







欢迎来到我的文章
😊我是一个前端程序媛,会vue和一丢丢node,因为种种因素不是内卷😔,也不是工作所迫,决定主动开始学习后端,励志成为一名全栈程序媛✊,非常非常欢迎前端or后端or全栈的大佬们与我展开讨论💬,为我这只小菜鸡指明学习方向,彼此鼓励、持续前进、登上攻城狮之巅,用最少的头发换最多的money💴🤩!
目录
一. 数据类型
从最最最基础的数据类型开始。
和js类型,java也分为值类型和引用类型。
那么问题来了
[1]. 值类型和引用类型的区别是什么呢?
- 取用
(1)引用类型表示你操作的数据是同一个,也就是说当你传一个参数给另一个方法时,你在另一个方法中再去改变这个变量的值,那么调用这个方法的时候传入的变量的值也将改变;
(2)值类型表示复制一个当前变量传给方法,当你在这个方法中改变这个变量的值时,最初声明的变量的值不会变。 通俗说法:
(3)值类型就是现金,要用直接用;引用类型是存折,要用还得先去银行取现。- 传递
(1)在弄清楚值类型与引用类型之后,最后一点就是值传递与引用传递,这才是关键;
(2)基本数据类型赋值都属于值传递,值传递传递的是实实在在的变量值,是传递原参数的拷贝,值传递后,实参传递给形参的值,形参发生改变而不影响实参;
(3)引用类型之间赋值属于引用传递。引用传递传递的是对象的引用地址,也就是它的本身(自己最通俗的理解)。引用传递传的是地址,就是将实参的地址传递给形参,形参改变了,实参当然被改变了,因为他们指向相同的地址。引用和我们的指针差不多,但是它不又不需要我们去具体的操作。- 内存分配
(1)一个具有值类型(value type)的数据存放在栈内的一个变量中。即是在栈中分配内存空间,直接存储所包含的值,其值就代表数据本身,值类型的数据具有较快的存取速度;
(2)一个具有引用类型(reference type)的数据并不驻留在栈中,而是存储于堆中。即是在堆中分配内存空间,不直接存储所包含的值,而是指向所要存储的值,其值代表的是所指向的地址。当访问一个具有引用类型的数据时,需要到栈中检查变量的内容,该变量引用堆中的一个实际数据。引用类型的数据比值类型的数据具有更大的存储规模和较低的访问速度。

(一)JAVA
JAVA的数据类型用四个字概括就是:“四类八种”。
- 四类: 1、整型 ;2、浮点型; 3、字符型;4、逻辑型
- 八种:
1、整型3种 byte,short,int,long
2、浮点型2种 float,double
3、字符型1种 char
4、逻辑型1种 boolean
为了通俗易懂,来个表格!
| 类型 | 二进制位数 | 默认值 | 对应的封装类 | 取值范围 |
|---|---|---|---|---|
| byte | 8 | 0 | Byte | -128~127(-2的7次方到2的7次方-1) |
| short | 2 | 0 | Short | -32768~32767(-2的15次方到2的15次方-1) |
| int | 4 | 0 | Integer | (-2147483648~2147483647)(-2的31次方到2的31次方-1) |
| long | 8 | 0 | Long | (-9223372036854774808~9223372036854774807)(-2的63次方到2的63次方-1) |
| float | 4 | 0.0 | Float | 3.402823e+38 ~ 1.401298e-45 |
| double | 8 | 0.0 | Double | 1.797693e+308~ 4.9000000e-324 |
| char | 2 | 空格 | Character | – |
| boolean | 无 | false | Boolean | – |
(e+38表示是乘以10的38次方,同样,e-45表示乘以10的负45次方)
- 基本上int型的参数就已经可以满足日常编程需求了,在这里需要注意的是如果定义了一个long型的参数,就需要加一个L,float浮点数同理,例如:
long i=100L;//这里个人建议用大写的L,因为小写的l和1差不多,不易分辨 float f = 100F;//个人建议这里也大写,养成良好的编程习惯 char s='码'; - char是按照字符存储的,在代码中用引号,不管英文还是中文,固定占用占用2个字节,用来储存Unicode字符。范围在0-65536。
char可以存储中文,那个问题来了:
为什么char型的可以存储utf-8的字符呢?
