






接续 Caffeine Cache解析(一):接口设计与TinyLFU
final ConcurrentHashMap<Object, Node<K, V>> data;
数据最终都会被存储在该字段,其中的key的Object可能是强引用或弱引用,统一通过final NodeFactory<K, V> nodeFactory字段的
nodeFactory.newLookupKey(key)方式获取:
- cache定义key为强引用时:
newLookupKey返回的即为用户输入key - cache定义key为弱引用时:
newLookupKey返回LookupKeyReference
但page replacement policy(即admission policy + evict policy)的执行并不根据data这个字段判断,而是通过另外两个字段:
MpscGrowableArrayQueue<Runnable> writeBuffer: 每次afterWrite会同时写入Buffer<Node<K, V>> readBuffer: 每次afterRead会同时写入
这样page replacement policy不会阻塞主线程操作。
The page replacement algorithms are kept eventually consistent with the map
可以看到buffers中内容和data的内容是最终一致的,即data中即使存在Node也不一定能用(可能已经过期/待被evict)。
只有当data中和page replacement algorithms都有该Node时,才算cache中包含该Node。
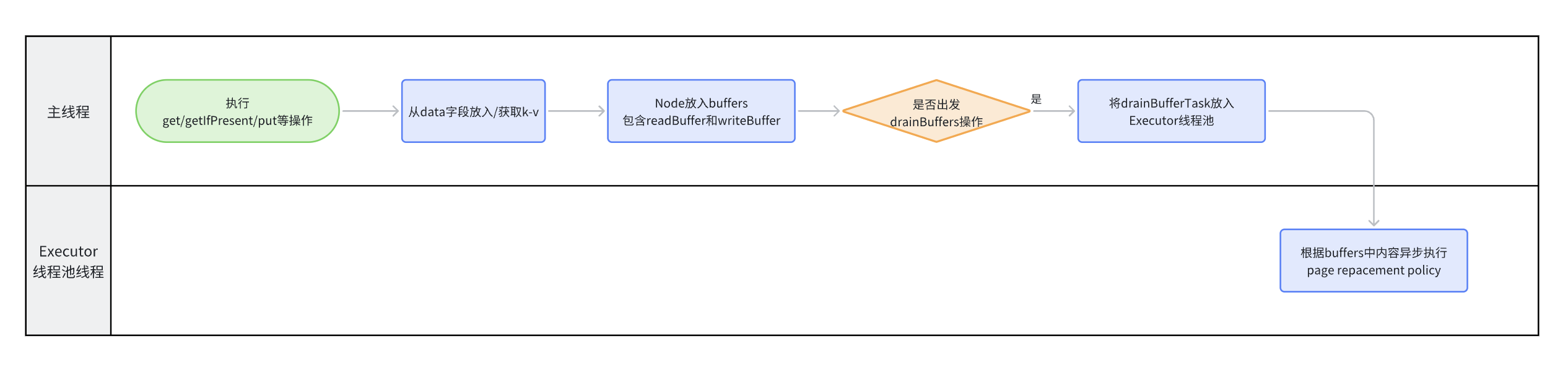
那么何时触发 page replacement algorithms(即drain buffers)呢?
