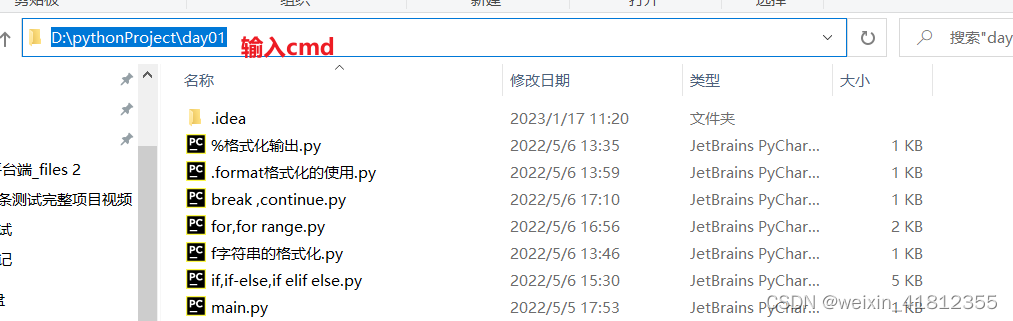
(2). 找到代码所在文件,在路径栏中输入cmd进入到dos命令窗口中,书写python 代码文件的名字;

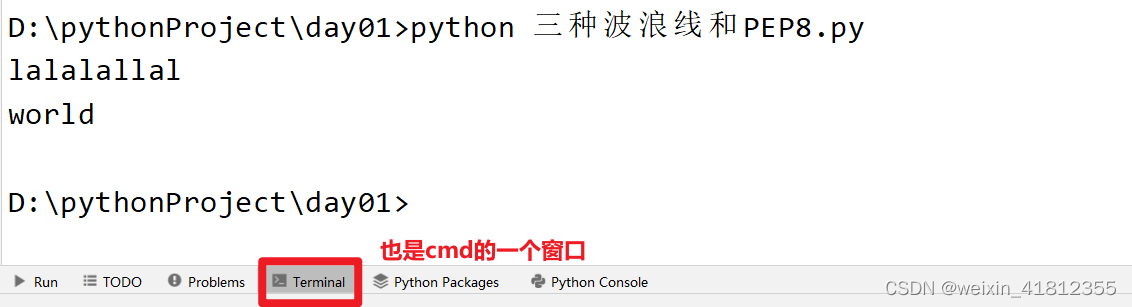
(3).在pycharm中找到 Terminal,输入python 代码文件中的名字
4、变量
4.1变量的作用
是用来存储数据的(在程序代码中出现的数据,想要保存下来使用,就必须使用变量),如:测试数据,用户名,密码,验证码;
变量注意实现:变量必须先定义(保存数据)后使用(取出数据);
4.2定义变量
变量名 = 数据值 #可以理解为是将数据值保存到变量中
#比如:
name = '张三' #定义一个变量 name,存储的数据值是 张三
4.3使用变量
变量定义之后,想要是使用变量中的数据,直接使用变量名即可
#使用变量获取数据,打印
print(name)
4.4代码书写
4.5 变量命名的规范
标识符命名规则是python中定义各种变量名或其他名字的时候的统一规范,具体如下:
- 由数字、字母、下划线组成
- 不能使用数字开头
- 不能使用python内置关键字
- 严格区分大小写
- 建议性的命名
- 驼峰命名法
- 大驼峰:每个单词的首字母大写 MyName
- 小驼峰:第一个单词的首字母小写,其余单词的首字母大写 myName
- 下划线连接法:每个单词之间使用下划线连接my_name
-
python 中的变量的定义使用的是 下划线连接 - 见名知意
- name 姓名 age 年龄 height身高......
- 驼峰命名法
python中的关键字:

5、常见数据类型分类
将生活常见的数据划分为不同的类型,因为不同的类型可以进行的操作是不一样的,数字需要加减乘除,文字不需要.....
- 数字类型
- 整型(int):就是整数,即不带小数点的数
- 浮点型(float):就是小数
- 布尔类型(bool):只有两个值
- 真 True,1
- 假 False 0,非0即真
-
True和False都是python中的关键字,注意大小写,不要写错了
- 复数类型3+4i,不会用的
- 非数字类型
- 字符串:(str)使用引号引起来的就是字符串
- 列表(list)[1,2,3,4]
- 元组(tuple)(1,2,3,4)
- 字典(dict){"name":"小明","age":18}
- type()函数
-
可以获取变量的数据类型 type(变量) 想要将这个变量的类型在控制台显示,需要使用print输出 print(type(变量))
-
6、输入和输出
6.1输入
获取用户使用键盘录入的内容
使用的函数是input()
1.代码从上到下执行,遇到input函数之后,会暂停执行,等待用户的输入,如果不输入会一直等待
2.在输入的过程中,遇到回车,代表本次输入结束
3.会将你输入的内容 保存到等号左边的变量中,并且 变量的数据类型 一定是str6.2输出
基本输出
输出使用的函数是print()函数,作用,将程序中的数据或者结果打印到控制台(屏幕)
print('hello world')
name = '小明'
print(name)
age = 18
print(name,age) #可以使用逗号输出多个内容
格式化输出
在字符串中指定的位置,输出变量中存储的值
1、在需要使用变量的地方,使用特殊符号占位
2、使用变量填充占位的数据
- %格式化输出占位符
- %d 占位,填充 整型数据 digit
- %f 占位,填充 浮点型数据 float
- %s 占位,填充 字符串数据 string
name = '小明'
age = 18
height = 1.68
print('我的名字是%s,年龄%d岁,身高%f m'% (name,age,height))
# 小数的默认是6位,可以使用%.nf,n来控制位数
print('我的名字是%s,年龄%d岁,身高%.1f m'% (name,age,height))
# 如果想打印学号00001,可以使用%0nd,n来控制有几个0
xuehao = 1
print('学号:',xuehao)
print('学号是:%06d'%xuehao)
#如果想要打印及格率,可以使用%%来输出%
sum = 90
print("及格率是:%d%%"%sum)
F-string(f字符串的格式化方法)
f-string 格式化的方法,想要使用,python的版本>=3.6
1、需要在字符串的前边加上f""或者F""
2、占位符号统一变为{}
3、需要填充的变量写在{}中name = '小明' #姓名
age = 18 #年龄
height = 1.68 #身高
xuehao = 1 #学号
sum = 90 #及格率
print(f'我的名字是{name},年龄{age}岁,身高{height}m,学号{xuehao},及格率是{sum}%')
# 换行展示
print(f'我的名字是{name},年龄{age}岁,\n身高{height}m,学号{xuehao},及格率是{sum}%')
print(f'我的名字是{name},年龄{age}岁,身高{height:.3f}m,学号{xuehao:06d},及格率是{sum}%')
字符串.format()
- 1、在需要使用变量的地方用{}占位
- 2、‘{},{},{},...’.format(变量,变量,变量,...)
name = '小明'
age = 18
height = 1.68
xuehao = 1
sum = 90
print('我的名字是{},年龄{}岁,身高{}m,学号{},及格率是{}%'.format(name,age,height,xuehao,sum))
print('我的名字是{},年龄{}岁,身高{:.6f}m,学号{:06d},及格率是{}%'.format(name,age,height,xuehao,sum))
7、类型转换
语法:
变量 = 要转换为的类型(原数据)
1、数据原来是什么类型
2、你要转换为什么类型
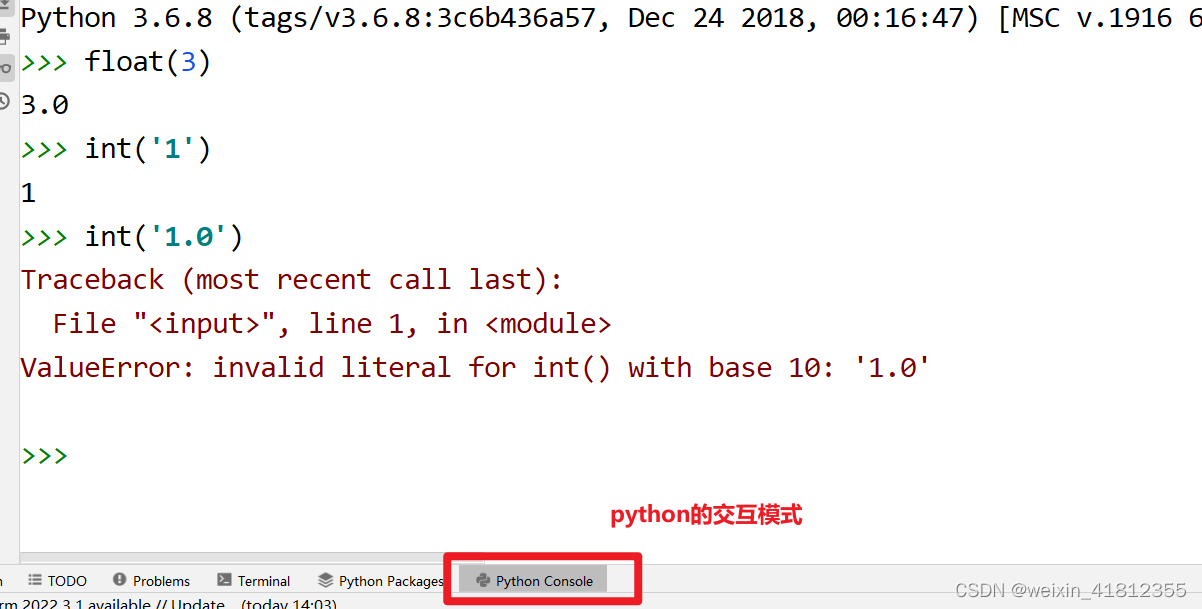
注意点:数据类型转换,不会改变原来的数据的类型,会生成一个新的数据类型- int()将其他类型转换为整型
- 1、 将float类型转换为整型
- 2、将整数类型的字符串转换为整型 ,若'3.12'会报错
- float()将其他类型转换为浮点型
- 1、可以将int类型转换为浮点型
- 2、可以将数字类型的字符串(整数类型字符串或者小数类型字符串)转换为浮点型
- str()将其他类型转换为字符串类型
- 1、任何类型都可以使用str()转换为字符串类型,一般都是加上引号
 8、快捷键(小操作)
8、快捷键(小操作)
添加引号括号:可以直接选中要添加引号或者括号的内容,书写即可
撤销:ctrl+z
删除一行:ctrl+x
复制粘贴一行:ctrl+d
快速在代码下方,新建一行:shift+回车9、运算符介绍
9.1 运算符的作用
- 计算机可以完成的运算分为很多种,不仅仅限于加减乘除
- 不同类型的运算需要依赖不同的符号
- 运算符可以让计算机认识并处理对应的计算逻辑
9.2 运算符的分类
- 算术运算符:完全常规数字运算
- 比较运算符:完成二个值的大小比较运算
- 逻辑运算符:常用业务直之间的逻辑判断
- 赋值运算符:将运算符右侧的值,赋值给左侧容器
9.3运算符的使用