首先,GBK的汉字是两个字节的,而utf-8是三个字节的。在java的内部存储中,都是以unicode为主,一个汉字转化为unicode是两个字节,当汉字进行存储后,java会把汉字转化成unicode编码,这样子就可以存储进去了。而utf-8,GBK只不是过外在软件的编码格式,并不是内部存储的格式。其实在存储汉字的时候,utf-16的效果要比utf-8优秀,因为utf-16只需要2byte的大小就行。 - 很多人会把String当成是java的基本类型之一,其实并不是。String是一个引用数据类型,是java中的一个类。String类型的参数用双引号表示。例如:
String s="12345"; - 除了四类八种基本类型外,所有的类型都称为引用类型, 如:字符串,类,接口,数组,枚举,注解,这里不过多介绍。
- java的八大数据类型都有对应的封装类
在实际编程中,基本使用的是基本数据类型来存储数据,这主要是因为如果用封装类,对于程序的开销就会变大,而这在实际中是完全没有必要的。
那为什么还要设置类呢?因为在java中,泛型类包含了预定义的集合,在这里使用的是对象类型,无法直接使用基本数据类型,所以定义了封装类,提供这些基本数据类型的包装容器。 而且封装类中提供了有用的方法,可以对进行数据的操作。这里不做过多介绍。 - 拆箱装箱(Autoboxing and unboxing)
举例:
可以粗浅的理解成,进行赋值的时候,根据定义参数的类型进行基本数据和包装类的自动转换。比如第一行,定义为integer类,后面为int值,就自动封装为integet类,值为100,拆箱也是,将integer类取值赋值给int的b。Integer a = 100; //这是自动装箱(编译器调用的是valueOf(int i)) int b = new Integer(100);// 这是自动拆箱
大致了解一下,具体详解大家可以看一下调用valueof方法的源码,可以发现integer的装箱会有点不同。这里便不详细解释了。
[2]. 如何获取java的数据的类型?
//使用obj.getClass().toString()
public class Int_String_Char {
public static void main(String[] args) {
byte a1=2;
short a2=2;
int a3=1;
long a4=2L;
System.out.println(getType(a1));
System.out.println(getType(a2));
System.out.println(getType(a3));
System.out.println(getType(a4));
float f=1.00f;
double d=1.00d;
System.out.println(getType(f));
System.out.println(getType(d));
boolean b=true;
System.out.println(getType(b));
char c='a';
System.out.println(getType(c));
String s="abc";
System.out.println(getType(s));
}
private static String getType(Object a) {
return a.getClass().toString();
}
}
(二)JS
- JS有六种原始类型和三种常用的引用类型,和java区别还是挺大的
原始类型:boolean;number;string;undefined;symbol;null;bigint
引用类型:对象、数组、函数// Symbol: let x = Symbol(12); // 输出x为symbol(12)而不是12且不等于12,主要用来表示独一的量 // bigint: let x = 123456789n; //在后面加n表示,可以表示任意大数 1n == 1, 1n !== 1 //true
[3]. 如何获取js的数据类型?
//typeof可以区分值类型,但是对于null会误判成Object
//typeof不可以区分引用类型数组和对象,但是可以辨别出function,因为函数非常特殊
console.log(typeof 10); //number
console.log(typeof '20'); //string
console.log(typeof true); //boolean
console.log(typeof unds); //undefined
console.log(typeof {a:1}); //object
console.log(typeof fn); //function
console.log(typeof null); //object
//typeof可以区分值类型,不可区分引用类型(函数除外),null也是object
//因为设计的时候`null`是全0,而对象是`000`开头,所以有这个误判。
那么,手写一个类型判断函数吧!