These buffers are drained(只是放入Executor线程池,异步drain,通过加锁和cas操作完成)
at the first opportunity after a write or when a read buffer is full
大致调用如下:
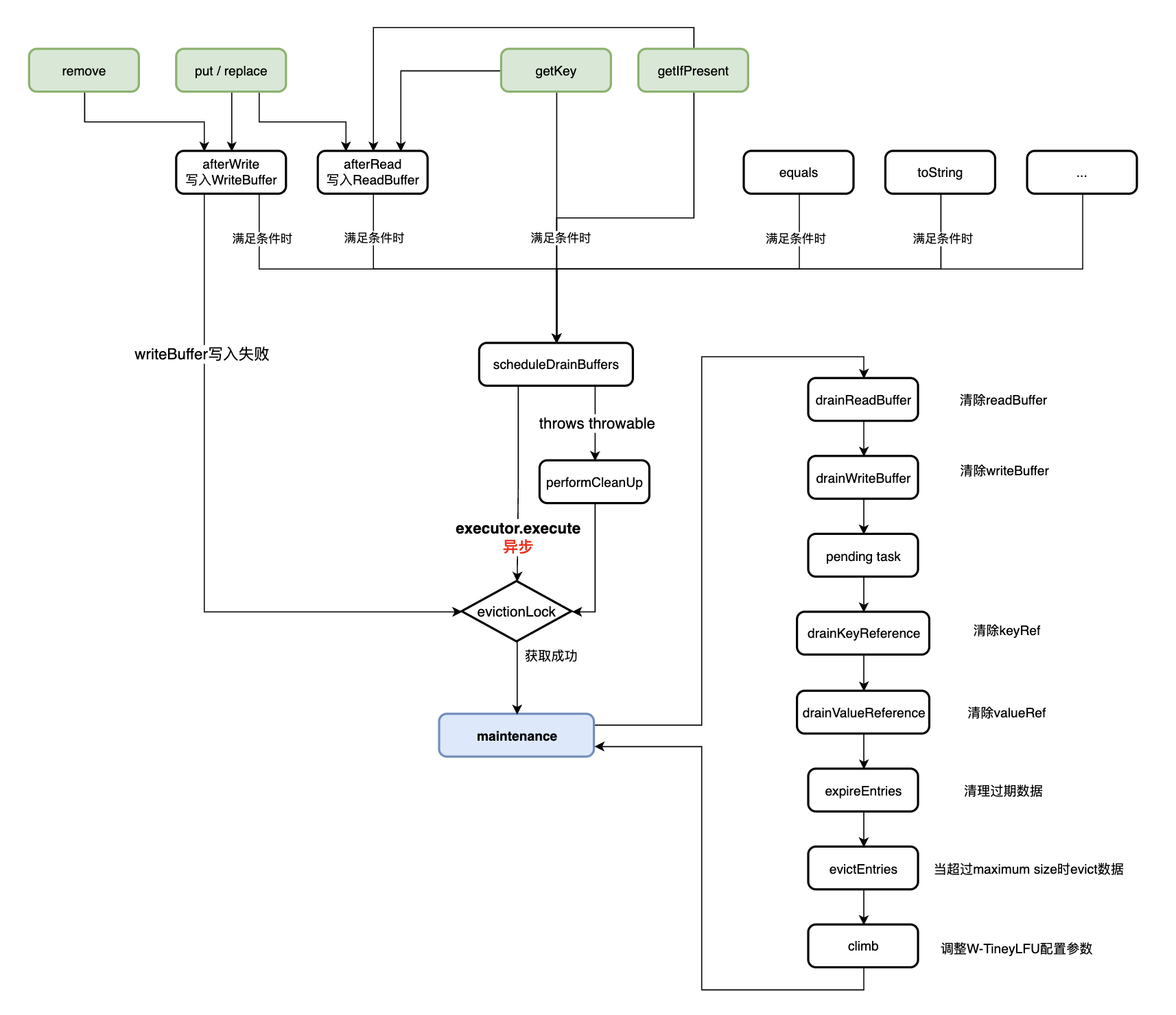
既然是多线程,肯定有并发控制,Caffeine通过java.util.concurrent.locks.ReentrantLock以及CAS操作Drain的状态机来控制并发。
每次执行maintenance方法时都会先获取ReentrantLock;此外,有些场景可以直接cas设置状态就不需要加锁了,Drain的状态共有4种: IDLE , REQUIRED , PROCESSING_TO_IDLE , PROCESSING_TO_REQUIRED . Drain的状态统一由BoundedLocalCache的父抽象类DrainStatusRef管理,由于涉及多线程修改,该抽象类继承了PadDrainStatus来防止伪共享(false sharing)。
抽象类DrainStatusRef中使用一个volatile int drainStatus字段来记录状态,volatile保证字段变更时的内存可见性。
但DrainStatusRef并不直接操作该字段,
而是通过抽象类DrainStatusRef的static final VarHandle DRAIN_STATUS字段来操作drainStatus,其类型为java.lang.invoke.VarHandle。
abstract static class DrainStatusRef extends PadDrainStatus {
static final VarHandle DRAIN_STATUS;
...