9.4 比较运算符:
比较运算符的使用
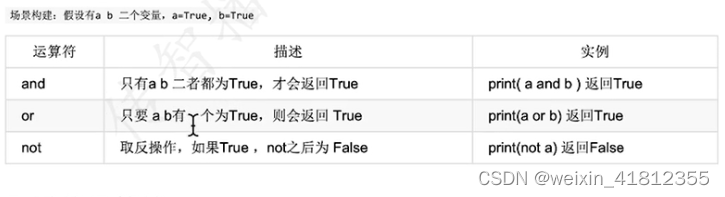
 9.5 逻辑运算符:
9.5 逻辑运算符:

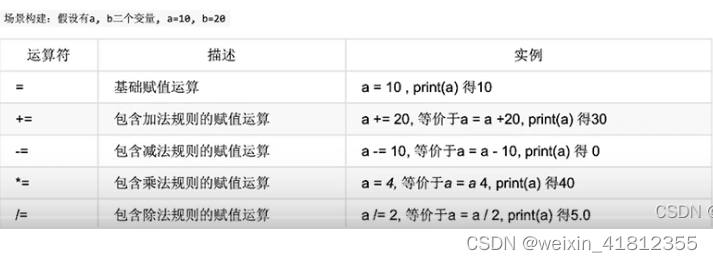
9.6 赋值运算符
 算术运算符的优先级大于比较运算符优先级大于逻辑运算符
算术运算符的优先级大于比较运算符优先级大于逻辑运算符
书写时可以使用()来区分优先级;
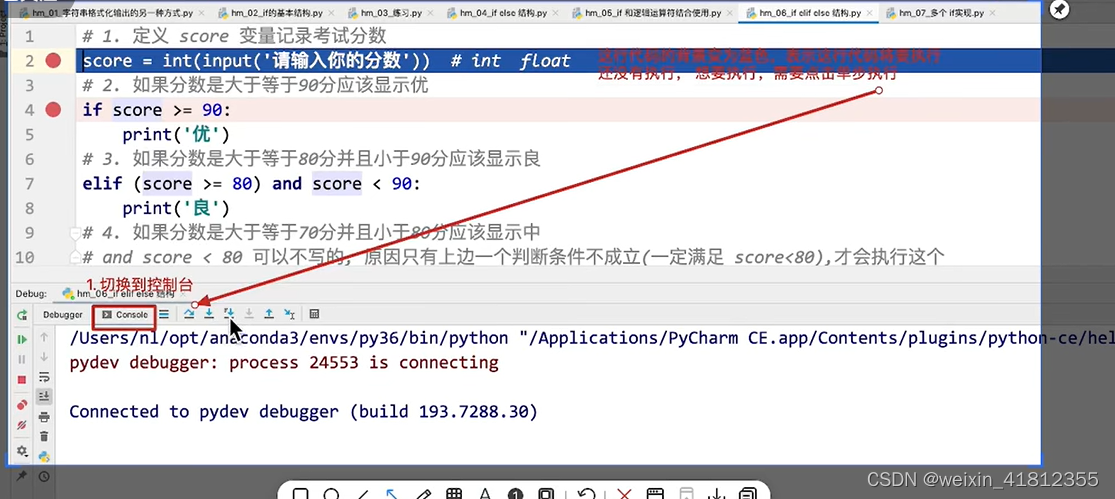
10、if的语法
10.1 if的基本使用
1、if是一个关键字,和后续的判断条件之间需要一个空格
2、判断条件后边需要一个冒号,不要少了
3、冒号之后,回车,代码需要缩进,在pc中会自动缩进,一般是4个空格,或者一个tab键
4、所有在if代码下方的缩进中书写的代码,属于if语句的代码块,判断条件为true的时候会执行
5、if 代码块中的代码,要么都会执行,要么都不执行
6、if代码块结束之后,代码要顶格书写,表示和if无关的代码
10.2 if和else的基本使用
1、else是关键字,后边需要冒号
2、冒号之后回车,同样需要缩进
3、if 和 else 的代码块代码块,只会执行其中一个
4、else需要结合if 使用10.3 if elif else的基本使用
if 判断条件1:
判断条件1成立,执行的代码
elif 判断条件2:#只有判断条件1不成立,才会判断 判断条件2
判断条件2成立执行的代码
else:
以上条件都不成立,执行的代码
1、elif 也是关键字,后边和判断条件之间需要一个空格,判断条件之后需要冒号
2、冒号之后回车需要缩进,处在这个缩进中的代码表示是elif 的代码块
3、在一个if判断中,可以有很多个elif
4、只有if 的条件不成立,才会去判断elif的条件
5、在一个if中,如果有多个elif,只要有一个条件成立,后续的所有都不在判断10.4 if的嵌套使用
if 嵌套,是指在一个if(elif else)中嵌套另一个if;
使用场景:判断条件存在递进关系(只有第一个条件满足了,才会判断第二个条件)语法:
if 判断条件1:
判断条件1成立,执行的代码
if 判断条件2:
判断条件2成立执行的代码
else:
判断条件2不成立执行的代码
else:
判断条件1不成立,执行的代码案例:
"""
案例:
取款机取钱的过程,假定你的密码是:123456 ,账户余额是1000
1、提示用户输入密码
2、判断密码是否正确
3、密码正确后,提示输入取款的金额
4、判断取款得金额和余额的关系
"""
password = input("请输入密码")
if int(password) == 123456:
money = input("请输入取款金额")
if int(money) == 1000:
print("取款成功")
else:
print("余额不足")
else:
print("密码有误")11、debug调试代码
注意点:
可能会出现的bug(pycharm软件的问题):代码中只有一个断点的时候不能debug调试查看代码的执行过程,解决方案,在代码其他任意地方多加一个断点
 12、循环的基本使用
12、循环的基本使用
12.1 while循环的基本使用
使用场景:让执行的代码按照指定的次数重复执行
语法
1、设置循环的初始条件(计数器)
2、书写循环的判断条件
while 判断条件:
# 3、需要重复执行的代码
#4、改变循环的初始条件(计数器)无限循环
无限循环的使用一般会在循环中添加一个if判断,当if 条件成立,使用关键字break来终止循环
while True:
重复执行的代码 #可以在if的上边
if 判断条件:
break #关键字的作用就是终止循环,当代码执行遇到break,这个循环就不再执行了
重复执行的代码 #可以在if的下边12.2 for循环
for 循环也可以让指定的代码重复执行
for循环可以遍历容器中的数据(
遍历:从容器中把数据一个一个取出
容器:可以简单理解为盒子,盒子中可以存放很多的数据(字符串 str,列表 list,元组 tuple,字典 dict))语法:
for 变量名 in 容器:
重复执行的代码
1、for 和in都是关键字
2、容器中有多少个数据,循环会执行多少次(0个数据,执行0次,...)
3、每次循环,会将容器中数据取出一个保存到 in 关键字前边的变量中;12.3 for做指定次数的循环
for 变量 in range(n):
重复执行的代码
1、range()是python中的函数,作用使用可以生成[0,n)之间的整数,不包含n的,一个有n个数字,所以这个循环循环n次
2、想让for循环循环多少次,n就是几
3、变量的值也是每次循环从[0,n)取出一个值,第一次取得是0,最后一次取得是n-1;
range()变形
for 变量 in range(a,b):
重复执行的代码
1、range(a,b) 作用是生成[a,b)之间的整数数字,不包含b13、break和continue
break和continue是python中的两个关键字,只能在循环中使用
# break 和continue 是python中的两个关键字,只能在循环中使用
# break:终止循环,即代码执行遇到break,循环不再执行,立即结束
# continue:跳过本次循环,即代码执行遇到continue,本次循环剩下的代码不再执行,继续下一次循环range = input("请输入字符串")
for i in range:
if(i=='e'):
break
print(i)
print('-'*90)
for i in range:
if(i=='e'):
continue
print(i)
#打印结果
请输入字符串adefgher
a
d
------------------------------------------------------------------------------------------
a
d
f
g
h
r14、字符串
定义:
- 使用单引号括起来的字符
- 使用双引号括起来的字符
- 使用三引号括起来的字符
- 特殊定义细节
- 使用\ 转义字符,将字符串本身的引号进行转义
- 双斜杠转译成单斜杠
- 字符串前边加上r""原生字符串。字符串中的\不会作为转义字符 文件操作会使用
# 1、使用\ 转义字符,将字符串本身的引号进行转义
my_name = 'I\'m 小明'
print(my_name)
# 2、双斜杠转译成单斜杠
my_name = 'I\\\'m 小明'
print(my_name)
# 3、字符串前边加上r"" 原生字符串。字符串中的\不会作为转义字符 文件操作会使用
my_name = r'I\\\'m 小明'
print(my_name)
my_name = r'I\'m 小明'
print(my_name)14.1 字符串下标访问
- 可以将字符串当做是装有很多内容的容器,通过编号可以获取到指定位置的字符
- 下标是人为定义的一种计数规则,默认下标从0开始
- 下标的使用语法为字符串名[下标值]
my_str = "qwertyuiokjhgf"
print(my_str[0])
print(my_str[4])
# 打印最后一个字符
print(my_str[-1])
# 打印倒数第二个字符
print(my_str[-2])
# 打印字符串的长度
print(len(my_str))
# 打印最后一个字符
print(my_str[len(my_str)-1])
打印结果
q
t
f
g
13
f
注意:如果字符串首尾及中间有空格,也算是一个字符;
14.2 字符串切片
通过切片操作,可以获取字符串中指定部分的字符
语法: 字符串[开始位置下标:结束位置下标:步长]
字符串[start:end:step]
start 是开始位置的下标,end 是结束位置的下标(注意,不能取到这个位置的字符)
step 步长,等差数列的差值,所取的相邻下标之间的差值,默认是1,可以不写切片示例:
str = "abcdefg"
# 正数下标 0 1 2 3 4 5 6
# 负数下标-7 -6 -5 -4 -3 -2 -1
# 1、如果步长是1,可以不写,最后一个冒号也不写
print(str[0:7])
# 2、如果开始位置是0,可以不写,但是冒号必须有
print(str[:7])
# 3、获取efg字符
print(str[4:7])
print(str[-3:7])
print('-'*30)
# 获取ef字符
print(str[-3:-1])
# 4、如果最后一个字符也要取,可以不写,但是冒号必须有
print(str[4:])
# 5、如果开始和结束都不写,获取全部内容,但是冒号必须有
print(str[:])
# 6、获取aceg
print(str[0:7:2])
print(str[::2])
# 逆转字符串,步长是-1
print(str[::-1])
结果:
abcdefg
abcdefg
efg
efg
------------------------------
ef
efg
abcdefg
aceg
aceg
gfedcba14.3 字符串的查找方法
语法及定义:
字符串.find(sub_str,start,end)
作用:在字符串中查找是否存在sub_str这样的字符串
sub_str:要查找的小的字符串
start:开始位置,从哪个下标位置开始查找,一般不写,默认是0
end 结束位置,查找到哪个下标结束,一般不写,默认是len()
返回(代码执行之后会得到什么,如果有返回,就可以使用变量保存):
1、如果在字符串中找到了 sub_str,返回sub_str第一次出现的正数下标(sub_str中第一个字符在大字符串中的下标)
2、如果没有找到,返回-1查找方法的示例:
str = "and or not and"
# 在字符串中查找and
result = str.find("and",0)
print(result)
# 在字符串中查找第二个and
result = str.find("and",result+1)
print(result)
# 在字符串中查找or
print("-----"*30)
result = str.find("or",0)
print(result)
result = str.find("or")
print(result)
结果:
0
12
------------------------------------------------------------------------------------------------------------------------------------------------------
4
414.4 字符串的替换方法
语法:
字符串.replace(old_str,new_str,count) #将字符串中old_str替换为 new_str
old_str:被替换的内容
new_str:替换为的内容
count:替换的次数,一般不写,默认是全部替换
返回:替换之后的完整的字符串,注意:原来的字符串没有发生改变替换方法的示例:
str1 = "good good study"
# 1、将str1中所有的g改为G
str2 = str1.replace('g','G')
print('str1:',str1)
print('str2:',str2)
# 2、将str1中第一个good改为GOOD
str3 = str1.replace('good','GOOD',1)