1.判断最特殊的null(typeof1判错)
2.用typeof判断基础的值类型和函数
3.使用Object.prototype.toString.call(target)来判断引用类型
/**
* 类型判断
*/
function getType(target) {
//先处理最特殊的Null
if(target === null) {
return 'null';
}
//判断是不是基础类型
const typeOfT = typeof target
if(typeOfT !== 'object') {
return typeOfT;
}
//肯定是引用类型了
const template =
"[object Object]": "object",
"[object Array]" : "array",
// 一些包装类型
"[object String]": "object - string",
"[object Number]": "object - number",
"[object Boolean]": "object - boolean"
};
const typeStr = Object.prototype.toString.call(target);
return template[typeStr];
}
var a = new String('string');
getType(a); //"object - string"
扩展,再来个判断数组类型的
//方法1
function isArray(t){
return Array.isArray(t)
}
//方法2
function isArray(t){
let type = Object.prototype.toString.call(t);
return (type === "[object Array]");
}
//方法3
function isArray(t){
return (t instanceof Array);
}
//方法4
function isArray(t){
return (t.__proto__.constructor === Array);
}
//测试
console.log(isArray([1,2,3])) //true
console.log(isArray(1,2,3)) //false
二. 类型转换
1、自动类型转化:
byte–>short–>int–>long–>float–>double(数值范围越来越大)
例如:
int a = 5;
long b=a;//这是成立的,反过来byte b=a;就不成立了,需要强制类型转化
2、强制类型转化:
例如:
int a = 8;
byte b=(byte)a;//强制类型转化是在参数前用括号加上数据类型进行转化
但是这种方法并不是全部情况都使用,需要看情况而定,因为这样子
1、会损失精度 ;
2、容易超出取值范围出错。
三. 操作运算符
java的运算符和JS差不多,这里介绍一些容易出错的
(一)操作符
java的操作符和其他的语言一致,加(+)减(-)乘(*)除(/)赋值(=)。在这里不多做阐述,主要讲的还是一些难以理解或者而比较绕的点,比如自加(++)【自减也一样】,优先级,还有逻辑运算符(&&和||),左移右移,==和equals方法的区别,
1. 自加(++)
++的使用和–一样,这里的话只以++为例子。一般此运算符的使用方法是这样的:a=b++,与之区别的是a=++b。我们知道a++的意思是a=a+1,那么放到赋值语句中有什么不同呢?
—> a=b++:
这类用法的含义是,先使用b,即先把b赋值给a,然后执行b=b+1;如果设立一个中间值temp,可以用代码表示如下:
temp = b ;
b = b + 1 ;
a = temp;
—> a=++b:
这类用法是,先对b进行自加,b=b+1,然后在进行赋值,a=b,可以用代码表示如下:
b = b + 1 ;
a = b;
这个时候不得不提一下一道面试题:
public static void main(String[] args) {
int i = 0;
for (int j = 0; j < 10; j++) {
i=i++;
}
System.out.println("i的结果是:"+i);
}
相信大家第一反应应该是i=10,但是i真的等于10吗,不妨我们把其中的i=i++按照上面简述的展开:
public static void main(String[] args) {
int i = 0; int temp =0;
for (int j = 0; j < 10; j++) {
//i=i++;
temp=i;i=i+1;i=temp;
}
System.out.println("i的结果是:"+i); //i结果是0
}
这下大家应该可以发现了,不管循环多少次,i的值都为0,这在笔试面试时经常会出现,算是java的一个自增陷阱。 其实java对该运算的处理也是这样的,会在内存中生成一个临时存储区,即temp来存储变量进行处理。
(二)优先级
java的运算符优先级,参照下表:
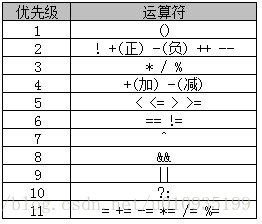
这里需要说明一点,强制类型转化的优先级比应该在1和2之间。例如:
float f = 1.7F;
int i = (int)f *2;//答案为2,而不是3,因为先进行强制类型转化,然后再乘,这里损失了精度
所以,在这里提醒大家在实际开发中,对于摸不准的,要善于运用括号啊
(三)逻辑运算符(&&和||)
看着这两个就想起&(与),|(或)和^(异或),这里就是转化为二进制按位进行操作,或者是boolean类型的对比,这里不详细讲解。
&&(短路与)和||(短路或)两侧加的是表达式,进行true和false的判断,遵循以下规则:
& 和 &&的区别
&:无论左边结果是什么,两边都参与运算
&&:当左边为false时,左边不参与运算
| 和 || 的区别
|:无论左边结果是什么,两边都参与运算
||:当左边为ture是,右边不参与运算
逻辑运算有异或,这里有一道题,怎么在不设置临时变量的情况下交换两个数的值,可以用^
public static void main(String[] args) {
int a = 1;
int b = 2;
System.out.println("a=" + a + ";b=" + b);
a = a ^ b;
b = a ^ b;
a = a ^ b;
System.out.println("a=" + a + ";b=" + b);
}
结果:
a=1;b=2
a=2;b=1
(四)左移右移
左移<< 就是n*2(位数) 实现2的次幂运算