/** The draining status of the buffers. */
volatile int drainStatus = ...;
int drainStatusOpaque() {
return (int) DRAIN_STATUS.getOpaque(this);
}
int drainStatusAcquire() {
return (int) DRAIN_STATUS.getAcquire(this);
}
void setDrainStatusOpaque(int drainStatus) {
DRAIN_STATUS.setOpaque(this, drainStatus);
}
void setDrainStatusRelease(int drainStatus) {
DRAIN_STATUS.setRelease(this, drainStatus);
}
boolean casDrainStatus(int expect, int update) {
return DRAIN_STATUS.compareAndSet(this, expect, update);
}
static {
try {
DRAIN_STATUS = MethodHandles.lookup()
.findVarHandle(DrainStatusRef.class, "drainStatus", int.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
}
}
为什么通过java.lang.invoke.VarHandle的变量句柄来操作呢?为了保证多线程修改状态时的状态字段内存可见性。
VarHandle支持5中操作类型(参见VarHandle内部枚举AccessType):
- GET
- SET
- COMPARE_AND_SET
- COMPARE_AND_EXCHANGE
- GET_AND_UPDATE
Access modes control atomicity and consistency properties.
为了保证变量操作的原子性和内存一致性,又有以下5种AccessMode根据严格程度从弱到强为:
- plain: 即普通的get/set, 存在指令重排,不保证内存可见性
- opaque: 当前线程不存在指令重排(不通过内存屏障实现),但不保证其他线程
- acquire/release: getAcquire-后续的load & store不会重排序到当前操作前 ; setRelease-前面的load & store 不会重排序到当前操作后
- volatile: 和volatile关键字效果一样
关于volatile关键字的重排序规则如下:
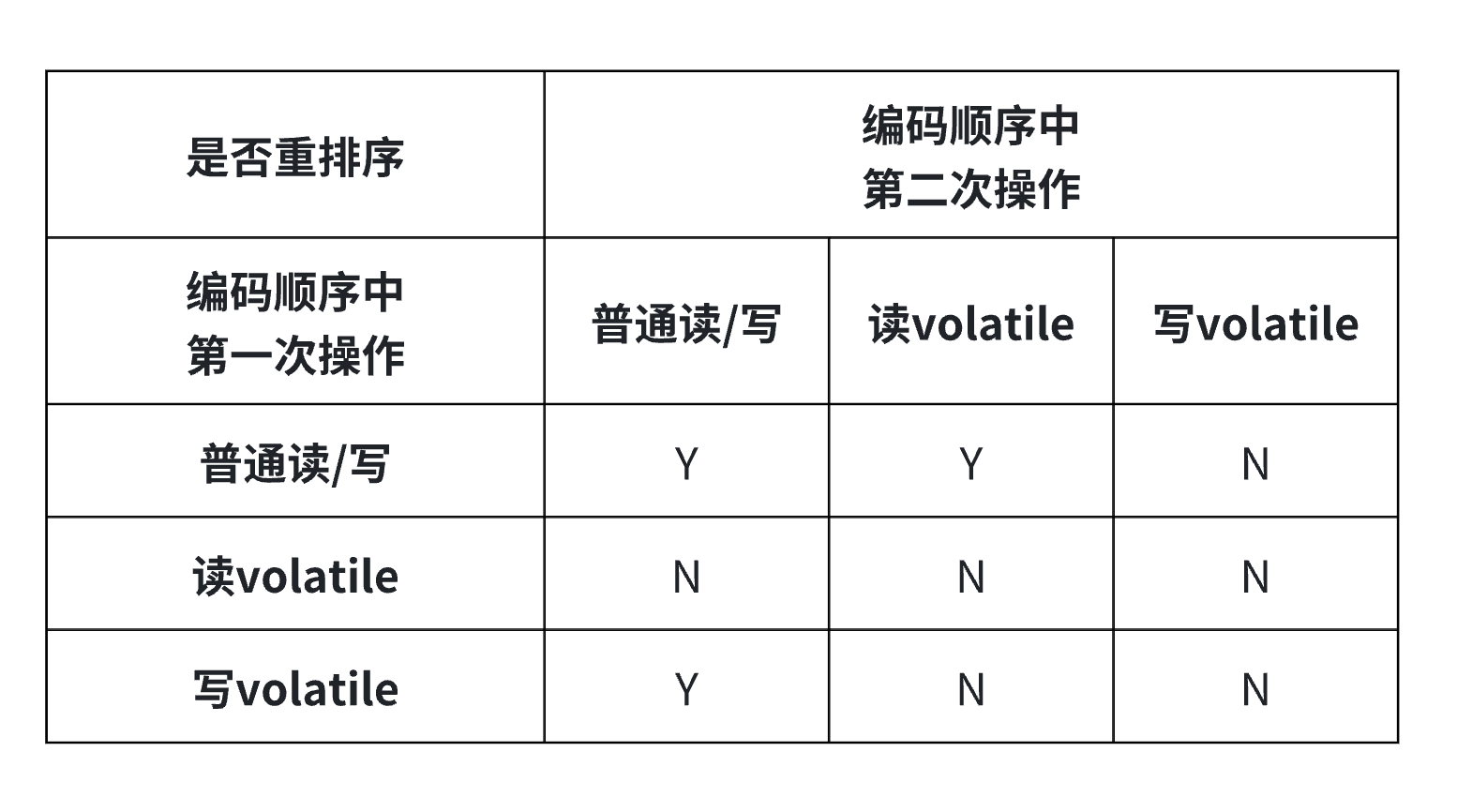
需要指出的是,只有单线程情况下不影响执行结果时才有可能发生指令重排序,
而以上需要防止重排序产生的内存可见性问题,是基于多核处理器并发执行的场景。
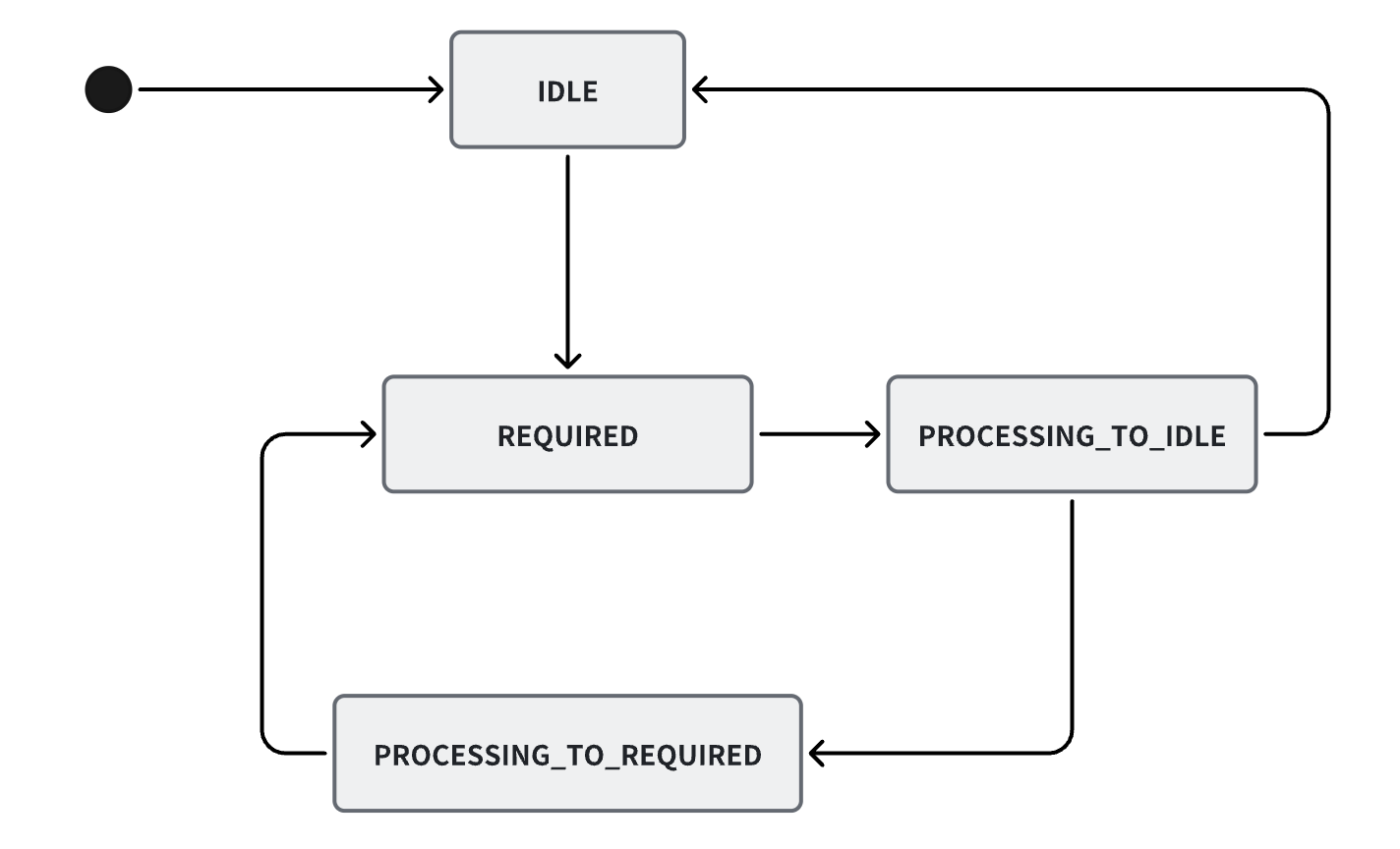
说回drainStatus,drainStatus有一下4个:
- IDLE(0): 不需要执行drainBuffers
- REQUIRED(1): 需要执行drainBuffers
- PROCESSING_TO_IDLE(2): drainBuffers异步任务提交前设置,下一个状态会是IDLE(实际不一定,也会流转到PROCESSING_TO_REQUIRED)
- PROCESSING_TO_REQUIRED(3): drainBuffers正在执行但此时又有drain任务提交,则后续还要继续触发drain,下一个状态会是REQUIRED
其状态机如下图:
如前文所述,每次write(包含writeBuffer满了的情况)或readBuffer满了就会触发drainBuffers操作,那么代码中这两处是如何流转drainStatus呢?
// 当buffers满了触发
void scheduleDrainBuffers() {
// 已经有触发后续drain了即为PROCESSING_TO_REQUIRED,则直接返回
if (drainStatusOpaque() >= PROCESSING_TO_IDLE) {
return;
}
// 加锁
if (evictionLock.tryLock()) {
try {
int drainStatus = drainStatusOpaque();
// 二次判断:已经有触发后续drain了即为PROCESSING_TO_REQUIRED,则直接返回
if (drainStatus >= PROCESSING_TO_IDLE) {
return;
}
// drain提上日程
setDrainStatusRelease(PROCESSING_TO_IDLE);
// 提交task
executor.execute(drainBuffersTask);
} catch (Throwable t) {
logger.log(Level.WARNING, "Exception thrown when submitting maintenance task", t);
maintenance(/* ignored */ null);
} finally {
evictionLock.unlock();
}
}
}
// write后插入writeBuffer成功后执行
void scheduleAfterWrite() {