print("str3:",str3)
# 3、将str1中第二个good改为GOOD
# 先将全部的改为GOOD
str4 = str1.replace('good','GOOD',2)
# 再将第一个GOOD改为good
str4 = str4.replace('GOOD','good',1)
print("str4:",str4)
结果:
str1: good good study
str2: Good Good study
str3: GOOD good study
str4: good GOOD study
14.5 字符串的拆分
语法:
字符串.split(sep,max_split)#将字符串按照sep进行分割
sep:字符串按照什么进行拆分,默认是空白字符(空格,换行\n,tab键\t)
max_split,分割次数,一般不写,全部分割
注意:如果sep不写,想要指定分割次数 则需要按照如下方式使用
字符串.split(max_split=n) #n是次数拆分的示例:
str1 = "hello world and itcast and itheima and python"
# 1、将str1按照and 字符串进行拆分
result = str1.split('and')
print(result)
# 2、将str按照and字符进行拆分,拆分一次
result = str1.split('and',1)
print(result)
# 3、按照空白字符进行切割
result = str1.split()
print(result)
# 3、按照空白字符进行切割,只切割一次
result = str1.split(maxsplit=1)
print(result)
结果:
['hello world ', ' itcast ', ' itheima ', ' python']
['hello world ', ' itcast and itheima and python']
['hello', 'world', 'and', 'itcast', 'and', 'itheima', 'and', 'python']
['hello', 'world and itcast and itheima and python']14.6 字符串的连接方法
语法:
字符串.join(列表) #括号中的内容主要是列表,可以是其他容器
作用:将字符串插入到列表中每相邻的两个数据之间,组成一个新的字符串
列表中的数据使用:使用逗号隔开的
注意点:列表中的数据必须都是字符串,否则会报错连接示例:
list1 = ['hello', 'world', 'and', 'itcast', 'and', 'itheima', 'and', 'python']
# 1、将列表中的字符串使用空格连接起来,注意双引号中间有个空格
str1 = " ".join(list1)
print(str1)
# 2、将列表中的字符串使用and连接起来
str2 = ' and '.join(list1)
print(str2)
结果:
hello world and itcast and itheima and python
hello and world and and and itcast and and and itheima and and and python15、列表的使用
15.1 列表的定义
方法一:用[]定义,数据之间使用英文逗号隔开
name_list = []
name_list = ["","",""]
方式二:通过类实例化方法定义
data_list = list()代码示例:
list1 = list()
print(type(list1),list1)
# 类型转换 list(容器) 将其他的容器转换为列表
# 转换字符串会将字符串中的每一个字符作为一个数据存放到列表中
list2 = list('hello')
print(type(list2),list2)
结果:
<class 'list'> []
<class 'list'> ['h', 'e', 'l', 'l', 'o']15.2 列表的下标和切片
# 列表支持下标的切片操作,使用方法和字符串中的使用方法一致
# 区别:列表的切片得到的是列表
list1 = ['1','22','333','4444']
# 获取第一个数据
print(list1[0])
# 获取最后一个数据
print(list1[3])
# 第一到第3个数据
print(list1[0:3])
# 列表也支持len()
print(list1[len(list1)-1])
print(len(list1))
结果:
4444
['1', '22', '333']
4444
415.3 列表的查询操作
列表.index(数据,start,end)使用和find方法一样,同时在字符串中也有index方法 区别:返回,index()方法,找到返回第一次出现的下标,没有找到代码直接报错
list = ['1','2','4','3','4','5','2']
result = list.index('4')
print(result)
结果:
2查找-判断是否存在 判断容器中某一个数据是否存在可以使用in关键字 数据 in 容器 #如果存在返回True,如果不存在,返回False
if 6 in list:
num = list.index("6")
print(num)
else:
print("不存在数据")
结果:
不存在数据查找-统计出现的次数 统计出现的次数,使用的是count()方法 列表.count(数据) #返回数据出现的次数
if list.count("2")>=2:
num = list.index("2")
print(num)
结果:
115.4 列表的添加方法
尾部添加(最常用) 1、列表.append(数据) #将数据添加到列表的尾部 返回:返回的None(关键字,空)一般就不再使用变量来保存返回的内容想要查看添加后的列表,需要打印的是列表
my_list = []
# 1、想要在列表中添加数据
my_list.append("1")
my_list.append("2")
my_list.append("3")
print(my_list)
结果:
['1', '2', '3']2、指定下标位置添加 列表.insert(下标,数据) #在指定的下标位置添加数据,如果指定的下标位置本来有数据,原数据会右移 返回:返回的None(关键字,空)一般就不再使用变量来保存返回的内容,想要查看添加后的列表,需要打印的是列表
my_list = []
my_list.insert(1,"张")
print(my_list)
结果:
['张']3、列表合并 列表1、extend(列表2) #将列表 2中的所有数据逐个添加到列表1的尾部 返回:返回的None(关键字,空)一般就不再使用变量来保存返回的内容,想要查看添加后的列表,需要打印的是列表
list1 = ['1','2','3','4']
list2 = ['男','女']
list1.extend(list2)
print(list1)
list2.extend(list1)
print(list2)
结果:
['1', '2', '3', '4', '男', '女']
['男', '女', '1', '2', '3', '4', '男', '女']15.5 列表的修改操作
# 1、想要修改列表中的指定下标位置的数据 # 列表[下标] = 数据 # #字符串中字符不能使用下标修改
my_list = ['1','2']
my_list[1] = '杨'
print(my_list)
# 修改最后一个位置的数据,改成hello
my_list[-1] = 'hello'
print(my_list)
结果:
['1', '杨']
['1', 'hello']15.6 列表的删除操作
删除操作:在列表中删除中间的数据,那么后面的数据会向前移动 1、根据下标删除 列表.pop(下标) #删除指定下标位置对应的数据 (1)、下标不写,默认删除最后一个数据(常用) (2)、书写存在的下标,删除对应下标位置的数据 返回:返回的删除的数据 2、根据数据删除 列表.remove(数据值) #根据数据值删除 返回:None 注意:如果要删除的数据不存在,会报错 3、清空数据 列表.clear()
my_list = ['1','2','3','4','5','6',7,'8']
# 1、删除最后一个位置的数据
result = my_list.pop()
print(my_list)
print(result)
# 删除下标为1的数据
result = my_list.pop(1)
print(result)
print(my_list)
# 删除数据为7的数据
result = my_list.remove(7)
print(result)
print(my_list)
结果:
['1', '2', '3', '4', '5', '6', 7]
8
2
['1', '3', '4', '5', '6', 7]
None
['1', '3', '4', '5', '6']
15.7 列表的反转和逆置
列表中反转和倒置 1、列表[::-1] #使用切片的方法,会得到一个新列表,原列表不会发生改变 2、列表.reverse() #直接修改原列表,返回Non
my_list = ['1','2','3','4','5','6']
# 1、使用切片的方法会得到一个新列表
list2 = my_list[::-1]
print(my_list)
print(list2)
# 2、使用reverse方法,直接修改原列表
my_list.reverse()
print(my_list)
result = my_list.reverse()
print(result)
结果:
['1', '2', '3', '4', '5', '6']
['6', '5', '4', '3', '2', '1']
['6', '5', '4', '3', '2', '1']
None
15.8 列表的复制
1、使用切片 变量 = 列表[:] 2、使用copy 方法 变量= 列表.copy()
list02 = my_list.copy()
print(list02)
my_list.reverse()
print(list02)
结果:
[7, 6, 5, 4, 3, 2, 1]
[7, 6, 5, 4, 3, 2, 1]15.9 列表的排序
列表的排序,一般来说都是对数字进行排序的 列表.sort() 按照升序排列,从小到大 列表.sort(reverse = True) 降序排列,从大到小
my_list = [1,4,5,4,]
# 升序排列
my_list.sort()
print(my_list)
# 降序排列
my_list.sort(reverse=True)
print(my_list)
结果:
[1, 4, 4, 5]
[5, 4, 4, 1]15.10 列表的嵌套
# 列表嵌套,列表中的内容还是列表 # 使用下标来确定获取的是什么类型的数据,然后确定可以继续进行什么操作
person_info = [['前端','01','18'],['后端','33','18'],['测试','22','44']]
print(person_info[1]) #['后端', '33', '18']
print(len(person_info)) #3
print(person_info[0][2]) #18
print(person_info[0][0][0]) #前15.11 列表去重