右移>> 就是n/2(位数) 快速运算除以2的次幂
(>>:高位出现空位时,原高位时什么,就补什么)
(>>>:无论高位是什么,都补0(<<<也一样))
(五)==和equals方法的区别
先看一段代码:
public static void main(String[] args) {
int i = 1;
int j = 1;
Integer m = new Integer(1);
String a = "123";
String b = "123";
String c = new String("123");
String d = new String("123");
String st1 = "wasiker ";
String st2 = "is super man";
String st3 = "wasiker is super man";
String st4 = "wasiker is super man";
System.out.println(st1 == st2); //false
System.out.println((st1 + st2) == st3);//false
System.out.println(st3 == st4);//true
System.out.println(i == j);//true
System.out.println(i == m);//true
System.out.println(a == b);//true
System.out.println(c == d);//false
System.out.println(a == c);//false
System.out.println(m.equals(i));//true
System.out.println(a.equals(b));//true
System.out.println(c.equals(d));//true
System.out.println(a.equals(c));//true
}
可以总结:
1、==:如果两侧是基本数据类型,那么比较的是值(这里需要着重说明一下integer对象在==比较的时候,比如第17行,integer对象会自动拆箱变成int,进行值的比较,所以返回true);如果两侧是对象,那么比较的就是对象在内存中的地址
2、equals:比较的是两个对象的值是否相等,而不是比较地址
3、需要注意,String字符串想加的时候,会生成一个新的地址去指向结果,所以第14行比较的是地址,返回false。
四. 流程控制语句
这里简单讲解一下基本的流程控制语句,选择,循环等和其他语言一样,这里不多做介绍,讲一些容易出错的。
(一)for循环
在java中,除了for,还有一个增强型for循环,这是jdk5.0增加的新特性,下面介绍用法。foreach的主要格式为:
for(元素类型T 每次循环元素的名称O : 循环对象){
//对O进行操作
}
此类方法拥有不错的性能,主要是用在遍历数组、集合上,但是和for还是有点区别的。所有的foreach都可以转化为for语句,但是for语句并不是所有的都可以转化为foreach的格式。其实本质上foreach还是一个for循环。还是直接来看代码:
public static void main(String[] args) {
String[] test = { "1", "2", "3", "4", "5" };
for (String result : test) {
System.out.println(result);
}
}
结果:
1
2
3
4
5
其实简单一句话,就是对输入的test进行遍历,然后做相应操作,result就是每一次遍历test里面的元素。result前面的就是元素的类型,可以是基本数据类型,也可以是引用数据类型。
注意:
在循环遍历的过程中,不能对数组进行增加删除操作,不然就会产生java.util.ConcurrentModificationException。原因简单说一下,就是foreach的内部实现是以iterator迭代器实现的,在开始前会有一个count的大小统计,如果更改了遍历元素的size,会使得count的值发生变化,从而报错。有兴趣的同学可以去看一些foreach的具体实现以及iterator的源码。还有一个很有意思的就是这个错误也不是一定会出现的,这就留给同学们自己去发现了,这里不做阐述。
个人建议,如果要遍历数组或者集合,还是直接用iterator比较好。
(二)三目运算符
java中的三目运算符,一般形式为 表达式1?表达式2:表达式3;化成if-else语句的话,就是:
if(表达式1)
表达式2;
else
表达式3;
看到这里,其实这个三目表达式很好理解,就是一个简化的选择语句嘛,那为什么要拿出来呢,因为他的结合方向。
在面试或者笔试的时候我们会遇到这样的题目:
public static void main(String[] args) {
int a = 1, b = 2, i = 3, j = 4;
System.out.println(a > b ? a : i > j ? i : j); //答案是4
}
一看到这样的题目的时候可能会懵,不过要知道,三目运算符的结合性是从右至左,就是说,在遇到相同优先级的运算中(java中三目运算符的优先级相同的只有它自己),最右边的先进行运算,然后再是左边的,所以,其实a > b ? a : i > j ? i : j也可以看做是a > b ? a 😦 i > j ? i : j)。所以,上题的答案是4,在实际开发中,为了避免这种会让自己懵的情况发生,要善于利用括号!
这里再看一道题目,或许在笔试的时候会碰到:
public static void main(String[] args) {
int a = 1, b = 1;
System.out.println(--a == b++ ? a++ : b++);//答案是2
int m = 1, n = 0;
System.out.println(--m == n++ ? m++ : n++);//答案是0
}
总结:
仔细推敲一下,可以发现==,++,三目的优先级应该是++ > == > 三目,所以第一个运算判断条件应该是(a=0)是否和b相等,不相等那就是(b++),这时候要注意++的运算,是先使用后自加,所以输出b,那为什么是2呢,因为在前面判断的时候b++了一次,所以为2。看了解释还迷糊的同学可以转化成if-else的语句形式,就明了了,这里不再作解释。同理分析第二个运算,可以得到答案是0。















 6657
6657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