@Var int drainStatus = drainStatusOpaque();
for (;;) {
switch (drainStatus) {
case IDLE:
// 设置为需要drain
casDrainStatus(IDLE, REQUIRED);
// 提交drain task
scheduleDrainBuffers();
return;
case REQUIRED:
// 提交drain task
scheduleDrainBuffers();
return;
case PROCESSING_TO_IDLE:
// 到这里说明前面有其他线程提交了drain task
// 则这里cas设置为PROCESSING_TO_REQUIRED
if (casDrainStatus(PROCESSING_TO_IDLE, PROCESSING_TO_REQUIRED)) {
return;
}
// cas失败说明status不是PROCESSING_TO_IDLE,那就更新当前局部变量的drainStatus
drainStatus = drainStatusAcquire();
continue;
case PROCESSING_TO_REQUIRED:
return;
default:
throw new IllegalStateException("Invalid drain status: " + drainStatus);
}
}
}
// 加完锁执行drainBuffers等操作
@GuardedBy("evictionLock")
void maintenance(@Nullable Runnable task) {
setDrainStatusRelease(PROCESSING_TO_IDLE);
try {
...
} finally {
// 当前状态不是 PROCESSING_TO_IDLE ,则一定为 PROCESSING_TO_REQUIRED,说明还要drain一次,则状态变为REQUIRED
if ((drainStatusOpaque() != PROCESSING_TO_IDLE)
// cas设置为IDLE,失败了也变成REQUIRED(可能前面判断和这次判断中间有其他线程改为PROCESSING_TO_REQUIRED了)
|| !casDrainStatus(PROCESSING_TO_IDLE, IDLE)) {
setDrainStatusOpaque(REQUIRED);
}
}
}
上面的多线程任务提交状态流转的考量,在我们的业务应用中也可以借鉴,所以说读源码才是王道!


















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