列表中存在多个数据,需求,去除列表中重复的数据;
方式1、遍历原列表中的数据判断在新列表中是否存在,如果存在,不管,如果不存在放入新的列表中
遍历:for循环实现
判断是否存在:可以用in
存入数据:append()
方式2、
在python汇总还有一种数据类型(容器),称为是集合(set)
特点:集合中不能有重复的数据(如果有重复的数据会自动去重)
可以使用集合的特点对列表去重
1、使用set()类型转换将列表转换为集合类型
2、再使用list()类型转换将集合转换为列表
缺点:不能保证数据在原列表中出现的顺序(一般来说,也不考虑这件事)
my_str = [5,4,1,2,3,4,1,2,3,4,5,6,3,2,1]
print(set(my_str))
new_str = set(my_str)
print(list(new_str))
str = []
for i in my_str:
if i not in str:
str.append(i)
print(str)16、元组的使用
元组:tuple,元组的特点和列表非常相似 1、元组中可以存放任意类型的数据 2、元组中可以存放任意多个数据
区别: 1、元组中的数据内容不能改变,列表中的可以改变的 2、元组使用(),列表使用[]
应用:在函数的传参或者返回值中使用,保证数据不会被修改
元组的定义:
# 定义 # 1、使用类实例化的方式 # 2、直接使用()方式
代码示例:
# 1、类实例化的方式
# 1.1定义空元组(不会使用的)
my_tuple1 = tuple()
print(type(my_tuple1),my_tuple1)
# 1.2类型转换
# 可以将列表转换为元组,只需要将[],变为(),同时可以将元组转换列表,将()变为[]
my_tuple2 = tuple([1,2,3])
print(my_tuple2)
# 转换字符串,和列表中一样,只是将列表的[]变为()
my_tuple3 =tuple ('hello')
print(my_tuple3)
结果:
<class 'tuple'> ()
(1, 2, 3)
('h', 'e', 'l', 'l', 'o')
# 2.直接使用()定义
my_tuple4 = (1,'杨',3.14,False)
print(my_tuple4)
# 3、将元组转换为列表
my_tuple11 = list(("杨","张"))
print(my_tuple11)
# 3、元组可以使用+连接生成新的元组
my_tuple12 = ("杨","张")+("张","杨")
print(my_tuple12)
# 3.特殊点,定义只有一个数据的元组时,数据后边必须有一个逗号
my_tuple5 = (1,)
print(my_tuple5)
结果:
(1, '杨', 3.14, False)
['杨', '张']
('杨', '张', '张', '杨')
(1,)常用的方法:
由于元组中的数据不能修改,所以只有查看的方法 1、在元组中也可以使用下标和切片获取数据 2、在元组中存在index方法,查找下标,如果不存在会报错 3、在元组中存在count方法,统计数据出现的次数 4、在元组中可以使用in操作,判断数据是否存在 5、len()统计个数 以上方法的使用和列表中一样的
代码示例:
my_tuple6 = ("1",'2','3','4','5')
print(my_tuple6[-1])
# 倒序输出,步长为-1
my_tuple7 = my_tuple6[::-1]
print(my_tuple7)
# 正序输出,步长为1
my_tuple10 = my_tuple6[::1]
print(my_tuple10)
print('__'*800)
# 倒序输出
my_tuple8 = reversed(my_tuple6)
print(tuple(my_tuple8))
print('---'*800)
# 元组的反转
A=[(4,5),(4,6),(6,9),(3,6)]
B=[k[::-1] for k in A]
print(B)
C=[(4,5),(4,6),(6,9),(3,6)]
D=[tuple(reversed(k) for k in A)]
print(B)
E = (1,2,3,3,3,4,4,5,5,0)
F = E.count(9)
print(F)
if 3 in E:
print(E)
print('__'*800)
结果:
5
('5', '4', '3', '2', '1')
('1', '2', '3', '4', '5')
____________________________________________________________
('5', '4', '3', '2', '1')
------------------------------------------------------------------------------------------
[(5, 4), (6, 4), (9, 6), (6, 3)]
[(5, 4), (6, 4), (9, 6), (6, 3)]
0
(1, 2, 3, 3, 3, 4, 4, 5, 5, 0)
____________________________________________________________
17、字典的使用
定义:
1、字典dict,字典中的数据是由键值对组成的(键表示数据的名字,值就是具体的数据)
2、在字典中一组键值对是一个数据,多个键值对之间使用逗号隔开
变量={key:value,key:value,...}
3、一个字典中的键是唯一的,不能是重复的,值可以是任意数据
4、字典中的键 一般都是字符串,可以是数字,不能是列表
# 1、使用类实例化定义
my_dict = dict()
print(my_dict)
# 2、使用{}定义
# 2.1空字典
my_dict1 = dict()
print(type(my_dict1),my_dict1)
# 2.2非空字典
my_dict2 = {"name":"杨","age":18,"is_man":False,"like":["跳绳","跑步","冲浪"]}
print(my_dict2)
注意:不能转元组、列表或者字符串
17.1 添加和修改数据
字典[键] = 数据值 1、如果键已经存在,就是修改数据值 2、如果键不存在,就是添加数据(即添加键值对)
my_dict = {"名字":"小明","age":"18","like":["上网","喝酒","抽烟"]}
print(my_dict)
# 添加性别 sex="男" 只能在后面添加
my_dict ["sex"] = "男"
print(my_dict)
# 修改年龄为19
my_dict["age"] = 19
print(my_dict)
# 添加一个爱好学习,本质是向列表中添加一个数据
my_dict["like"].append("学习")
print(my_dict)17.2 删除数据
1、删除指定键值对 del 字典[键] # 2、清空 字典.clear()
my_dict = {'名字': '小明', 'age': 19, 'like': ['上网', '喝酒', '抽烟', '学习'], 'sex': '男'}
# 删除名字的键值对 del 或者 pop
del my_dict["名字"]
print(my_dict)
# my_dict.pop("名字")
# print(my_dict)
# 删除爱好中的喝酒 本质是删除列表中的数据
# my_dict["like"].pop(1)
# print(my_dict)
my_dict["like"].remove("喝酒")
print(my_dict)
# 清空键值对
my_dict.clear()
print(my_dict)17.3 查询-获取对应的数据
字典中没有下标的概念,想要获取数据值,要使用key(键)来获取 使用 字典[键]: 1、如果键存在,返回键对应的数据值 2、如果键不存在,会报错 使用 字典.get(键) 字典.get(键,数据值) 1、数据值一般不写,默认是None 返回 : 1.如果键存在,返回键对应的数据值 2、如果键不存在,返回的是 括号中书写的数据值(None) 一般建议使用get方法
y_dict = {"名字":"小明",'age': 19, 'like': ['上网', '喝酒', '1', '抽烟', '学习']}
# 获取名字小明
print(my_dict["名字"])
print(my_dict.get("名字"))
# 字典中有键值对名字,获取名字时无论数据传了什么都会打印字典中对应的数据
print(my_dict.get("名字","zzz"))
# 2、获取sex姓名
print(my_dict.get("sex")) # None
# print(my_dict["sex"]) 代码会报错。因为字典中没有键sex
# 字典中没有键值对sex,获取性别时传了数据男 , 打印结果是男
print(my_dict.get("sex","男")) #男
# 3、获取第二个爱好
print(my_dict["like"][1])
print(my_dict.get("like")[1])17.4 字典的遍历
对字典中的键进行遍历
for 变量 in 字典:
print(变量) #变量就是字典的 key,键
for 变量 in 字典.keys(): #字典.keys() 可以获取字典中所有的键
print(变量)
my_dict ={'名字': '小明', 'age': 19, 'like': ['上网', '喝酒', '抽烟', '学习'], 'sex': '男'}
for k in my_dict:
print(k) #获取字典中所有的键
for k in my_dict.keys(): #获取字典中所有的键
print(k)对字典中的值进行遍历
for 变量 in 字典.values(): #字典.values()可以获取字典中所有的值
print(变量)
for k in my_dict.values(): #获取字典中所有的值
print(k)对字典中的键值对进行遍历
#变量1是键,变量2是键对应的值
for 变量1,变量2 in 字典.items(): #字典.itens() 获取键值对
print(变量1,变量2)
for i, j in my_dict.items(): #获取字典中所有的键值对
print(i,j)补充
# 1、字符串,列表,支持加法运算 # 2、字符串 列表 元组 支持 乘一个数字 # 3、len()在容器中都可以使用 # 4、in关键字在容器中都可以使用,注意,在字典中判断的是字典的键是否存在
18、函数
18.1 函数的定义和调用
函数需要先定义后再调用;
调用语法:
函数名()
形参:形式参数,是在函数定义的时候,括号中的变量
实参:实际参数,是在函数调用的时候,括号中的变量(数据值)
18.2 文档的注释
书写位置,在函数名的下方使用 三对双引号进行的注释
作用:告诉别人这个函数如何使用的,干什么的;
查看,在调用的时候,将光标放到函数名上,使用快捷键 Ctrl q(windows)
Mac(ctrl j);
ctrl B 转到函数声明中查看(按住Ctrl 鼠标点击左键)
18.3 函数的嵌套调用
在一个函数定义中调用另一个函数
1、函数定义不会执行函数体中的代码
2、函数调用会执行函数体中的代码
3、函数体中代码执行结果会回到函数被调用的地方继续向下执行

18.4 函数的返回值

18.5 变量的引用

# 将 数据1的地址存到a对应的内存中
a=1
print(id(a))
# 将变量a中的引用保存到变量b
b=a
print(id(b))
# 将数据10的地址保存到a对应的地址,即a的引用变了
a=10
print(id(a))
print(id(b))
结果:
1849917552
1849917552
1849917840
1849917552
18.6 可变类型和不可变类型

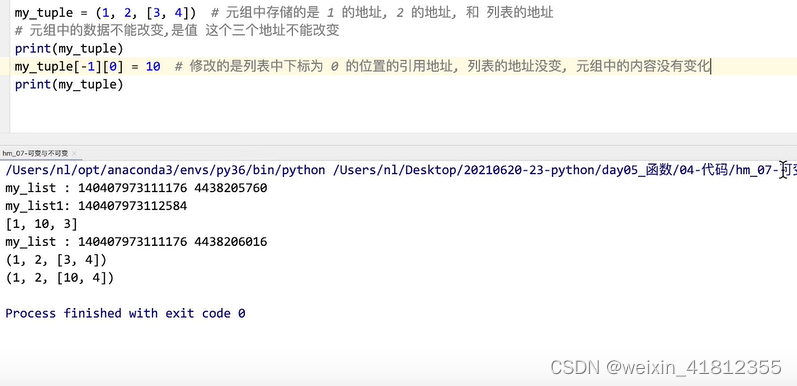
课后练习
def func(list1):
list1 = [3,4]
my_list = [1,2]
func(my_list)
print(my_list)结果: 【1,2】
解析: def func(list1): list1 = mylist 此时两个变量的引用是相同的
list1=[3.4]: 此时,list1变量的引用发生率变化,问,my_list的引用没有改变,数据不会变
def func(list1):
list1[0] = 4
my_list = [1,2]
func(my_list)
print(my_list)
结果【4,2】
解析:def func(list1): lsit1 = my_list
list1[0] = 4: 修改的是列表中下标为0位置的数据,没有修改列表的引用
def func(list1):
list1 += ['a','b']
# list1.extend(['a','b','c'])
my_list = [1,2]
func(my_list)
print(my_list)结果:[1, 2, 'a', 'b']
解析:def func(list1):list1 = my_list 引用相同
list1+=['a','b']:list1.extend(['a','b']) 没有直接使用等号改变形参的引用,形参的数据的改动会影响实参值
总结:
1、只用 = ,可以改变引用
2、可变类型做参数,在函数内部,如果不用 = 直接修改形参的引用,对形参进行的数据修改会同步到实参中
18.7 交换两个变量的值
方法一:引用第三变量;
方法二:使用数学中的方法(加减乘除)
方法三:(重点掌握,python独有)
a=10
b=20
a,b = b.a
print(a,b)
结果:20 10
18.8 组包和拆包
组包:将多个数据值使用逗号连接,组成元组
拆包:将容器中的数据值使用多个变量分别保存的过程,注意:变量的个数和容器中数据的个数要保持一致

18.9 局部变量和全局变量


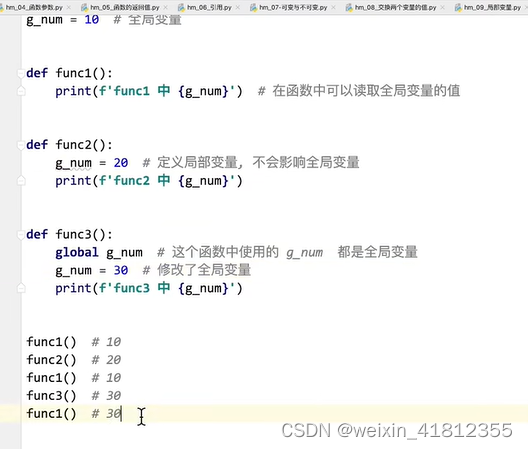
注意:使用global 关键字对变量进行声明为全局变量时,必须写在函数内部的第一行,否则报错
18.10 函数返回多个数据值

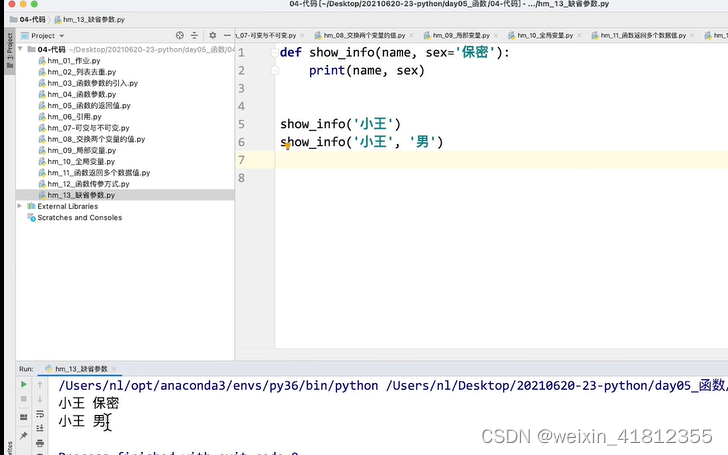
18.11 函数的参数


缺省参数
sex是缺省参数,在定义的时候就给他一个默认的值:
多值参数(不定长参数/可变参数)



18.12 函数传参中的拆包
my_list = [1,2,3,4]
my_dict = {'a':1,'b':2,'c':3,'d':4}
def my_sum(*args,**kwargs):
num = 0
for i in args:
num += i
for j in kwargs.values():
num += j
print(num)
# 想要将字典中的数据,作为关键字传参,需要使用**对字典进行拆包
my_sum(**my_dict)
# 想要将列表(元组)中的数据分别作为位置参数进行传参,需要对列表进行拆包操作
my_sum(*my_list)18.13 匿名函数的定义
匿名函数:就是使用lambda关键字定义的函数
一般称为使用def关键字定义的函数为,标准函数
匿名函数只能书写一行代码
匿名函数的返回值不需要return ,一行代码(表达式)的结果就是返回值
语法:





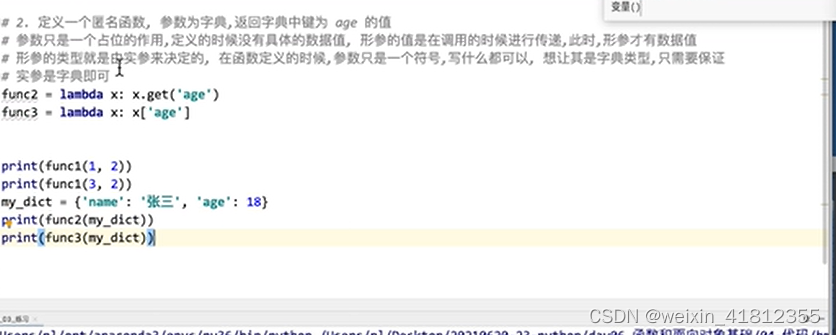
18.14 匿名函数作为函数的参数-列表中的字典排序


19 面向对象
基本介绍
面向对象是一个编程思想(写代码的套路)
编程思想:
1、面向过程
2、面向对象
以上两种都属于写代码的套路,最终目的都是为了将代码写出来,只不过过程和思考方法不太一样
面向过程
- 关注的是 具体步骤的实现,所有的功能都自己书写
- 亲力亲为
- 定义一个函数,最终按照顺序调用函数
面向对象
- 关注的是结果,谁(对象)能帮我做这件事
- 偷懒
- 找一个对象,让对象去做
类和对象
面向对象的核心思想,找一个对象去帮我们处理事情
在程序代码中 对象是由类创建的
类和对象,是面向对象编程思想中非常重要的两个概念
类
- 抽象的概念,对多个特征和行为相同或相似事物的统称
- 泛指的(指代多个,而不是具体的一个)
对象
- 具体存在的一个事务,看得见摸得着的
- 特指的(指代一个)
面向代码的步骤
- 定义类,在定义类之前先设计类
- 创建对象,使用第一步定义的类创建对象
- 通过对象调用方法
面向对象基本代码的书写
1、定义类
先定义简单的类,不包含属性,在python中定义类需要使用关键字class
方法:方法的本质是在类中定义的函数,只不过,第一个参数是self
class 类名:
# 在缩进中书写的内容,都是类中的代码
def 方法名(self): #就是一个方法
pass
2、创建对象
创建对象是使用类名()进行创建,
类名() #创建一个对象,这个对象在后续不能使用
# 创建的对象想要在后续的代码中继续使用,需要使用一个变量,将这个对象保存起来
变量 = 类名() #这个变量中保存的是对象的地址,一般可以成为这个变量为对象
#一个类可以创建多个对象,只要出现类名()就是创建一个对象,每个对象的地址是不一样的
3、调用方法
对象.方法名()
列表.sort()
列表.append()
self 的说明
class Cat:
#在缩进中书写 方法
def eat(self): #self会自动出现,暂不管
print('小猫爱吃鱼...')
black_cat.eat()
1、从函数的语法上讲,self是形参,就可以是任意的变量名,只不过我们习惯性将这个形参写作self
2、self 是普通的形参,但是在调用的时候没有传递实参值,原因是,python解释器在执行代码的时候,自动的将这个方法的对象传递给了self ,即self本质上就是对象
3、验证,只需要确定通过哪个对象调用,对象的引用和self的引用是一样的
4、self是函数中的局部变量,直接创建的对象是全局变量
对象的属性操作
添加属性
对象.属性名 = 属性值
1、类内部添加
在内部方法中,self是对象
self.属性名 = 属性值
# 在类中添加属性一般写作 __init__方法中
2、类外部添加
对象.属性名 = 属性值 # 一般不使用
获取属性
对象.属性名
1、类内部
在内部方法中,self是对象,
self.属性名
2、类外部
对象.属性名 #一般很少使用
19.2 魔法方法__init()__方法的使用


19.3 魔法方法 __str__()的使用


19.4 魔法方法 __del__了解


19.5 私有方法和公有方法

公有:
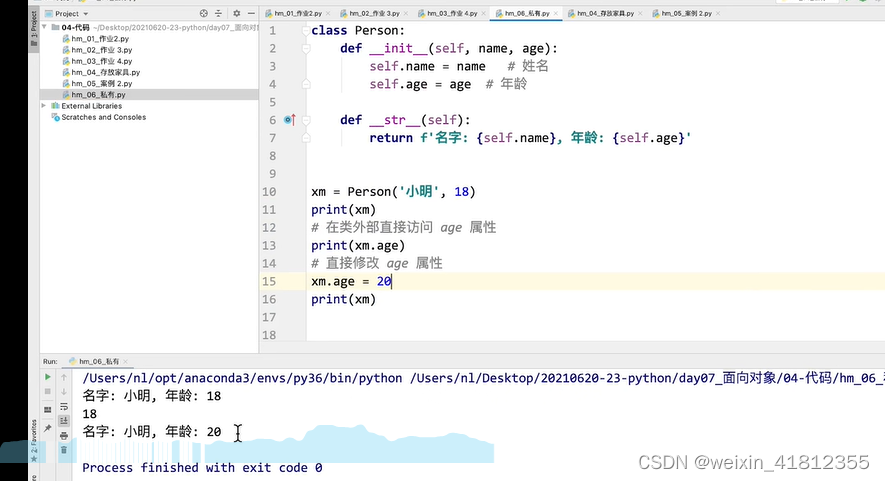
私有:
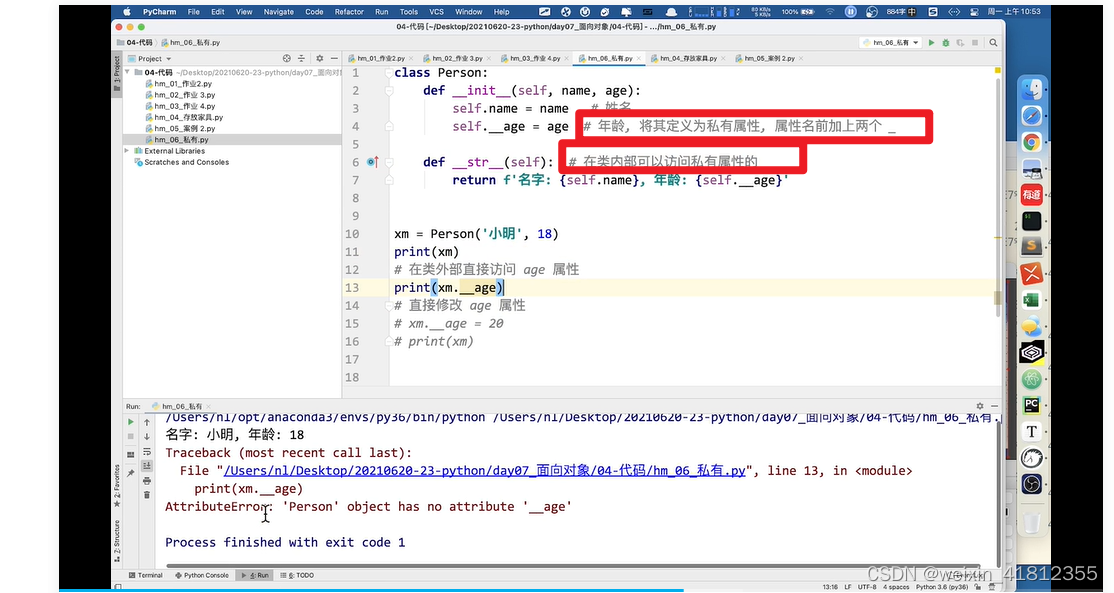
私有的本质

19.6 继承
继承的语法:
class A: #没有写父类,但也有父类,object,object类是python钟最顶级的类
pass
class B(A): #类B,继承类A
pass
术语:
1、A类,称为是父类(基类)
2、B类,称为是子类(派生类)
继承之后的特点:
子类(B)继承父类(B)之后,子类的对象可以直接使用父类中定义的公有属性和方法
结论
python中 对象.方法()调用方法
1、先在自己的类中去找有没有这个方法,如果有,直接调用
2、如果没有去父类中查找,如果有,直接调用
3、如果没有,去父类的父类中查找,如果有直接调用
5、如果object类中有,直接调用,如果没有,代码报错
19.7 重写
重写:在子类中定义了和父类中名字相同的方法,就是重写
重写的原因:父类中的方法,不能满足子类对象的需求,所以重写
重写之后的特点:调用子类字节的方法,不能调用父类中的方法
重写的方式:
1、覆盖(父类中功能完全抛弃,不要,重写书写)
2、扩展(父类中功能还调用,只是添加一些新的功能)(使用较多)
19.8覆盖
1、直接在子类中 定义和父类中名字相同的方法
2、直接在方法中书写新的代码
class Dog:
def bark(self):
print('wnagwangjiao...')
class XTQ(Dog):
# XTQ类bark 方法不再是汪汪叫,改为
#1、先嗷嗷嗷叫(新功能),2、汪汪汪叫(父类中功能)3、嗷嗷嗷叫(新功能)
def bark(self):
print('嗷嗷嗷叫...')
# 调用父类中的代码
super().bark() #print() 如果父类中代码有多行呢?
print('嗷嗷嗷叫...')
res = XTQ()
res.bark()
扩展父类中的功能
1、直接在类中 定义和父类中名字相同的方法
2、在合适的地方调用 父类中方法 super().方法()
3、书写添加的新功能
19.9 多态
1、是一种写代码,使用的一种技巧
2、同一个放阿飞,传入不同的对象,执行得到不同的结果,这种现象称为是多态
3、多态可以增加代码的灵活度
.......
哪个对象调用的方法,就去自己的类中去查找这个方法,找不到去父类中找
19.10对象的划分
python中一切皆对象,即使用class定义的类也是一个对象
实例对象(实例)
1、通过类名(创建的对象,我们称为实例对象,简称实例
2、创建对象的过程称为是类的实例化
3、我们平时所说的对象就是指 实例对象(实例)
4、每个实例对象,都有自己的内存空间,在自己的内存空间中保存自己的属性(实例属性)
类对象(类)
1、类对象就是类,或者可以认为是类名
2、类对象是Python解释器在执行代码的过程中创建的
3、类对象的作用:(1)使用类对象创建实例 类名(),(2)类对象也有自己的内存空间,可以保存一些属性值信息(类属性)
4、在一个代码中,一个类 只有一份内存空间
19.11 属性的划分
实例属性
1、定义和使用
在init方法中,使用self.属性名 = 属性值 定义
在方法中是使用self.属性名来获取(调用)
2、内存
实例属性,在每个实例中都存在一份
3、使用时机
(1)基本上99%都是实例属性,即通过self去定义
(2)找多个对象来判断这个值是不是都是一样的,如果都是一样的,同时变化,则一般定义Wie类属性,否则定义为实例属性
类属性
1、定义和使用
在类内部,方法外部,直接定义的变量就是类属性
使用:类对象.属性名 = 属性值or 类名.属性名 = 属性值
类对象.属性名 or 类名.属性名
2、内存
只有类对象中存在一份
19.12方法的划分
实例方法
定义:
#在类中直接定义的方法 就是实例方法
class Demo:
def func(self): #参数一般写作self,表示的是实例对象
pass
定义时机(什么时候用)
如果在方法中需要使用实例属性(即需要使用self),则这个方法必须定义为实例方法
调用
对象.方法名() #不需要给self传参
类方法
定义:
#在书法名字的上方书写@classmethod装饰器(使用 @classmethod装饰的方法)
class Demo:
@classmethod
def func(cls): #参数一般写作cls,表示的是类对象(即类名)
pass
定义时机(什么时候用)
1、前提,方法中不需要使用 实例属性(即self)
2、用到了类属性,可以将这个方法定义为类方法
调用
1、通过类对象调用
类名.方法名 #也不需要给cls传参,python解释器自动传递
2、通过实例对象调用
实例.方法名() #也不需要给cls传参,python解释器自动传递
静态方法(基本不用)
定义:
#在方法名字的上方书写@staticmethod 装饰器
class Demo:
@staticmethod
def func(): #一般没有参数
pass
定义时机(什么时候用):
1、前提,方法中不需要使用 实例属性(即self)
2、也不使用类属性,可以将这个方法定义为静态方法
调用:
# 1、通过类对象调用
类名.方法名()
#2、通过实例对象调用
实例.方法名()
19.13 其他方法补充

20 文件
20.1 文件介绍:

20.2 文件操作:


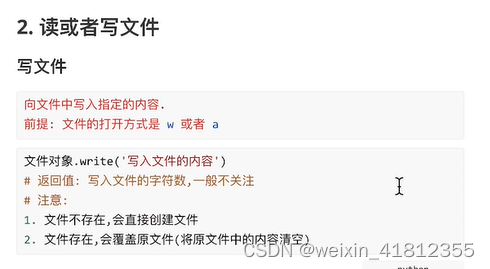


20.3 with open 打开文件

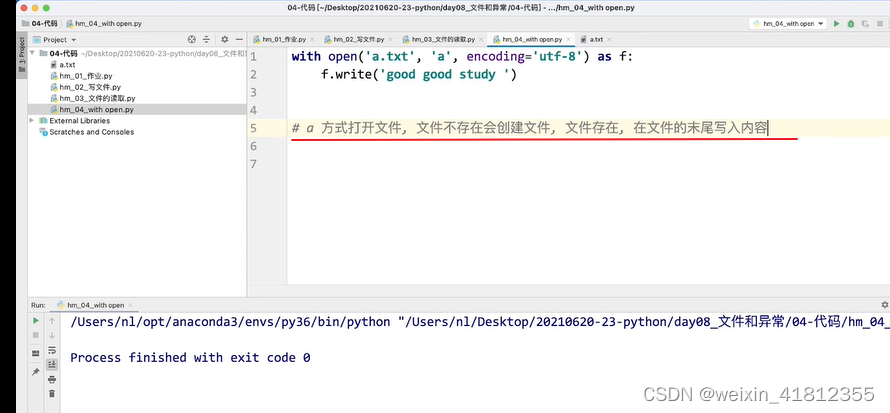
20.4 按行读取文件内容
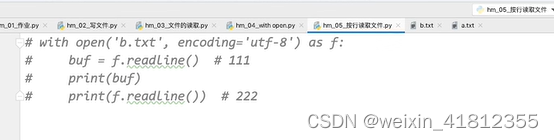



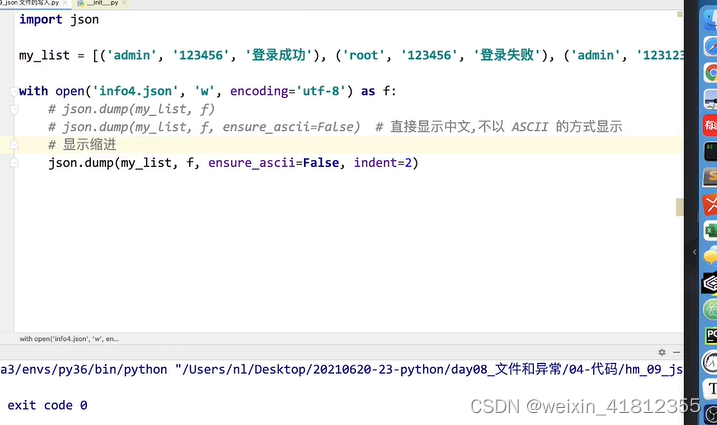
20.5 json文件






json的写入

21异常
21.1 捕获异常
异常捕获的完整版本
完整版本的内容,不是说每一次都要全部书写,根据自己的需要,去选择其中的进行使用
try:
可能发生异常的代码
except 异常类型1:
发生异常类型1执行的代码
# Exception 是常见异常类的父亲,这里书写exception,可以捕获常见的所有异常,as变量,这个变量是一个异常类的对象,print(变量)可以打印异常信息
except Exception as 变量:
发生其他类型的异常,执行的代码
else:
没有发生异常会执行的代码
finally:
不管有没有发生异常,都会执行的代码
21.2 异常的传递
- 当函数/方法执行出现异常,会将异常传递给函数/方法的调用一方;
- 如果传递到主程序,仍然没有异常处理,程序才会被终止;
- 提示:
- 在开发中,可以在主函数中增加异常捕获;
- 而在主函数中调用的其他函数,只要出现异常,都会传递到主函数的异常捕获中
- 这样就不需要在代码中,增加大量的异常捕获,能够保证代码的整洁
异常传递是python钟已经实现好了,我们不需要操作,我们知道异常会进行传递;
异常传递:在函数嵌套调用的过程中,被调用的函数,发生了异常,如果没有捕获,会将这个异常向外传递...如果传到最外层还没有捕获,才报错;
22、 模块
1、python源代码文件就是一个模块
2、模块中定义的变量 函数类,都可以让别人使用,同样,可以使用别人定义的(好处:别人定义好的不需要我们再次书写,直接使用即可)
3、想要使用 别人的模块中的内容工具(变量,类,函数),必须先导入模块才可以
4、我们自己写的代码,想要作为模块使用,代码的名字需要满足标识符的规则(由数字,字母下换线组成,不能以数字开头)
22.1 模块的导入
导入模块的语法
方式一:
import 模块名
#使用模块中的内容
模块名.工具名
#举例
import random
import json
random.randint(a,b)
json.load()
json.dump()
方式二
from 模块名 import 工具名
#使用
工具名 #如果是函数和类需要加括号
# 举例
from random import randint
from json import load,dump
randint(a,b)
load()
dump()
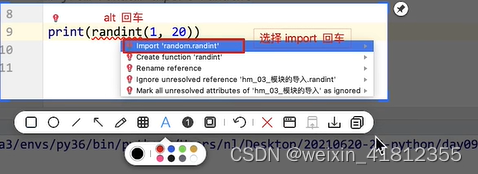
导入包的快捷键:鼠标放到要导包的函数旁边,alt+回车
注意:
对于导入的模块和工具可以使用as关键字给其起别名
注意:如果起别名,原来的名字就不能用了,只能使用别名
22.2 模块的查找顺序
在导入模块的时候,会先在当前目录中找模块,如果找到,就直接使用
如果没有找到回去系统的目录中进行查找,找到,直接使用
没有找到,报错
注意点:
定义代码文件的时候,你的代码名字不能和你要导入的模块名字相同

22.3 __name__的作用
1、每个代码文件都是一个模块
2、在导入模块的时候,会执行模块中的代码(三种方法都会)
3、__name__变量
3.1、__name__变量是python解释器自动维护的变量
3.2、__name__变量,如果代码是直接运行,值是"__main__"
3.3、__name__变量,如果代码是被导入执行,值是 模块名(即代码文件名)
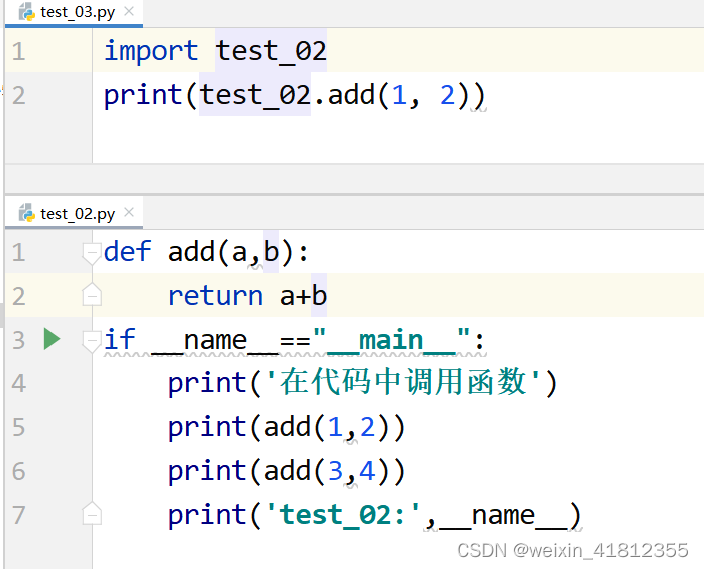
23 包的概念
在python中,包是一个目录,只不过在这个目录存在一个文件
__init__.py(可以是空的)
将功能相近或者相似的代码放在一起的
----------
在python中使用的时候,不需要可以是区分是包还是模块,使用方式是一样的
random模块(单个代码文件)
json 包(目录)
1、import 报名
2、alt 回车 快捷导入
24 unitest框架
介绍
框架
说明:
1、框架英文单次framework 2、为解决一类事情的功能集合
>需要按照框架的规定去写代码
什么是UnitTest框架?
uniTest是python自带的一个单元测试框架,用它来做单元测试。
----
自带的框架:不需要单外安装,只要安装了python就可以使用
第三方框架:想要使用 需要先安装后使用pytest
------
单元测试框架:主要用来做单元测试,一般单元测试是开发做的。
对于测试来说,unitest框架的作用是自动化脚本(用例代码)执行框架
(使用unitest框架来管理运行多个测试用例的)
为什么使用unitest框架?
1、能够组织多个用例去执行
2、提供丰富的断言方法(让程序代码代替人工自动的判断预期结果和实际结果相符)
3、能够生成测试报告
24.2 unitest的核心要素


24.3 TestCase测试用例
1、是一个代码文件,在代码文件中来书写真正的用例代码
2、代码文件的名字必须按照标识符的规则来书写(可以将代码的作用在文件的开头使用注释说明)
步骤:
1、导包(unittest)
2、自定义测试类
3、在测试类中书写测试方法
4、执行用例
# 1、导包
import unittest
# 2、自定义测试类,需要继承unitest模块中的TestCase类即可
class TestDemo(unittest.TestCase):
# 3、书写测试方法,即用例代码,目前没有真正的用例代码,使用print代替
# 书写要求,测试方法必须以test_开头(本质是以test开头)
def test_method1(self):
print("测试方法1")
def test_method2(self):
print("测试方法2")
# 4、执行用例(方法
# 4、1将光标放在类名的后边运行,会执行类中的所有的测试方法
# 4、2将光标放在方法名后面,只执行当前的方法
常见错误分析
问题一代码文件的命名不规范
1、代码文件的名字以数字开头
2、代码文件名字中有空格
3、代码代码文件名字有中文
4、其他的特殊符号
(数字,字母,下划线组成,不能以数字开头)
问题2代码运行没有结果
右键运行没有unitests for 的提示,出现的问题
方案:
1、重新新建一个代码文件,将写好的代码复制进去
2、删除已有的运行方式


24.4 TestSuite 和TestRuner的书写
TestSuite(测试套件):管理打包组装TestCase(测试用例)文件的
TestRunner(测试执行):执行TestSuite(套件)
步骤:
1、导包(unittest)
2、实例化(创建对象)套件对象
3、使用套件对象添加用例方法
4、实例化运行对象
5、使用运行对象去执行套件对象
# 1、导包
import unittest
# 2、实例化(创建对象)套件对象
from testcase_01.test_01 import TestDemo1
from testcase_01.test_03 import TestDemo2
suite = unittest.TestSuite()
#3、使用套件对象添加用例方法
#方式一,套件对象.addTest(测试列明(‘方法名’))#建议测试类名和方法名直接去复制,不要手写
suite.addTest(TestDemo1('test_method1'))
suite.addTest(TestDemo2('test_method2'))
#4、实例化运行对象
runner = unittest.TextTestRunner()
#5、使用运行对象去执行套件对象
# 运行对象.run(套件对象)
runner.run(suite)添加测试方法的另一种书写
# 1、导包
import unittest
# 2、实例化(创建对象)套件对象
from testcase_01.test_01 import TestDemo1
from testcase_01.test_03 import TestDemo2
suite = unittest.TestSuite()
#3、使用套件对象添加用例方法
#方式二,将一个测试类中的所有方法进行添加
#套件对象.addTest(unittest.makeSuite(测试类名))
#缺点:makeSuite() 不会显示
suite.addTest(unittest.makeSuite(TestDemo1))
suite.addTest(unittest.makeSuite(TestDemo2))
#4、实例化运行对象
runner = unittest.TextTestRunner()
#5、使用运行对象去执行套件对象
# 运行对象.run(套件对象)
runner.run(suite)查看结果的方法:

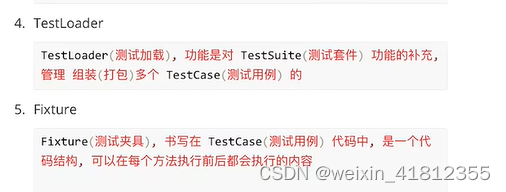
24.5 TestLoader(测试加载)
Testloader(测试加载),作用和TestSuite的作用是一样的,对TestSuite功能的补充,用来组装测试用例的
比如:如果testcase的代码文件有很多,
使用步骤:
1、导包
2、实例化测试加载对象并添加到用例中 ---》得到的是suite对象
3、实例化运行对象
4、运行对象执行套件对象
# 1、导包
import unittest
# 2、实例化加载对象并添加用例
#unittest.TestLoader().discover('用例所在的路径','用例的代码文件名')
#用例所在的路径,建议使用相对路径,用例的代码文件名可以使用*(任意多个任意字符)通配符
suite = unittest.TestLoader().discover('./testcase_01','test_0*.py')
# 3、实例化运行对象
runner = unittest.TextTestRunner()
# 4、执行
runner.run(suite)24.6 fixture的介绍




24.7fixture的使用

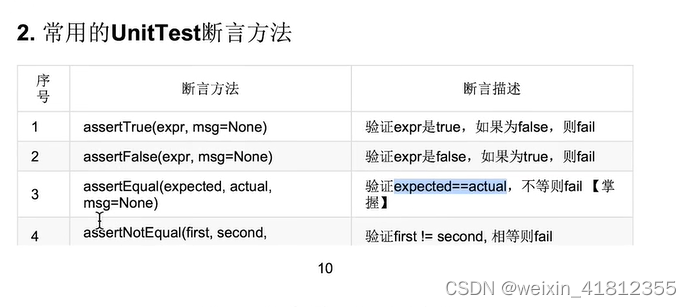
25 断言的使用


pycharm也可以导出测试结果:
26 参数化的介绍

参数化代码的步骤
1、导包unittest
2、定义测试类
3、书写方法(用到的测试使用变量代替)
4、组织册数数据并传参
27 跳过
对于一些未完成的或者不满足测试条件的测试函数和测试类,不想执行,可以使用跳过使用方法,装饰器完成
代码书写在testCase文件
#直接将测试函数标记成跳过
@unittest.skip('跳过原因')
#根据条件判断测试函数是否跳过,判断条件成立,跳过
@unittest.skipif(判断条件,'跳过原因

28、测试报告
自带的测试报告
只有单独运行TestCase的代码,才会生成测试报告
生成第三方的测试报告
1、获取第三方的测试运行类模块,将其放在代码的目录中
2、导包unittest
3、使用套件对象,加载对象去添加用例方法
4、实例化第三方的运行对象并运行套件对象
import unittest
# from MyTestCase1 import TestMyCase1
# from MyTestCase2 import TestMyCase2
# import MyTestCase3_Module
import os
from HTMLTestRunner import HTMLTestRunner
report_dir = "./testcase_01/"
report_file = report_dir + "report_cn.html"
# 判断reports目录是否存在,如果不存在就创建目录
if not os.path.exists(report_dir):
os.mkdir(report_dir)
with open(report_file, "wb") as fl:
module_path = "./"
discover = unittest.defaultTestLoader.discover(start_dir=module_path, pattern="testcase_01/test_*.py")
runner = HTMLTestRunner(title='测试标题', description='描述本次测试的大概内容', stream=fl)
runner.run(discover)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









